How I built an affiliate tracking system in a weekend with serverless
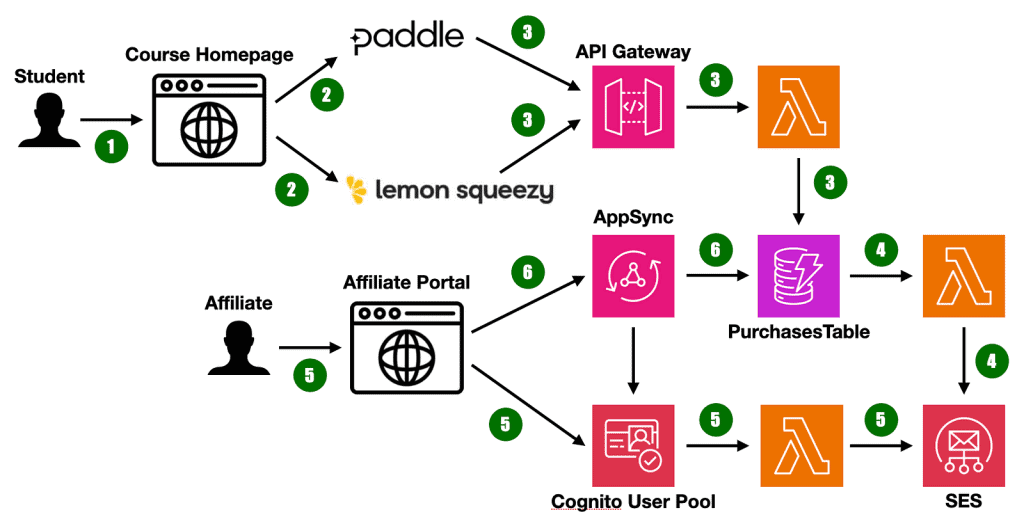
Having taught thousands of students to build serverless applications via my online courses and workshops, I felt it was time to kick-start an affiliate program to boost sales. Affiliates would receive 50% of the revenue and get a 15% discount code for their audience. It feels like a good deal but I would need a …
How I built an affiliate tracking system in a weekend with serverless Read More »