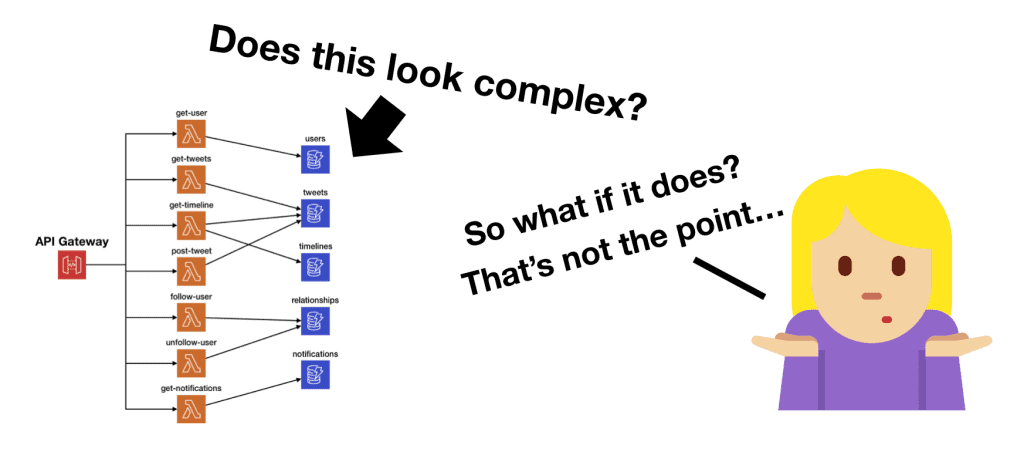
“Even simple serverless applications have complex architecture diagrams”, so what?
A common complaint I have heard about serverless applications is that they tend to look really complicated on architecture diagrams, with many moving parts. But does it mean serverless applications are more complex compared to their serverful counterparts? Before I get to that, let’s do a simple exercise. Serverful architectures Which of these two serverful …
“Even simple serverless applications have complex architecture diagrams”, so what? Read More »