

Yan Cui
I help clients go faster for less using serverless technologies.
Update 07/04/2023: Since I originally wrote this post, my preference has shifted to using SSM Parameter Store to share information between Terraform and the Serverless framework. This is preferable because:
- The Serverless Framework has built-in support for reading data from SSM, with the ${ssm:/path/to/param} syntax.
- CloudFormation is used to provision resources, using it as a container for outputs is a misuse of CloudFormation.
- Creating an SSM parameter is easier than a CloudFormation stack.
- SSM supports SecretString, so you can use it to share sensitive data that should be encrypted at rest, e.g. API keys.
But you might ask “What about Secrets Manager instead of SSM?”. That is an option, but personally, I still prefer to use SSM Parameter Store over Secrets Manager in most cases, and here’s why.
—–
The Serverless framework is the most popular deployment framework for serverless applications. It gives you a convenient abstraction over CloudFormation and some best practices out-of-the-box:
- Filters out dev dependencies for Node.js function.
- Update deployment packages to S3, which lets you work around the default 50MB limit on deployment packages.
- Enforces a consistent naming convention for functions and APIs.
But our serverless applications is not only about Lambda functions. We often have to deal with share resources such as VPCs, SQS queues and RDS databases. For example, you might have a centralised Kinesis stream to capture all applications events in the system. In this case, the stream doesn’t belong to any one project and shouldn’t be tied to their deployment cycles.
You still need to follow the principle of Infrastructure as Code:
- version control changes to these shared resources, and
- ensure they can be deployed in a consistent way to different environments
You can still use the Serverless framework to manage these shared resources. It is an abstraction layer over CloudFormation after all. Even without Lambda functions, you can configure AWS resources using normal CloudFormation syntax in YAML.
But this is often frowned upon by DevOps/infrastructure teams. Perhaps the name “Serverless” makes one assume it’s only for deploying serverless applications. On the other hand, Terraform is immensely popular in the DevOps space and enjoys a cult-like following.
I see many teams use both Terraform and Serverless framework in their stack:
- Serverless framework to deploy Lambda functions and their event sources (API Gateway, etc.).
- Terraform to deploy shared dependencies such as VPCs and RDS databases.
The Serverless framework translates your serverless.yml into a CloudFormation stack during deployment. It also lets you reference outputs from another CloudFormation stack. But there’s no built-in support to reference Terraform state. So there is no easy way to reference the shared resources that are managed by Terraform.


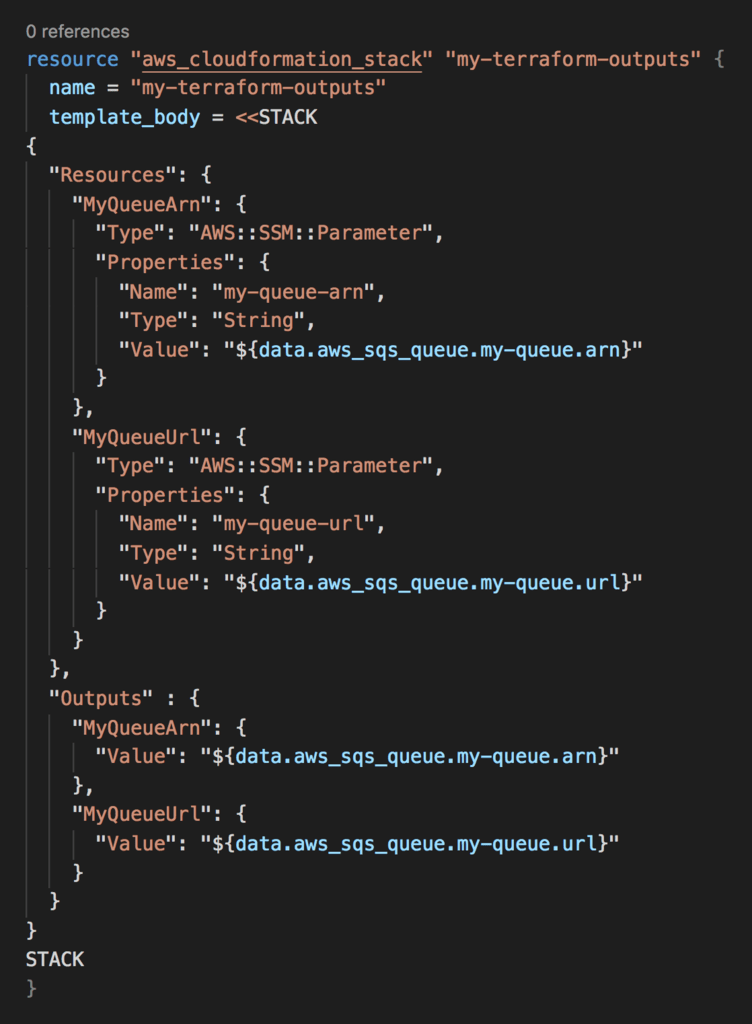
Here at DAZN we have used a simple trick to make Serverless framework and Terraform work together. Reading the Terraform state from the Serverless framework is tricky. So, we cheat ;-)
We would create a CloudFormation stack as part of every Terraform script. This CloudFormation stack would hold the output from the resources that Terraform creates?—?ARNs, etc. We would then be able to reference them from our serverless.yml files.
Let’s look at a simple example.
Example
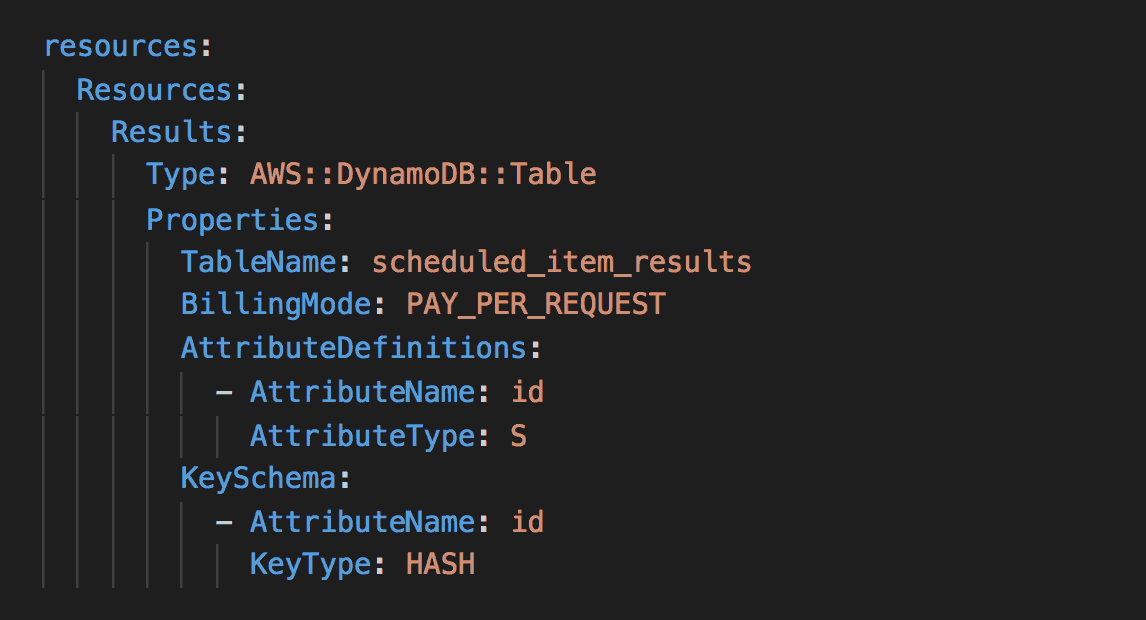
Here’s a simple Terraform script that provisions a SQS queue.

To export the ARN and URL of this queue, we need to add a CloudFormation Stack to our script. Notice that the stack specifies the outputs MyQueueArn and MyQueueUrl. This is all we wanted to do here. But unfortunately, CloudFormation requires you to specify at least one resource…
Since the stack is here to provide outputs for others to reference, let’s stay with that theme. Let’s expose the SQS attributes as SSM parameters as well.
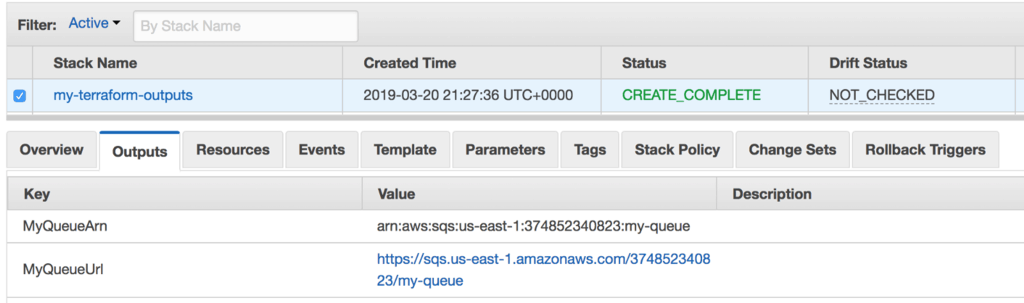
After you run terraform plan and terraform apply you will be able to find the my-terraform-outputs stack in CloudFormation. You will find the URL and ARN for the SQS queue in this stack’s output.
From here, we can reference these outputs from a serverless.yml file.
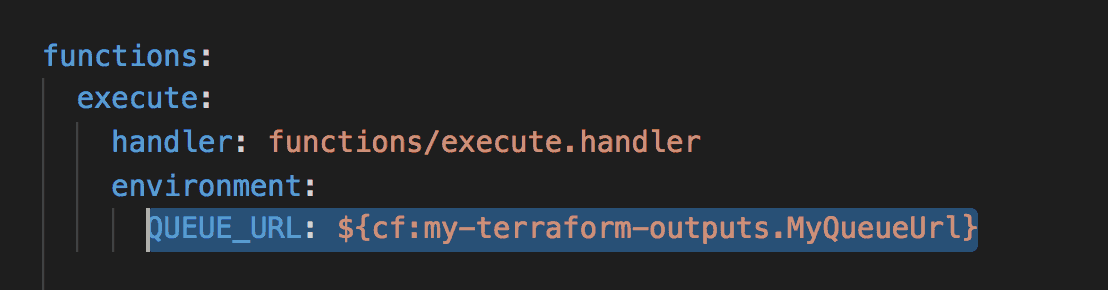
Since our stack also created SSM parameters for these outputs, we can also reference them from SSM Parameter Store too.
Alternatives
The Serverless framework lets you reference variables from a number of AWS services:
- Another CloudFormation stack’s output.
- A JSON file in S3.
- SSM Parameter Store.
- Secrets Manager.
So you don’t have to use CloudFormation as a way to store outputs from Terraform. Which as you can see, forces you to also provision some resources via CloudFormation…
Assuming we’re not talking about application secrets (which, is a whole separate topic) you should consider outputting them to SSM parameters instead.
Whenever you’re ready, here are 4 ways I can help you:
- If you want a one-stop shop to help you quickly level up your serverless skills, you should check out my Production-Ready Serverless workshop. Over 20 AWS Heroes & Community Builders have passed through this workshop, plus 1000+ students from the likes of AWS, LEGO, Booking, HBO and Siemens.
- If you want to learn how to test serverless applications without all the pain and hassle, you should check out my latest course, Testing Serverless Architectures.
- If you’re a manager or founder and want to help your team move faster and build better software, then check out my consulting services.
- If you just want to hang out, talk serverless, or ask for help, then you should join my FREE Community.