
Yan Cui
I help clients go faster for less using serverless technologies.
When working with CloudFormation, AWS recommends not to give explicit names to resources and let CloudFormation name them for you. This has several advantages:
- It’s harder for attackers to guess resource names such as S3 buckets or DynamoDB tables.
- You can deploy the same stack multiple times to the same account. This is useful when you use temporary stacks for developing feature branches or for running end-to-end tests in your CI pipeline.
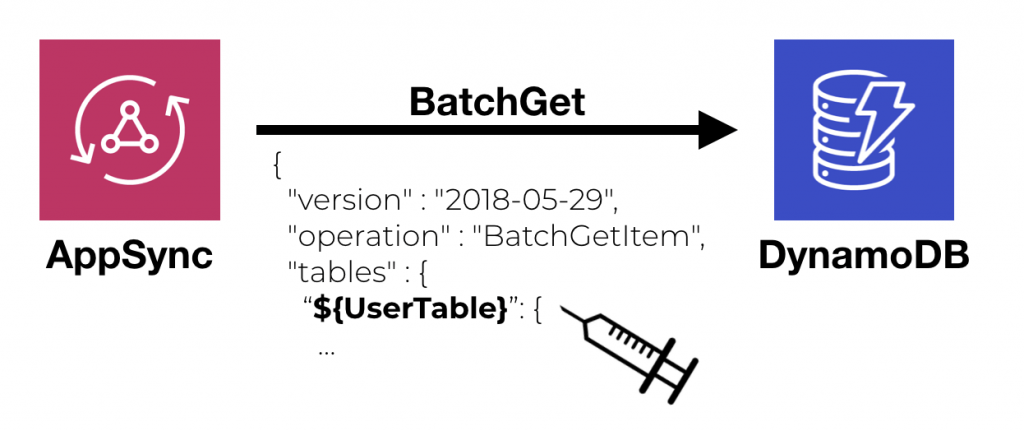
However, this makes it harder for you to use AppSync’s batch or transact DynamoDB operations.

I had this exact problem on a recent project where I built the backend of a new social network in AppSync.
One way to get around this problem is to introduce some external build step to transform the VTL templates.
Alternative, you can also wrap the RequestTemplate and ResponseTemplate in a Fn::Sub so you can reference the DynamoDB tables’ logical IDs in the VTL templates themselves.
On this project, I used the Serverless framework with the excellent serverless-appsync-plugin. I didn’t want to introduce an extra build step to my CI pipeline so I chose the 2nd approach.
Since the resolvers and pipeline functions are generated by the serverless-appsync-plugin, I couldn’t wrap them in a Fn::Sub directly. But, as is so often the case, the solution is to create a Serverless framework plugin to manipulate the generated CloudFormation.
Update 22/07/2020: Thanks to reader Owain McGuire for pointing out that the serverless-appsync-plugin has a built-in substitutions features which does this out-of-the-box, so you don’t need to write your own plugin after all. Somehow I managed to miss this completely :-/
Anyhow, to do this, you need to define a substitutions attribute under custom.appsynclike this:
substitutions: userTableName: !Ref UserTable
You will be able to reference this as ${userTableName} in your VTL templates.

In this case, I created a local plugin called VtlPseudoParameters as below.
class VtlPseudoParameters {
constructor (serverless, options) {
this.serverless = serverless
this.log = (msg, ...args) => serverless.cli.consoleLog(`vtl-pseudo-parameters: ${msg}`, ...args)
// the serverless-appsync-plugin uses this hook
// after:aws:package:finalize:mergeCustomProviderResources
// so we have to, too, but after it runs
this.hooks = {
'after:aws:package:finalize:mergeCustomProviderResources': this.transform.bind(this)
}
}
transform () {
const cfTemplate = this.serverless.service.provider.compiledCloudFormationTemplate
const resources = Object
.values(cfTemplate.Resources)
.filter(x =>
x.Type === 'AWS::AppSync::Resolver' ||
x.Type === 'AWS::AppSync::FunctionConfiguration')
resources.forEach(resource => {
let identifier
switch (resource.Type) {
case 'AWS::AppSync::Resolver':
const { TypeName, FieldName } = resource.Properties
identifier = `[Resolver:${TypeName}.${FieldName}]`
break
case 'AWS::AppSync::FunctionConfiguration':
const { Name } = resource.Properties
identifier = `[Function:${Name}]`
break
default:
this.log('unsupported resource type:', resource.Type)
}
if (resource.Properties.RequestMappingTemplate.includes('${')) {
this.log(`transforming request template for [${identifier}]...`)
resource.Properties.RequestMappingTemplate = {
'Fn::Sub': resource.Properties.RequestMappingTemplate
}
}
if (resource.Properties.ResponseMappingTemplate.includes('${')) {
this.log(`transforming response template for [${identifier}]...`)
resource.Properties.ResponseMappingTemplate = {
'Fn::Sub': resource.Properties.ResponseMappingTemplate
}
}
})
}
}
module.exports = VtlPseudoParameters
And added it to the list of plugins for the project.
plugins: - serverless-appsync-plugin - vtl-pseudo-parameters - serverless-plugin-split-stacks
However, this project is non-trivial. It had ~150 resolvers amidst a total of ~500 CloudFormation resources. To mitigate the 200 resources limit on CloudFormation, I also use the serverless-plugin-split-stacks to split the main stack into several nested stacks.
So, the local plugin needs to run AFTER the serverless-appsync-plugin, but BEFORE the serverless-plugin-split-stacks splits up the stack. Which is why its position in the plugins list matters. Also, it needs to transform the generated CloudFormation template on the same hook that both serverless-appsync-plugin and serverless-plugin-split-stacks uses.
With the help of this simple plugin, I can reference the logical ID of my DynamoDB table and CloudFormation would take care of substituting them to the generated table names.
#if ($context.source.participants.size() == 0)
#return([])
#end
#set( $users = [] )
#foreach( $participant in $context.source.participants )
#set ( $user = {})
#set ( $user.id = $participant.userId )
$util.qr($users.add($util.dynamodb.toMapValues($user)))
#end
{
"version": "2018-05-29",
"operation": "BatchGetItem",
"tables": {
"${UserTable}": {
"keys": $util.toJson($users),
"consistentRead": false
}
}
}
$util.toJson($context.result.data.${UserTable})
A word of warning though. This is a quick fix. The reason I didn’t publish this as an NPM package is that it can’t function as a standalone plugin. Not only does it depend on the serverless-appsync-plugin, but it also needs to be positioned after the serverless-appsync-plugin in the plugins array.
The right thing to do here is to incorporate this behaviour into the serverless-appsync-plugin plugin itself. Unfortunately, I haven’t had the time to look into it and create the PR myself. If you’re reading and you’re able to do that, then please go ahead and create the PR in my stead. Otherwise, I’ll get to it when I have a moment.
In the meantime, this is a bandaid that makes DynamoDB batch and transact operations a little easier to work with in AppSync.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game.
- Consulting: If you want to improve feature velocity, reduce costs, and make your systems more scalable, secure, and resilient, then let’s work together and make it happen.
- Join my FREE Community on Skool, where you can ask for help, share your success stories and hang out with me and other like-minded people without all the negativity from social media.