
Yan Cui
I help clients go faster for less using serverless technologies.

In enterprises we tend to sell architectural projects by showing you the current messy state and pitch you an idealized end state. But the problem is that, the ideal end state we’re pitching exists only as an idea, without having gone through all the compromises and organic growth that made the current state messy.
Once we have gone through the process of implementing and growing the system over the course of its lifetime, how do we know we won’t end up in the same messy situation again?

The 3-year Plans
Worse still, these pitches are always followed by a 3 year plan where you see no return on your investment for 2 whole years!
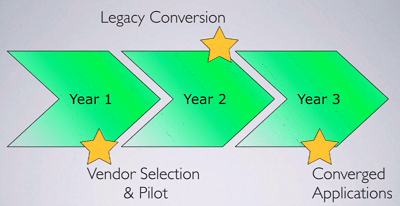
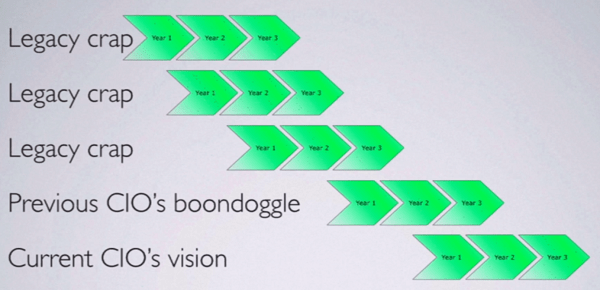
And since 3 years is a long time, many things can happen along the way – mergers, acquisitions, new technologies, new CTO/CIO, etc. – and often we don’t ever realize the original 3 year plan before these forces of change takes us to a new direction.
And the vicious cycle continues….
Within a large organization there are always multiple forces of change happening at the same time, and your perspective changes depending on your position within the organization.
In a complex sociotechnical system like this, there’s no privileged vantage point. One person cannot understand all ramifications of their decisions, not even the CEO of a company.
The best you can do, is locally contextual actions.
8 Rules for Survival
1. Embrace plurality
Avoid tendency for the “one”, e.g.
- single source of truth;
- single system of record;
- one system to rule them all;
- etc.
The problem with having a single system of records (SSOR) is that it’s terribly fragile. Many real-world events (e.g. M&A, divestitures, entering new market) can easily violate your pursuit for the “one” system.
In epistemology (i.e. the study of “how we know what we know”), there’s the idea that we can only know what we are able to record in a system. If your SSOR is badly shaped for the information that exist, you might be unaware of the rest of the instances of information you’re looking for.
When modelling a domain, sometimes it’s even tough to find “one” definition for something that everyone can agree on.
For example, a “customer” can mean different things to different departments:
- for customer service, a customer is someone who is paying you money
- for sales, someone is a customer as soon as you start talking to them
Finally, there’s this philosophical idea that, the model you use to view the world shapes the thoughts you are able to think.
Your paradigm defines the questions you can ask.

I think this also applies to programming languages and paradigms, with the same detrimental effects in limiting our potential as creative problem solvers. And it’s a good reason why you should learn at least a few programming paradigms in order to expand your mind.
When dealing with multiple systems of records, we change our emphasis and instead focus on:
- who’s the authority for what span?
- define a system to find the authority for a span given some unique identifier, e.g. URIs, URNs (AWS’s ARN system springs to mind)
- agreeing on a representation so we can interchange them across different systems
- enable copies and have a mechanism for synchronization
Something interesting happens when you do these – your information consumers no longer assume where the information comes from.
If you provide full URLs with your product details, then the consumers can go to any of the URLs for your product information. They must become more flexible and assume there is an open world of information out there.
Along with the information you get, you also need a mechanism for determining what actions you can perform with them. These actions can be encoded as URLs and may point to different services.
As I listened, two words sprang to mind:
microservices – breaking up a big, complex system into smaller parts each with authority over its own span; information is accessed through a system of identifiers and an agreed-upon format for interchange (rather than shared database, etc.)
HATEOAS – or REST APIs in the way Roy Fielding originally described; actions permitted on information is pass back alongside the information itself and encoded as URLs
2. Contextualize Downstream
We have a tendency to put too much in the data we send downstream, which can often end up being a very large set.
But our business rules are usually contextual:
- not all information about an entity is required in every case
- operations are not available across entire classes of entities
Again, HATEOAS strikes me as a particularly good fit here for contextualizing the data we send to downstream systems.
We build systems as a network of data-flows, but we also need to look at the ecosystem of system of systems and be aware of the downstream impacts of our changes.
Something like the following is obviously not desirable!
So the rule is:
- Augment the data upstream, add fields but not relationships if you can avoid it.
- Contextualize downstream, apply your business rules as close to the user as possible. Because as it turns out, the rules that are closest to the users change the most often.
- Minimize the entities that all systems need to know about.
3. Beware Grandiosity
Fight the temptation to build the model to end all models (again, embrace plurality), aka Enterprise Modelling Dictionary.
The problem with an Enterprise Modelling project is that, it requires:
- a global perspective, which we already said is not available in a complex system;
- agreement across all business units, which is extraordinarily hard to achieve;
- talent for abstraction; but also
- concrete experience in all contexts;
- a small enough team to make decisions.
Such teams only exist in Hollywood movies..

Instead, look to how standard committees work:
- they compromises a lot;
- they don’t seek agreements across the board, and instead agree on small subsets and leave room for vendor ventures;
- they take a long time to converge
- they deliberately limit their scope
“All models are wrong, but some are useful.”
– George Box
So the rule is:
- don’t try to model the whole world;
- find compromises and subsets that everyone can agree on;
- start small and incrementally expand;
- assume you don’t know everything and leave room for extension;
- allow very lengthy comment period (with plenty of email reminders since everyone leaves it till the last minute..
 )
)
4. Decentralize
Decentralization allows more exploration of market space because it allows multiple groups to work on different things at once.
You can also explore the solution space better because different groups can try different solutions for similar problems.
However, you do need some prerequisites for this to work successfully:
- Transparency – methods, work and results must be visible
- Isolation – one group’s failure cannot cause widespread damage
- Economics – create a framework for everyone to make decisions that contribute towards the larger goal
The Boeing 777 project is an excellent example of distributed economic decision-making.
The no. 1 thing that determines a plane’s lifetime cost is the weight of the aircraft. So the weight of the aircraft is in direct trade-off with cost (e.g. lighter materials = more expensive manufacturing cost).
They worked out what the trade-off was and set out rules so that an engineer can buy a pound of weight for $300 – i.e. as an engineer, you can make a decision that’ll shave a pound of weight off the aircraft at the expense of $300 of manufacturing cost without asking anybody.
Engineering and programme managers and above have a bigger manufacturing cost budge per pound, and anything above these predefined limits requires you to go before the governance board and justice your decisions.
What they have done is setting the trade-off policies centrally and by defining the balancing forces globally they have created a framework that allows decisions to be made locally without requiring reviews.
In IT, Michael has observed that centralization tends to lead to budget fights between departments. Whereas decentralization allows for slivers of budgets working towards a common goal.
5. Isolate Failure Domains
If you reverse the direction data flows through your systems and you can find the direction of dependencies between them.
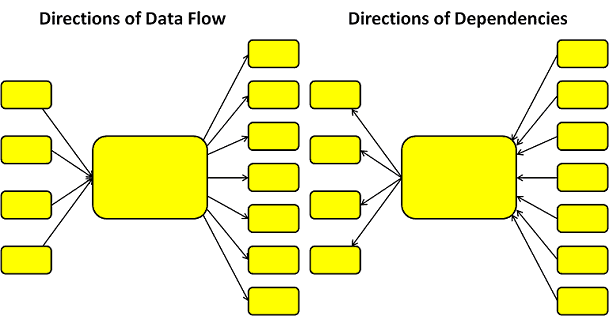
And the thing about dependency is that sometimes you can’t depend on them. So you definitely want to isolate yourself from upstream dependencies. In his book, Release It!, Michael outlined a number of useful patterns to help you do just that, e.g. circuit breaker, bulkheads, timeout, fail fast. Many of these patterns have been incorporated in libraries such as Netflix’s Hystrix.
Another kind of failure is when you have missed a solution space entirely. This is where modularity can give you value in that it gives you options that you might exercise in future.
Just as options in the financial sense (a long call in this case), there’s a negative payoff at the start as you need to do some work to create the option. But if you choose to exercise the option in the future then there’s a long positive payoff.
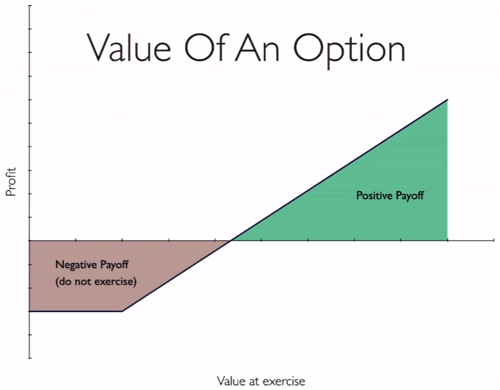
Whilst Michael didn’t spell it out, I think the value of modularity in this case lies in the ability to recover from having missed a solution space the first time around. If the modularity is there then at least you have to option to adopt a different solution at a later point (i.e. exercising the option).
Michael then gave an example of a trading company who has build their system as many small applications integrated by messaging. The applications are small enough and fine grained enough that it’s cheaper to rewrite than to maintain, so they treat these applications as disposable components.
I’d like to give a shout out to Greg Young’s recent talk, The Art of Destroying Software, where he talked at length about building systems whilst optimizing for deletability. That is, you should build systems so that they’re never bigger than what you can reasonably rewrite in a week. And that is as good a guideline on “how big should my microservice be?” as I have heard so far.
6 & 7. Data Outlives Applications; Applications Outlives Integrations
As things change, a typical layered architecture breaks when there are pressure from either side.
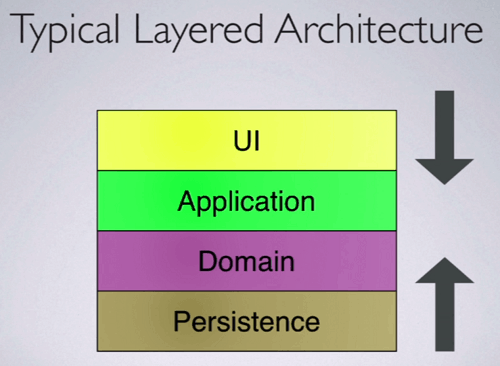
A Hexagonal architecture, or Ports and Adapters style architecture on the other hand, puts your domain in the centre rather than the bottom of the stack. The domain is then connected to the outside world via adapters that bridges between the concepts of that adapter and the concepts of the domain.
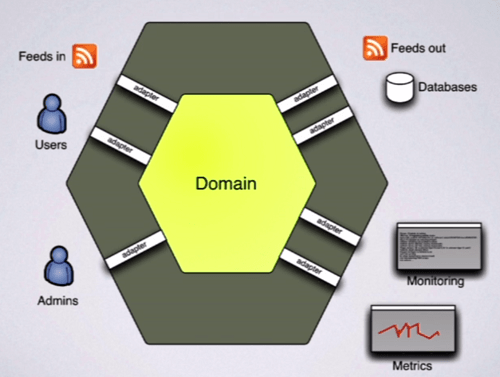
Hexagonal architectures make technology transition more of a boundary layer issue than a domain layer issue, and allows you to explicitly represent multiple adapters from the same domain for different purposes.
8. Increase Discoverability
In large organizations you often find people working on projects with significant amounts of overlap due to lack of discoverability about what other people are working on.
Just as one would search Github or Google to see if a similar project exists already before embarking on his/her own open source alternative, we should be doing more to enable discoverability within companies.
Doing so allows us to move faster by building on top of others work, but in order to do this we need to make our work visible internally:
- internal blogs
- open, easily accessible code repositories
- modern search engine
Internal teams should work like open source projects whilst retaining a product mentality.
One thing to watch out for is the budget culture where:
- contributions to other people’s projects are not welcomed due to budget fights;
- inquiries about each other’s work are alarming and considered precursor to their attempt to suck your budget into theirs
Instead you should embrace an engineering culture which tend to be much more open. You could start to build up an engineering culture by:
- having team blogs
- allow users to report bugs
- make CI servers public
Finally, stop chasing idealized end state, and embrace the wave of change.
I was at QCon London earlier this year, and in Kevlin Henney’s Small is Beautiful talk he delivered a similar message. That we should think of software as products, not projects. If software are projects then they should have well-defined end state, but most often, software do not have well-defined end state, but rather evolved continuously for as long as it remains desirable and purposeful.
Links
- Release It! by Michael Nygard
- Don’t learn a syntax, learn to change the way you think
- QCon London 15 – Small is Beautiful
- REST APIs must be hypertext-driven
- HAL spec
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: CraftConf 15–Takeaways from “Beyond Features” | theburningmonk.com