
Yan Cui
I help clients go faster for less using serverless technologies.

NOTE : read the rest of the series, or check out the source code.
If you enjoy reading these exercises then please buy Crista’s book to support her work.

Following on from the last post, we will look at the Lazy Rivers style today.
Style 27 – Lazy Rivers
Constraints
- Data comes to functions in streams, rather than as a complete whole all at at once.
- Functions are filters / transformers from one kind of data stream to another.
Given the constraint that data is to come in as streams, the easiest way to model that in F# is using sequences.
First, let’s add a function to read the text from an input file as a seq<char>.

Then, we’ll add another function to transform this sequence of characters into a sequence of words.

Next, we’ll filter this sequence to remove all the stop words and return the non-stop words as another seq<string>.
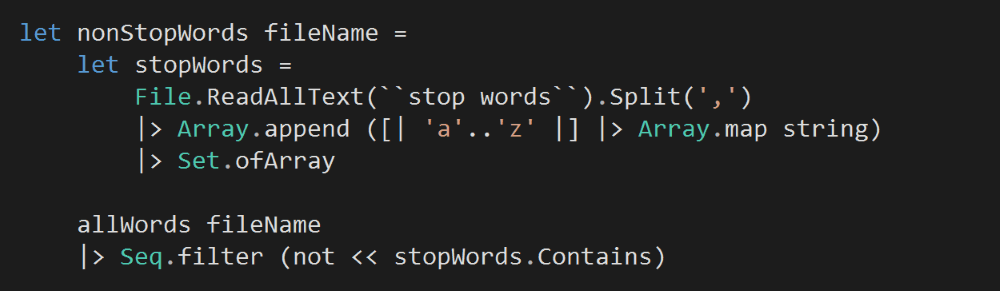
So far everything’s pretty straightforward, but things get a bit tricky from here on.
To count and sort the non-stop words, we can return the running count as a sequence after each word, but that’s terribly inefficient.
Instead, we can batch the input stream into groups of 5000 words. We’ll update the word frequencies with each batch and produce a new sorted array of word counts for the output sequence.
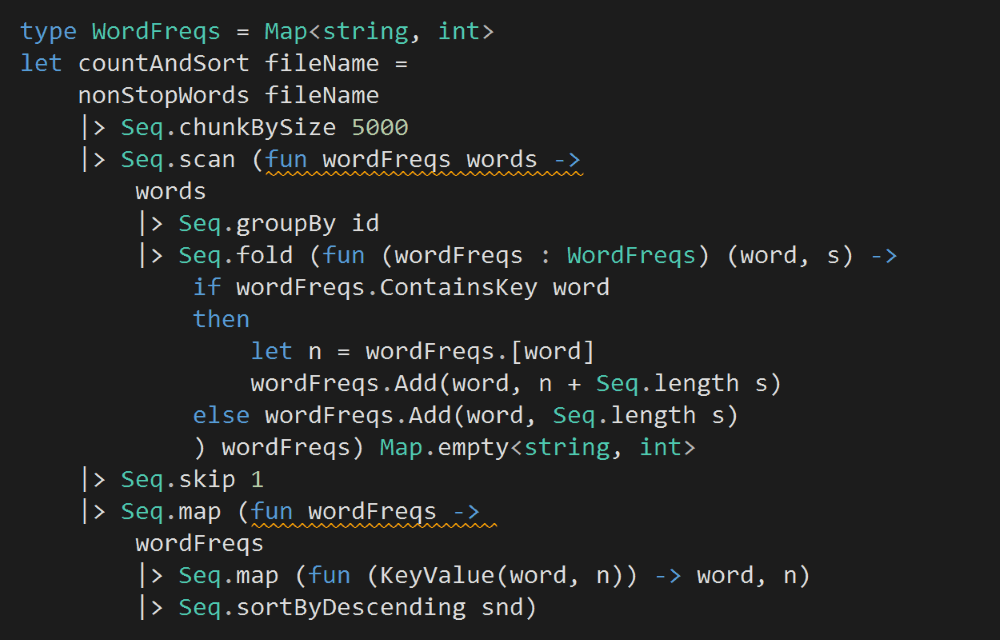
In the snippet above, focus on the Seq.scan section (ps. Seq.scan is similar to Seq.fold, except it returns all the intermediate values for the accumulator, not just the final accumulated value).
Here, given the current word frequencies map and a batch of words, we’ll return a new map (remember, a F# Map is immutable) whose counts have been updated by the latest batch.
Because Seq.scan returns results for all intermediate steps including the initial value (the empty map in this case), we have to follow up with Seq.skip 1 to exclude the empty map from our output.
Finally, to string everything together, we’ll print the top 25 words for each of the outputs from countAndSort. It takes quite a few iterations, but you’ll see the result slowly emerging in the process.
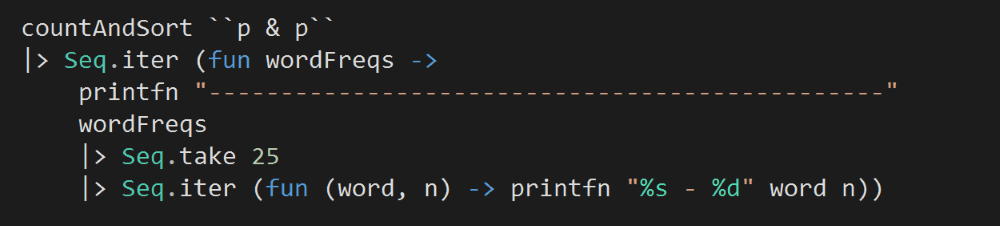
Unlike the other styles, we’ll get a few sets of outputs – one for each batch of words processed.
You can find the source code for this exercise here.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: Exercises in Programming Style–Actors | theburningmonk.com
Pingback: F# Weekly #13, 2016 – Sergey Tihon's Blog