
Yan Cui
I help clients go faster for less using serverless technologies.
This post is part of the F# Advent Calendar in English 2014 project. Check out all the other great posts there!
Special thanks to Sergey Tihon for organizing this.
A good coding habit is an incredibly powerful tool, it allows us to make good decisions with minimal cognitive effort and can be the difference between being a good programmer and a great one.
“I’m not a great programmer; I’m just a good programmer with great habits.”
– Kent Beck
A bad habit, on the other hand, can forever condemn us to repeat the same mistakes and is difficult to correct.
I attended Kevlin Henney’s “Seven Ineffective Coding Habits of Many Programmers” talk at the recent BuildStuff conference. As I sat in the audience and reflected on the times I exhibited many of the bad habits he identified and challenged, something hit me – I was coding in C# in pretty much every case even though I also spend a lot of time in F#.
Am I just a bad C# developer who’s better at F#, or did the language I use make a bigger difference than I realized at the time?
With this question in mind, I revisited the seven ineffective coding habits that Kevlin identified and pondered why they are habits that many F# programmers don’t have.
Noisy Code
Signal-to-noise ratio sometimes refers to the ratio of useful information to false or irrelevant data in a conversation or exchange. Noisy code requires greater cognitive effort on the reader’s part, and is more expensive to maintain.
We have a lot of habits which – without us realising it – add noise to our code. But often the language we use have a big impact on how much noise is added to our code, and the C-style syntax is big culprit here.
Objective comparison between languages are usually difficult because comparing different language implementations across different projects introduces too many other variables. Comparing different language implementations of a small project is achievable but cannot answer how well the solutions scale up to bigger projects.
Fortunately, Simon Cousins was able to provide a comprehensive analysis of two code-bases written in different languages – C# and F# – implementing the same application.
The application was non-trivial (~350k lines of C# code) and the numbers speak for themselves:



Not only is the F# implementation shorter and generally more useful (i.e. higher signal-to-noise ratio), according to Simon’s post it also took a fraction of the man-hours to provide a more complete implementation of the requirements:
“The C# project took five years and peaked at ~8 devs. It never fully implemented all of the contracts.
The F# project took less than a year and peaked at three devs (only one had prior experience with F#). All of the contracts were fully implemented.”
In summary, by removing the need for { } as a core part of the language structure and not having nulls, F# removes a lot of the noise that are usually found in C# code.
Visual Dishonesty
“…a clean design is one that supports visual thinking so people can meet their informational needs with a minimum of conscious effort.”
– Daniel Higginbotham
When it comes to code, visual honesty is about laying out your code so that their visual relationships are obvious and accurate.
For example, when you put things above each other then it signifies hierarchy. This is important, because you’re showing your reader how to process the information you’re giving them. However, you may not be aware that’s what you’re doing, which is why we end up with problems.
“You convey information by the way you arrange a design’s elements in relation to each other. This information is understood immediately, if not consciously, by the people viewing your designs. This is great if the visual relationships are obvious and accurate, but if they’re not, your audience is going to get confused. They’ll have to examine your work carefully, going back and forth between the different parts to make sure they understand.”
– Daniel Higginbotham
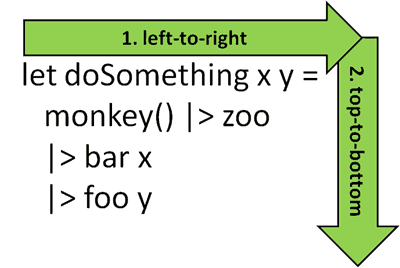
Take the simple matter of how nested method calls are laid out in C#, they betray everything we have been taught about reading, and the order in which information needs to be processed has been reversed.


Fortunately, F# introduced the pipeline operator |> which allows us to restore the visual honesty with the way we lay out nested functions calls.
In his talk Kevlin also touched on the placement of { } and how it affects readability, using a rather simple technique:


and by doing so, it reveals interesting properties about the structure of the above code which we might not have noticed:
- we can’t tell where the argument list ends and method body starts
- we can’t tell where the if condition ends and where the if body starts
These tell us that even though we are aligning our code, its structure and hierarchy is still not immediately clear without the aid of the curly braces. Remember, if the visual relationship between the elements is not accurate, it’ll cause confusion for your readers and they need to examine your code carefully to ensure they understand it correctly. In order words, you create additional cognitive burden on your readers when the layout of your code does not match the program structure.
Now contrast with the following:


where the structure and hierarchy of the code is much more evident. So it turns out that placement style of { } is not just a matter of personal preference, it plays an important role in conveying the structure of your code and there’s a right way to do it.
“It turns out that style matters in programming for the same reason that it matters in writing.
It makes for better reading.”
– Douglas Crockford
In hindsight this seems obvious, but why do we still get it wrong? How can so many of us miss something so obvious?
I think part of the problem is that, you have two competing rules for structuring your code in C-style languages – one for the compiler and one for humans. { and } are used to convey structure of your code to the compiler, but to convey structure information to humans, you use both { } and indentation.
This, coupled with the eagerness to superficially reduce the line count or adhere by guidelines such as “methods shouldn’t be more than 60 lines long”, and we have the perfect storm that results in us sacrificing readability in the name of readability.
So what if you use space for conveying structure information to both the compiler and humans? Then you remove the ambiguity and people can stop fighting about where to place their curly braces!
The above example can be written in F# as the following, using conventions in the F# community:


notice how the code is not only much shorter, but also structurally very clear.
In summary, F#’s pipes allows you to restore visual honesty with regards to the way nested function calls are arranged so that the flow of information matches the way we read. In addition, whitespaces provide a consistent way to depict hierarchy information to both the compiler and human. It removes the need to argue over { } placement strategies whilst making the structure of your code clear to see at the same time.
Lego naming
Naming is hard, and as Kevlin points out that so often we resort to lego naming by gluing common words such as ‘create’, ‘process’, ‘validate’, ‘factory’ together in an attempt to create meaning.
This is not naming, it is labelling.
Adding more words is not the same as adding meaning. In fact, more often than not it can have the opposite effect of diluting the meaning of the thing we’re trying to name. This is how we end up with gems such as controllerFactoryFactory, where the meaning of the whole is less than the sum of its parts.

Naming is hard, and having to give names to everything – every class, method and variable – makes it even harder. In fact, trying to give everything a meaningful name is so hard, that eventually most of us simply stop caring, and lego naming seems like the lazy way out.
In F#, and in functional programming in general, it’s common practice to use anonymous functions, or lambdas. Straight away you remove the need to come up with good names for a whole bunch of things. Often the meaning of these lambdas are created by the higher order functions that use them – Array.map, Array.filter, Array.iter, e.g. the function passed into Array.map is used to, surprise surprise, map values in an array!
(Before you say it, yes, you can use anonymous delegates in C# too, especially when working with LINQ. However, when you use LINQ you are doing functional programming, and the use of lambdas is much more common in F# and other functional-first languages.)
Lego naming can also be the symptom of a failure to identify the right level of abstractions.
Just like naming, coming up with the right abstractions can be hard. And when the right abstraction is a piece of pure functionality, we don’t have a way to represent it effectively in OOP (note, I’m not talking about the object-orientation that Alan Kay had in mind when he coined the term objects).
In situations like this, the common practice in OOP is to wrap the functionality inside a class or interface. So you end up with something that provides the desired functionality, and the functionality itself. That’s two things to name instead of one, this is hard, let’s be lazy and combine some common words together and see if they make sense…
public interface ConditionChecker
{
bool CheckCondition();
}
The problem here is that the right level of abstraction is smaller than an “object”, so we have to introduce another layer of abstraction just to make it fit into our world view.
In F#, and in functional programming in general, no abstraction is too small and functions are so ubiquitous that all the OO patterns that we’re so fond of can be represented as functions.
Take the ConditionChecker example above, the essence of what we’re looking for is a condition that is evaluated without input and returns a boolean value. This can be represented as the following in F#:
type Condition = unit –> bool
Much more concise, wouldn’t you agree? And any function that matches the type signature can be treated as a Condition without having to explicitly implement some interface.
Another common practice in C# and Java is to label exception types with Exception, i.e. CastException, ArgumentException, etc. This is another symptom of our tendency to label things rather than naming them, out of laziness (and not the good kind).
If we had put in more thought into them, than maybe we could have come up with more meaningful names, for instance:

In F#, the common practice is to define errors using the lightweight exception syntax, and the convention here is to not use the Exception suffix since the leading exception keyword already provides sufficient clue as to what the type represents.

In summary, whilst F# doesn’t stop you from lego naming things, it helps because:
- the use of anonymous functions reduces the number of things you have to name significantly;
- being able to model your application at the right level of abstraction removes unnecessary layers of abstractions, and therefore reduce the number of things you have to name even further,
- it’s easier to name things when they’re at the right level of abstraction;
- convention in F# is to use the lightweight exception syntax to define exception types without the Exception suffix.
Under-Abstraction
In his presentation, Kevlin showed an interesting technique of using a tag cloud to see what pops out from your code:


Compare these two examples you can see the domain of the second example surfacing through the tag cloud – paper, picture, printingdevice, etc. whereas the first example shows raw strings and lists.
When we under abstract, we often find ourselves with a long list of arguments to our methods/functions. When that list gets long enough, adding another one or two arguments is no longer significant.
“If you have a procedure with ten parameters, you probably missed some.”
– Alan Perlis
Unfortunately, F# can’t stop you from under abstracting, but it has a powerful type system that provides all the necessary tools for you to create the right abstractions for your domain with minimal effort. Have a look at Scott Wlaschin’s talk on DDD with the F# type system for inspirations on how you might do that:
Unencapsulated State
If under-abstraction is like going to a job interview in your pyjamas then having unencapsulated state would be akin to wearing your underwear on the outside (which, incidentally put you in some rather famous circles…).

The example that Kevlin used to illustrate this habit is dangerous because the internal state that has been exposed to the outside world is mutable. So not only is your underwear worn on the outside for all to see, everyone is able to modify it without your consent… now that’s a scary thought!
In this example, what should have been done is for us to encapsulate the mutable list and expose only the properties that are relevant, for instance:
type RecentlyUsedList () =
let items = new List<string>()
member this.Items = items.ToArray() // now the outside world can’t mutate our internal state
member this.Count = items.Count
…
Whilst F# has no way to stop you from exposing the items list publically, functional programmers are very conscious of maintaining the immutability facade so even if a F#’er is using a mutable list internally he would not have allowed it to leak outside.
In fact, a F#’er would probably have implemented a RecentlyUsedList differently, for instance:
type RecentlyUsedList (?items) =
let items = defaultArg items [ ]
member this.Items = List.toArray items
member this.Count = List.length items
member this.Add newItem =
let newItems = newItem::(items |> List.filter ((<>) newItem))
RecentlyUsedList newItems
But there’s more.
Kevlin also touched on encapsulation in general, and its relation to a usability study concept called affordance.
“An affordance is a quality of an object, or an environment, which allows an individual to perform an action. For example, a knob affords twisting, and perhaps pushing, whilst a cord affords pulling.”
– Wikipedia
If you want the user to push, then don’t give them something that they can pull, that’d be bad usability design. The same principles applies to code, your abstractions should afford the right behaviours whilst make it impossible to do the wrong thing.
When modelling your domain with F#, since there are no nulls it immediately eliminates the most common illegal state that you have to look out for. And since types are immutable by default, once they are validated at construction time you don’t have to worry about them entering into an invalid state later.
To make invalid states un-representable in your model, a common practice is to create a finite, closed set of possible valid states as a discriminated union. As a simple example:
type PaymentMethod =
| Cash
| Cheque of ChequeNumber
| Card of CardType * CardNumber
Compared to a class hierarchy, a discriminated union type cannot be extended and therefore invalid states cannot be introduced at a later date by abusing/exploiting inheritance.
In summary, F# programmers are very conscious of immutability so even if they are using mutable types to represent internal state it’s highly unlikely for them to expose their mutability and break the immutability facade they hold so dearly.
And because types are immutable by default, and there are no nulls in F#, it’s also easy for you to ensure that invalid states are simply un-representable when modelling a domain.
Getters and Setters
Kevlin challenged the naming of getters and setters, since in English ‘get’ usually implies side effects:
“I get married”
“I get money from the ATM”
“I get from point A to point B”
Yet, in programming, get implies a query with no side effects.
Also, getters and setters are opposites in programming, but in English, the opposite of set is reset or unset.
Secondly, Kevlin challenged the habit of always creating setters whenever we create getters. This habit is even enforced and encouraged by many modern IDEs that gives you shortcuts to automatically create these getters and setters in pairs.
“That’s great, now we have shortcuts to do the wrong thing.
We used to have type lots to do the wrong thing, not anymore.”
– Kevlin Henney
And he talked about how we need to be more cautious and conscious about what can change and what cannot.
“When it is not necessary to change, it is necessary not to change.”
– Lucius Cary
With F#, immutability is the default, so when you define a new record or value, it is immutable unless you explicitly say so otherwise (with the mutable keyword). So to do the wrong thing, i.e. to define a corresponding setter for every getter, you have to do lots of extra work.
Every time you have to type the mutable keyword is another chance for you to ask yourself “is it really necessary for this field to change”. In my experience it has provided sufficient friction and forced me to make very conscious decisions on what can change under what conditions.
Uncohesive Tests
Many of us have the habit of testing methods – that is, for every method Foo we have a TestFoo that invokes Foo and inspects its behaviour. This type of testing covers only the surface area of your code, and although you can achieve a high code coverage percentage this way (and keep the managers happy), that coverage number is only superficial.
Methods are usually called in different combinations to achieve some desired functionality, and many of the complexities and potential bugs lie in the way they work together. This is particularly true when states are concerned as the order the state is updated in might be significant and you also bring concurrency into the equation.
Kevlin calls for an end of this practice and for us to focus on testing specific functionalities instead, and use our tests as specifications for those functionalities.
“For tests to drive development they must do more than just test that code performs its required functionality: they must clearly express that required functionality to the reader. That is, they must be clear specification of the required functionality.”
– Nat Pryce and Steve Freeman
This is in line with Gojko Adzic’s Specification by Example which advocates the use of tests as a form of specification for your application that is executable and always up-to-date.
But, even as we improve on what we test, we still need to have sufficient number of tests to give us a reasonable degree of confidence. To put it into context, an exhaustive test suit for a function of the signature Int –> Int would need to have 2147483647 test cases. Of course, you don’t need an exhaustive test suit to reach a reasonable degree of confidence, but there’s a limitation on the number of tests that we will be able to write by hand because:
- writing and maintaining large number of tests are expensive
- we might not think of all the edge cases
This is where property-based automated testing comes in, and that’s where the F# (and other QuickCheck-enabled languages such as Haskell and Erlang) community is at with the widespread adoption of FsCheck. If you’re new to FsCheck or property-based testing in general, check out Scott Wlaschin’s detailed introductory post to property-based testing as part of the F# Advent Calendar in English 2014.
Summary
We pick up habits – good and bad – over time and with practice. Since we know that practice doesn’t make perfect, it makes permanent; only perfect practice makes perfect, it is important for us to acquire good practice in order to form and nurture good habits.
The programming language we use day-to-day plays an important role in this regard.
“Programming languages have a devious influence: they shape our thinking habits.”
– Dijkstra
As another year draws to a close, let’s hope the year ahead is filled with the good practice we need to make perfect, and to ensure it let’s all write more F# :-P
Wish you all a merry xmas!
Links
F# Advent Calendar in English 2014
Kevlin Henney – Seven ineffective coding habits of many programmers
Andreas Selfik – The programming language wars
Simon Cousins – Does the language you use make a difference (revisited)
Coding Horror – The best code is no code at all
F# for Fun and Profit – Cycles and modularity in the wild
Joshua Bloch – How to design a good API and why it matters
Null References : the Billion dollar mistake
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop to level up your serverless skills quickly.
- Do you want to know how to test serverless architectures with a fast dev & test loop? Check out my latest course, Testing Serverless Architectures and learn the smart way to test serverless.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
Excellent post!
Pingback: F# Advent Calendar in English 2014 | Sergey Tihon's Blog
Pingback: Year in Review, 2014 | theburningmonk.com
Pingback: QCon London 2015–Takeaways from “Small is Beautiful” | theburningmonk.com
Pingback: Random thoughts on API design | theburningmonk.com
how can programmers practice at all, let alone perfectly, when all the educational materials are essentially just jargon re-mappings?
one of the huge advantages of F# (at least for .NETters) is that it almost precludes all the unnecessary re-jargonning by its nature…
monads, currying, and the other functional terms, while not trivial, are unavoidably mathematical: once you get them down, they are concepts that dont become obsolete halfway thru your career…unlike ‘design patterns’ or ‘philosophies’ that eventually rot into a ‘code smell’, or degenerate into ‘code noise’ – your discussion of ‘test cohesiveness’ translates to the relatively stable mathematical idea of function composition, etc…
Pingback: Szumma #048 – 2016 28. hét | d/fuel