
Yan Cui
I help clients go faster for less using serverless technologies.
AWS announced binary support for API Gateway in late 2016, which opened up the door for you to use more efficient binary formats such as Google’s Protocol Buffers and Apache Thrift.
Why?
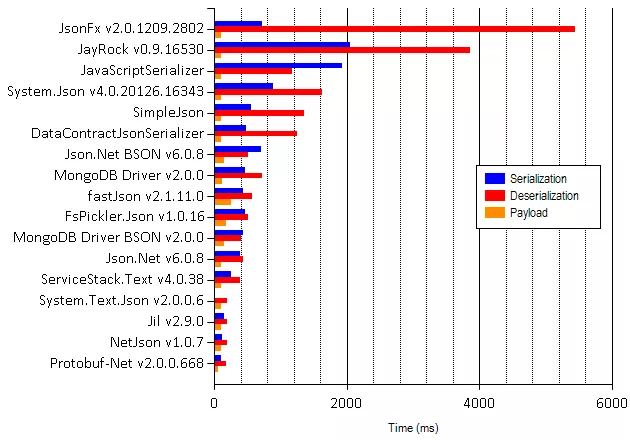
Compared to JSON – which is the bread and butter for APIs built with API Gateway and Lambda – these binary formats can produce significantly smaller payloads.
At scale, they can make a big difference to your bandwidth cost.
In restricted environments such as low-end devices or in countries with poor mobile connections, sending smaller payloads can also improve your user experience by improving the end-to-end network latency, and possibly processing time on the device too.
How
Follow these 3 simple steps (assuming you’re using Serverless framework):
- install the awesome serverless-apigw-binary plugin
- add
application/x-protobufto binary media types (see screenshot below) - add function that returns Protocol Buffers as base64 encoded response

To encode & decode Protocol Buffers payload in Nodejs, you can use the protobufjs package from NPM.
It lets you work with your existing .proto files, or you can use JSON descriptors. Give the docs a read to see how you can get started.
In the demo project (link at the bottom of the post) you’ll find a Lambda function that always returns a response in Protocol Buffers.
'use strict';
const co = require('co');
const Promise = require('bluebird');
const protobuf = Promise.promisifyAll(require("protobufjs"));
const lib = require('./lib');
const fs = require('fs');
module.exports.handler = co.wrap(function* (event, context, callback) {
console.log(JSON.stringify(event));
let players = lib.genPlayers();
let root = yield protobuf.loadAsync("functions/player.proto");
let Players = root.lookupType("protodemo.Players");
let message = Players.create(players);
let buffer = Players.encode(message).finish();
const response = {
statusCode: 200,
headers: { 'Content-Type': 'application/x-protobuf' },
body: buffer.toString('base64'),
isBase64Encoded: true
};
callback(null, response);
});
Couple of things to note from this function:
- we set the
Content-Typeheader toapplication/x-protobuf bodyis base64 encoded representation of the Protocol Buffers payloadisBase64Encodedis set totrue
you need to do all 3 of these things to make API Gateway return the response as binary data.
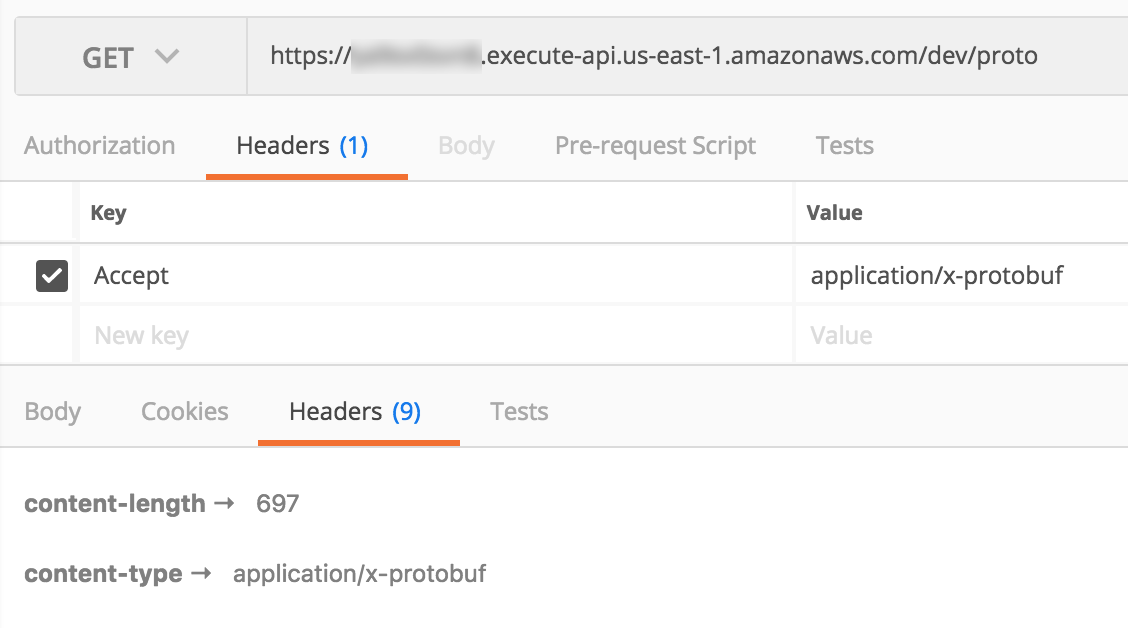
Consider them the magic incantation for making API Gateway return binary data, and, the caller also has to set the Accept header to application/x-protobuf.
In the same project, there’s also a JSON endpoint that returns the same payload as comparison.
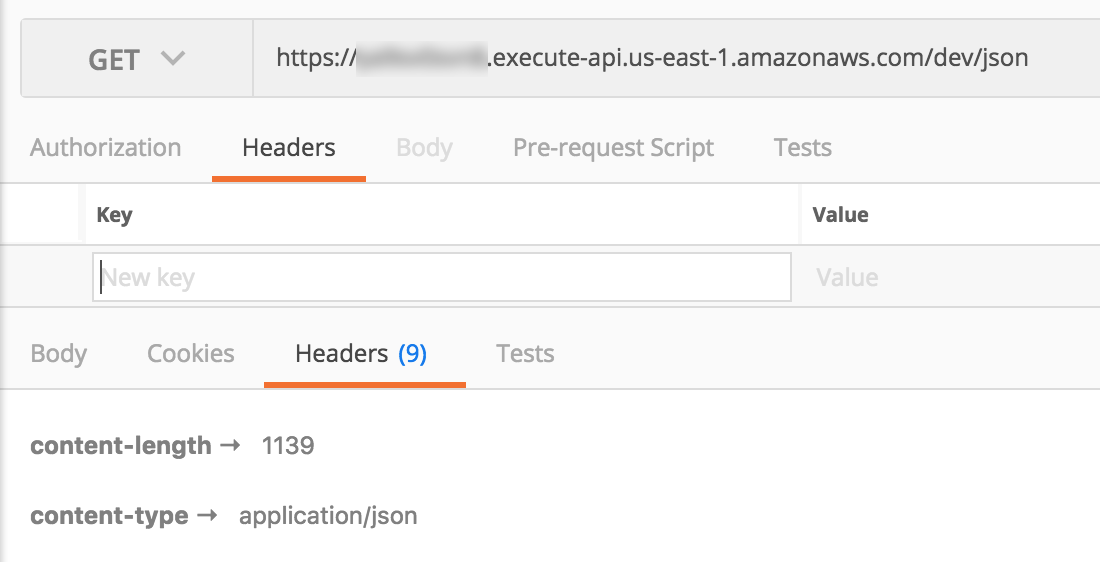
The response from this JSON endpoint looks like this:
{"players":[{"id":"eb66db14992e06b36282d607cf0134ce4fe45f50","name":"Calvin Ortiz","scores":[57,12,100,56,47,78,20,37,32,48]},{"id":"7b9b38e535453d120e706ff57fef41f6fee991cb","name":"Marcus Cummings","scores":[40,57,24,15,45,54,25,67,59,23]},{"id":"db34a2a5f4d16e77a6d3d6154a8b8bb6760b3b99","name":"Harry James","scores":[61,85,14,70,8,80,14,22,76,87]},{"id":"e21018c4f43eef10771e0fa71bc54156b00a64dd","name":"Gregory Bishop","scores":[51,31,27,47,72,75,61,28,100,41]},{"id":"b3ee29ee49b640ce15be1737d0dca60e48108ee1","name":"Ann Evans","scores":[69,17,48,99,85,8,75,55,78,46]},{"id":"9c1e6d4d46bb0c0d2c92bab11e5dbd5f4ab0c619","name":"Juan Perez","scores":[71,34,60,84,21,98,60,8,91,92]},{"id":"d8de89222633c61393931457c1e72558eba48639","name":"Loretta Harvey","scores":[15,40,73,92,42,65,58,30,26,84]},{"id":"141dad672ec559431f808964391d128d2c3274bf","name":"Ian Powell","scores":[17,21,14,84,64,14,22,22,34,92]},{"id":"8a97e85e2e5385c45fc31f24bfe781c26f78c0b7","name":"Steve Gibson","scores":[33,97,6,1,20,1,78,3,77,19]},{"id":"6b3ca6924e17cd5fd9d91b36d49b36a5d542c9ea","name":"Harold Ferguson","scores":[31,32,4,10,37,85,46,86,39,17]}]}
As you can see, it’s just a bunch of randomly generated names and GUIDs, and integers. The same response in Protocol Buffers is nearly 40% smaller.
Problem with the protobufjs package
Before we move on, there is one important detail about using the protobufjspacakge in a Lambda function – you need to npm install the package on a Linux system.
This is because it has a dependency that is distributed as native binaries, so if you installed the packaged on OSX then the binaries that are packaged and deployed to Lambda will not run on the Lambda execution environment.
I had similar problems with other Google libraries in the past. I find the best way to deal with this is to take a leaf out of aws-serverless-go-shim’s approach and deploy your code inside a Docker container.
This way, you would locally install a compatible version of the native binaries for your OS so you can continue to run and debug your function with sls invoke local (see this post for details).
But, during deployment, a script would run npm install --force in a Docker container running a compatible Linux distribution. This would then install a version of the native binaries that can be executed in the Lambda execution environment. The script would then use sls deploy to deploy the function.
The deployment script can be something simple like this:
#!/usr/bin/env bash npm install --force node_modules/.bin/sls deploy
In the demo project, I also have a docker-compose.yml file:
deploy:
image: node:latest
environment:
- HOME=/home
volumes:
- .:/src
- $HOME/.aws:/home/.aws
working_dir: /src
command: "./deploy.sh"
The Serverless framework requires my AWS credentials, hence why I’ve attached the $HOME/.aws directory to the container for the AWSSDK to find at runtime.
To deploy, run docker-compose up.
Use HTTP content negotiation
Whilst binary formats are more efficient when it comes to payload size, they do have one major problem: they’re really hard to debug.
Imagine the scenario – you have observed a bug, but you’re not sure if the problem is in the client app or the server. But hey, let’s just observe the HTTP conversation with a HTTP proxy such as Charles or Fiddler.
This workflow works great for JSON but breaks down when it comes to binary formats such as Protocol Buffers as the payloads are not human readable.
As we have discussed in this post, the human readability of JSON comes with the cost of heavier bandwidth usage. For most network communications, be it service-to-service, or service-to-client, unless a human is actively “reading” the payloads it’s not worth paying the cost. But when a human is trying to read it, that human readability is very valuable.
Fortunately, HTTP’s content negotiation mechanism means we can have the best of both worlds.
In the demo project, there is a contentNegotiated function which returns either JSON or Protocol Buffers payloads based on what the Accept header.
module.exports.handler = co.wrap(function* (event, context, callback) {
let players = lib.genPlayers();
let accept = event.headers.Accept || "application/json";
switch (accept) {
case "application/x-protobuf":
let response = yield protoResponse(players, "functions/player.proto", "protodemo.Players");
callback(null, response);
break;
case "application/json":
callback(null, jsonResponse(players));
break;
default:
callback(null, NotAcceptableResponse);
}
});
By default, you should use Protocol Buffers for all your network communications to minimise bandwidth use.
But, you should build in a mechanism for toggling the communication to JSON when you need to observe the communications. This might mean:
- for debug builds of your mobile app, allow super users (devs, QA, etc.) the ability to turn on
debugmode, which would switch the networking layer to send Accept header asapplication/json - for services, include a configuration option to turn on
debugmode (see this post on configuring functions with SSM parameters and cache client for hot-swapping) to make service-to-service calls use JSON too, so you can capture and analyze the request and responses more easily
As usual, you can try out the demo code yourself, the repo is available here.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop to level up your serverless skills quickly.
- Do you want to know how to test serverless architectures with a fast dev & test loop? Check out my latest course, Testing Serverless Architectures and learn the smart way to test serverless.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.