How to apply the TDD mindset to serverless
Testing is an integral part of software development, and serverless is no different.
Test Driven Development, or TDD, is long regarded as a leading practice in software development. And yet, one of the most misunderstood parts of Test-Driven Development (TDD) is the “Driven” part of the name. It’s not just about “writing tests before you write the code”. If your tests do not inform and drive your API design, then you’re not really doing TDD.
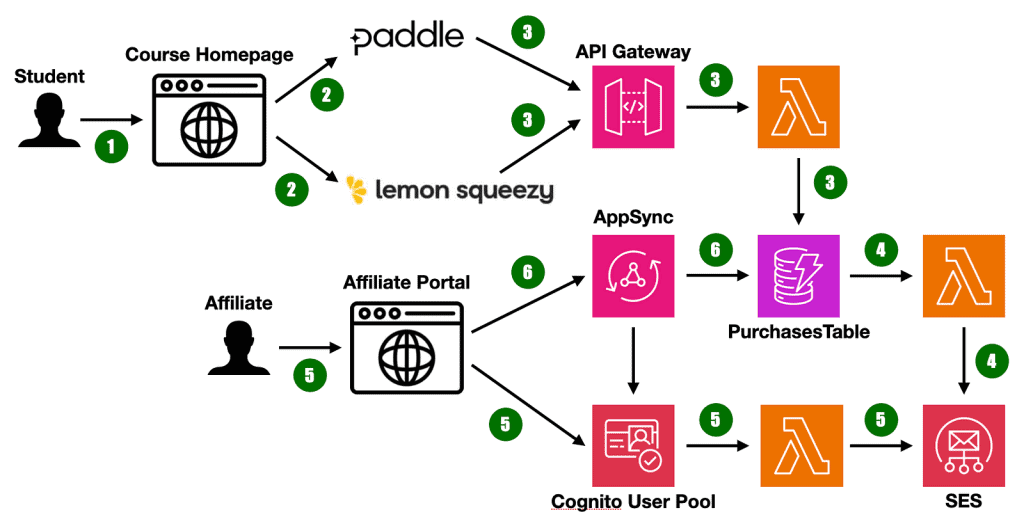
In this post, let’s look at how we can apply the TDD mindset to serverless and use our tests to drive the design of our serverless application.