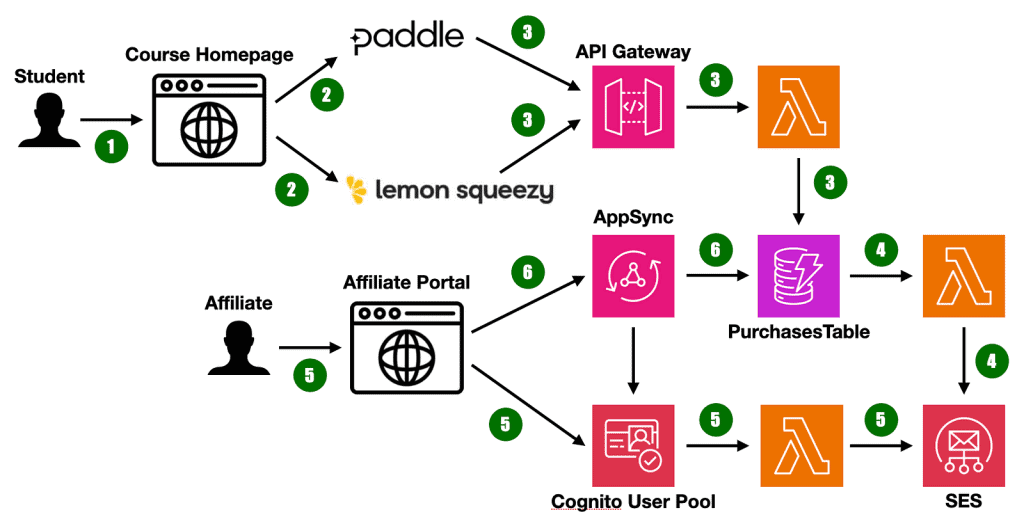
When to use Step Functions vs. doing it all in a Lambda function
I’m a big fan of Step Functions, but it’s yet another AWS service you must learn and pay for.
It also introduces additional complexities. My application is harder to test; my business logic is split between configuration (ASL) and code; and I have new decision points, such as whether to use Express Workflows or Standard Workflows.
So it’s fair to ask, “Why should we even bother with Step Functions?”. Why not just do everything in code, inside a Lambda function?
Let’s break down the pros and cons and look at the trade-offs of each.