DynamoDB now supports cross-account access. But is that a good idea?
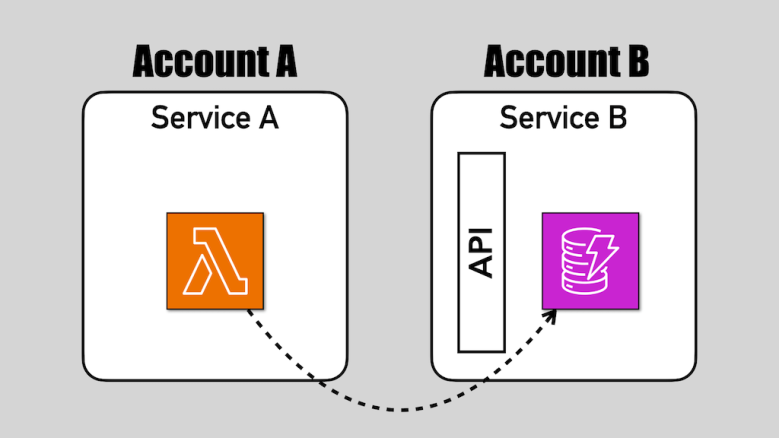
DynamoDB now supports resource-based policies, which simplified cross-account access to tables.
But just because you can, doesn’t mean you should!
Cross-account access to DynamoDB tables is almost always a smell. But as with everything, there are exceptions and edge cases. You should think carefully before you use resource-based policies to enable cross-account access to your DynamoDB tables.
In this post, let’s explore some legitimate use cases for cross-account access to DynamoDB tables.