How to handle execution timeouts in AWS Step Functions
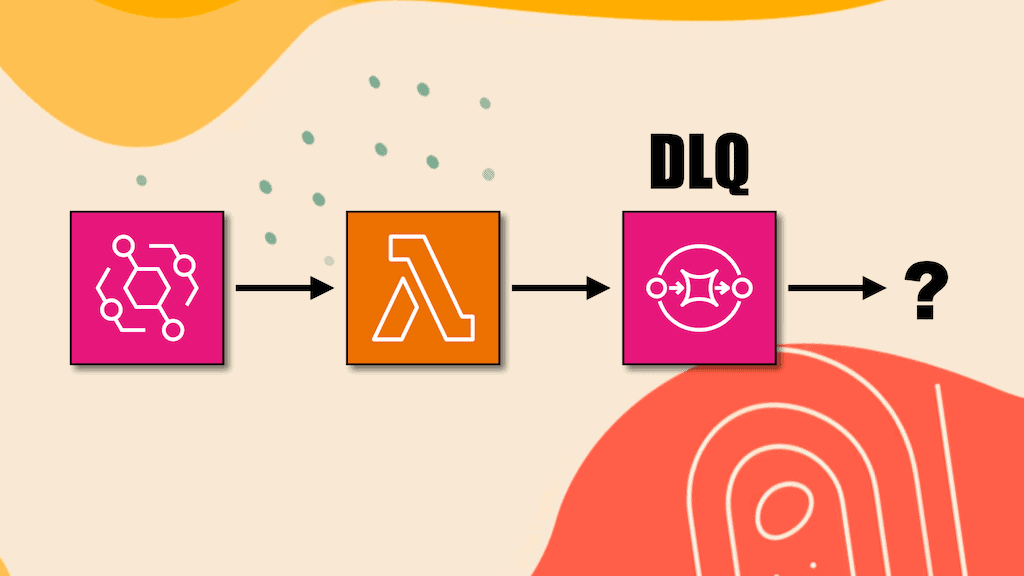
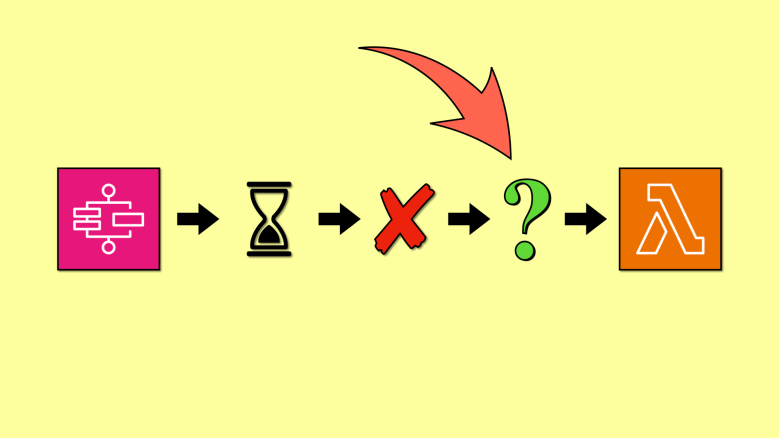
Step Functions lets you set a timeout on both Task states and the whole execution. By default, an execution can run for a year if TimeoutSeconds is not configured. To a user, the execution would appear as “stuck”. Which is why AWS best practices recommend using timeouts to avoid such scenarios. But once you have configured a timeout for the execution, it’s then important to consider what happens when you experience a timeout.
In this post, let’s explore 3 ways you can handle an execution timeout and use a Lambda function to perform automated remediation (e.g. applying rollbacks).