The one mistake everyone makes when using Kinesis with Lambda
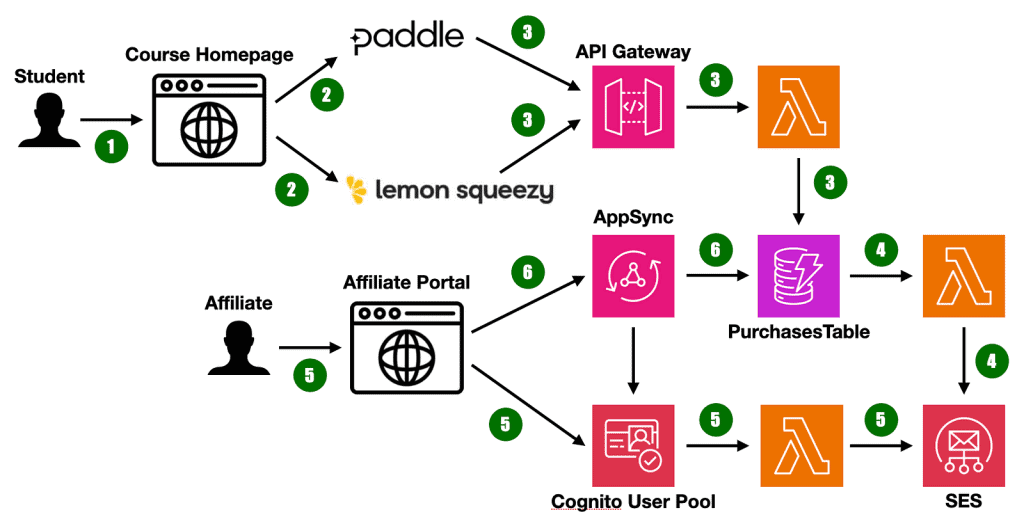
AWS Kinesis and Lambda are a great combo for processing large amounts of data in real-time. However, there’s a common oversight that many developers make when integrating these two services. There are established best practices for configuring Lambda’s EventSourceMapping [1] for Kinesis: Configure an OnFailure destination for failed records. Enable BisectBatchOnFunctionError. Override MaximumRetryAttempts. Choose a …
The one mistake everyone makes when using Kinesis with Lambda Read More »