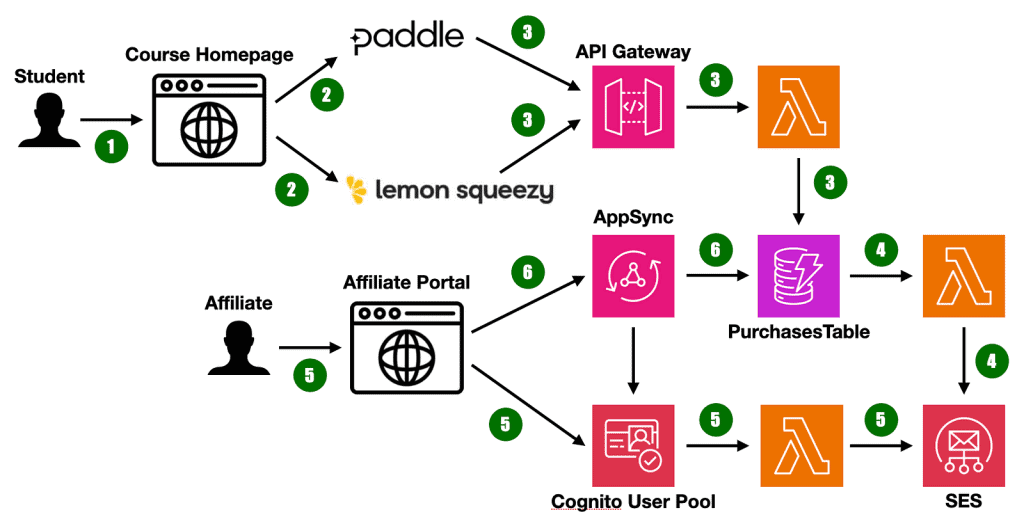
“Lambdalith” is a monolithic approach to building serverless applications where a single Lambda function serves an entire API, instead of having one function per endpoint. It’s an increasingly popular approach and provides portability between Lambda and containers and lets you use familiar web frameworks.
Tools like the AWS Lambda Web Adapter have made this approach more accessible, and it also works well with Lambda Function URLs.
But don’t be too hasty to get rid of API Gateway just yet!
In this post, let’s look at the pros and cons of API Gateway vs. Lambda Function URLs, and let me explain why I still prefer API Gateway.