
Yan Cui
I help clients go faster for less using serverless technologies.

The source code for this post (both Part 1 and Part 2) is available here and you can click here to see my solutions for the other Advent of Code challenges.
Description for today’s challenge is here.
The input for Day 19 looks like the following:
Al => ThF
Al => ThRnFAr
B => BCa
B => TiB
…
ORnPBPMgArCaCaCaSiThCaCaSiThCa…
and it contains a series of replacement rules, as well as the molecule for a medicine.
So we have two kinds of inputs in the same file:

and for each line in the file we will get one or the other:
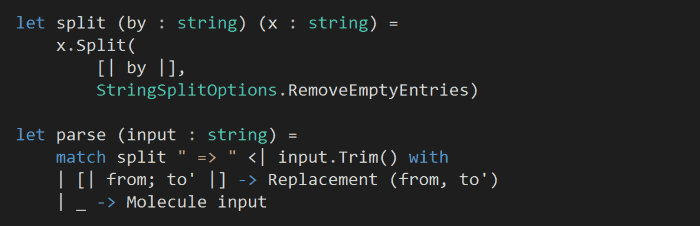
Since we know there’ll only be one molecule in the input file, we can again cheat a little and hard-wire a single element array pattern against the input:
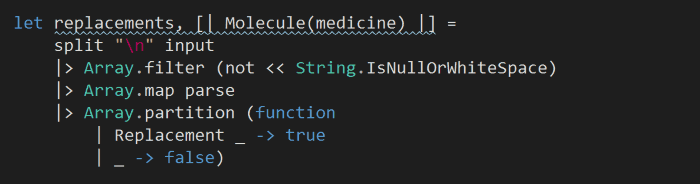
Finally, to answer the challenge, we’ll use each replacement rule to generate a set of new molecules (one for each replaceable string in the current molecule) and count the unique strings that can be generated:

Part 2
After getting stuck on this for the longest time and not able to come up with a solution that solves a problem within a reasonable amount of time (brute force approach just doesn’t work here), I eventually caved in and consulted the AoC subreddit to see how others have solved this problem, spoiler alert and the solution from askalski is soooo elegant.
(whitespace intended in case you don’t want to see the F# implementation of askalski‘s solution)
OK, from here on, I assume you’ve read the subreddit thread with the description of the solution.
So basically, the strings “Rn”, “Y”, “Ar” translates to “(“, “,” and “)”, and everything else are tokens (i.e. the left-hand sides of the replacement rules, e.g. “Ca => SiTh” means “Ca” is a token).
What’s more, we need to process the molecule from right-to-left, so we’ll reverse both the tokens as well as the molecule string itself:
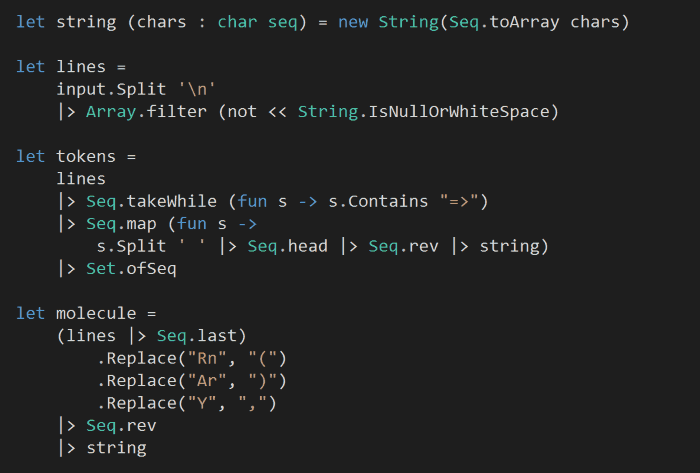
Next, we’ll recursively count the:
- total number of tokens (this includes “Rn”, “Y” and “Ar”)
- number of parentheses (i.e. “Rn” and “Ar”)
- number of commas (i.e. “Y”)

and then finally apply askalski‘s formula to arrive at the answer:

Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: F# Weekly #52, 2015-IT??