
Yan Cui
I help clients go faster for less using serverless technologies.

NOTE : read the rest of the series, or check out the source code.
If you enjoy reading these exercises then please buy Crista’s book to support her work.

Following on from the last post, we will look at the Tantrum style today.
Style 21 – Tantrum
Constraints
- Every single procedure and function checks the sanity of its arguments and refuses to continue when the arguments are unreasonable.
- All code blocks check for all possible errors, possibly print out context-specific messages when errors occur, and pass the errors up the function call chain.
Last week we looked at the Constructivist style where we provide fallback values wherever possible to allow the program to continue in the face of an anomaly. The Tantrum style we’ll look at today is the opposite.
In this style, any invalid input or error will be met with an exception that terminates the program flow, as you can see from the functions below.
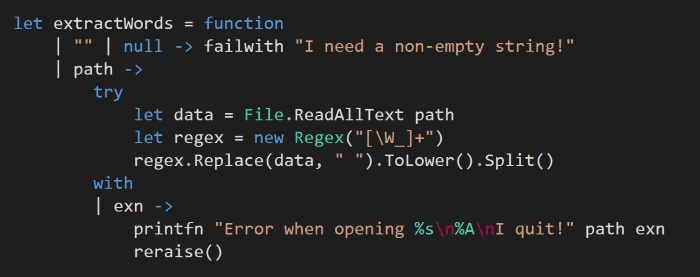
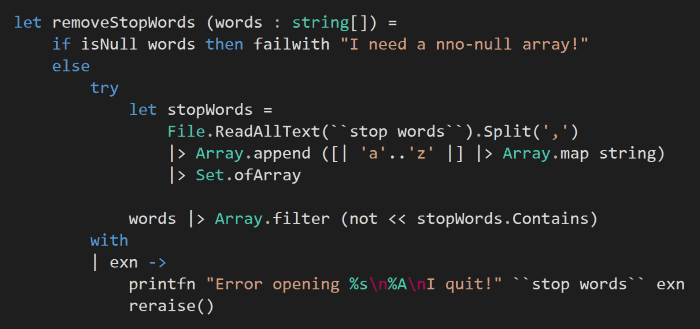
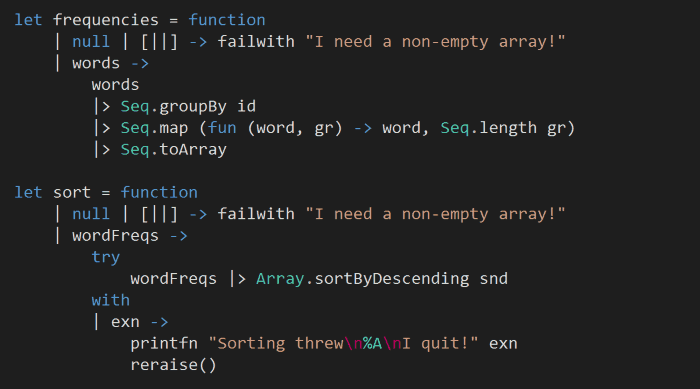
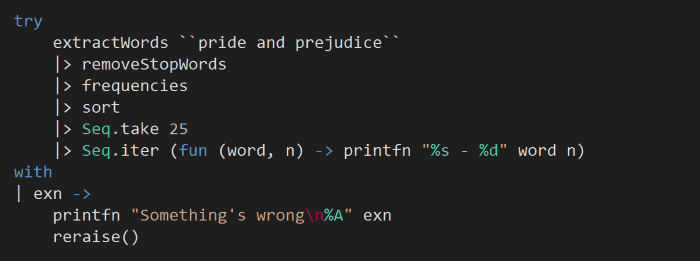
This approach to Fail fast, Fail loudly has often been heralded as a desirable characteristic of a fault-tolerant system. For us developers, it’s also the easy way – we don’t have to think about fallback strategies which can be a challenge on its own, and sometimes there might not be a good fallback strategy at all.
But as we discussed in the last post, adopting a well thought-out fallback strategy can have a massive impact on the user experience. And as Jeff Atwood wrote a long time ago (and it’s still applicable today), the most important consideration should be the needs of your users.
If we adopt a “fail as often and as obnoxiously as possible” strategy, we’ve clearly failed our users. But if we corrupt or lose our users’ data through misguided attempts to prevent error messages– if we fail to treat our users’ data as sacrosanct– we’ve also failed our users. You have to do both at once:
- If you can safely fix the problem, you should. Take responsibility for your program. Don’t slouch through the easy way out by placing the burden for dealing with every problem squarely on your users.
- If you can’t safely fix the problem, always err on the side of protecting the user’s data. Protecting the user’s data is a sacred trust. If you harm that basic contract of trust between the user and your program, you’re hurting not only your credibility– but the credibility of the entire software industry as a whole. Once they’ve been burned by data loss or corruption, users don’t soon forgive.
The guiding principle here, as always, should be to respect your users. Do the right thing.
You can find the source code for this exercise here.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: F# Weekly #9, 2016 - IT??