
Yan Cui
I help clients go faster for less using serverless technologies.

NOTE : read the rest of the series, or check out the source code.
If you enjoy reading these exercises then please buy Crista’s book to support her work.

Following on from the last post, we will look at the Map Reduce style today.
Style 30 – Map Reduce
Constraints
- Input data is divided in chunks, similar to what an inverse multiplexer does to input signals.
- A map function applies a given worker function to each chunk of data, potentially in parallel.
- A reduce function takes the results of the many worker functions and recombines them into a coherent output.
Map reduce should be a familiar paradigm to most developers nowadays. In today’s style we’ll use a very simple map-reduce flow to solver the term frequency problem.
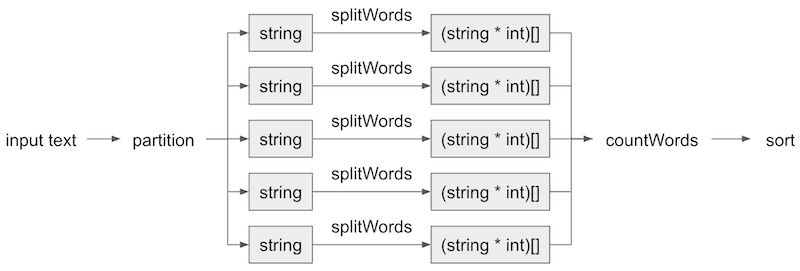
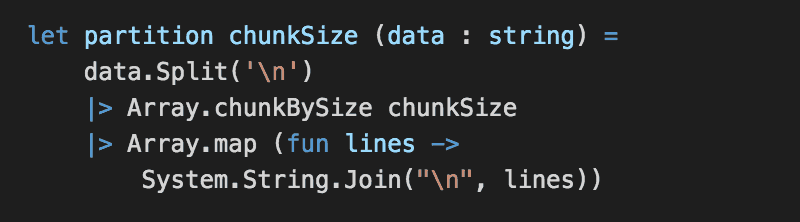
As you can see from the above diagram, we’ll take an input text and split it into X no. of chunks which can be processed in parallel. To do this, we’ll first add a partition function below.
Each chunk of the original input text can then be split and filtered (using the list of stop words) independently.
Two things to note about the splitWords function below:
a) it returns an array of (word, count) tuples
b) it doesn’t perform any local aggregation, so if the same word appear twice in its chunk then it’ll appear as (word, 1) twice in the returned array

Once all the chunks has been processed, we can reduce over them with the countWords function below.

Here, I have taken an imperative approach for efficiency sake, and because that’s what Crista had done in her Python solution. Alternatively, you could have written something along the lines of the following.

which is much more concise and functional in style, but about 25% slower (~100ms) than the imperative approach.
Next, we’ll add a sort function that’ll sort the array of (word, count) values in descending order by the count (i.e. the snd element in the tuple).

And finally, we wire everything together using pipes.

Job done!
or is it?
So far, I have followed Crista’s approach in her Python solution, and the solution meets the constraints of this style. But, we haven’t taken advantage of the potential for parallelism here.
Version 2 – Parallel Processing
To make the processing of the chunks happen in parallel, let’s modify the splitWords function to make it async.

Notice that not much has changed from our non-async version! Except for the minor optimization we added to aggregate the words in the chunk instead of returning duplicated (word, 1) tuples.
The next thing we need to do, is to wrap the original pipeline in an async workflow.
Here, once the partitions have been created, we’ll process them in parallel and wait for all the parallel processing to complete using Async.Parallel before proceeding with the rest of the pipeline as before.

You can find the source code for this exercise here (v1) and here (v2 – async).
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: F# Weekly #16, 2016 – Sergey Tihon's Blog