
Yan Cui
I help clients go faster for less using serverless technologies.

When working with AWS Lambda, one of the things to keep in mind is that there’s a per region limit of 75GB total size for all deployment packages. Whilst that sounds a lot at first glance, our small team of server engineers managed to rack up nearly 20GB of deployment packages in just over 3 months!
Whilst we have been mindful of deployment package size (because it affects cold start time) and heavily using Serverless‘s built-in mechanism to exclude npm packages that are not used by each of the functions, the simple fact that deployment is simple and fast means we’re doing A LOT OF DEPLOYMENTS.
Individually, most of our functions are sub-2MB, but many functions are deployed so often that in some cases there are more than 300 deployed versions! This is down to how the Serverless framework deploy functions – by publishing a new version each time. On its own, it’s not a problem, but unless you clean up the old deployment packages you’ll eventually run into the 75GB limit.
Some readers might have heard of Netflix’s Janitor Monkey, which cleans up unused resources in your environment – instance, ASG, EBS volumes, EBS snapshots, etc.
Taking a leaf out of Netflix’s book, we wrote a Lambda function which finds and deletes old versions of your functions that are not referenced by an alias – remember, Serverless uses aliases to implement the concept of stages in Lambda, so not being referenced by an alias essentially equates to an orphaned version.

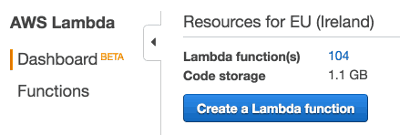
At the time of writing, we have just over 100 Lambda functions in our development environment and around 50 running in production. After deploying the janitor-lambda function, we have cut the code storage size down to 1.1GB, which include only the current version of deployments for all our stages (we have 4 non-prod stages in this account).
sidebar: if you’d like to hear more about our experience with Lambda thus far and what we have been doing, then check out the slides from my talk on the matter, I’d be happy to write them up in more details too when I have more free time.
Janitor-Lambda
Without further ado, here’s the bulk of our janitor function:
Since AWS Lambda throttles you on the no. of APIs calls per minute, we had to store the list of functions in the functions variable so that it carries over multiple invocations.
When we hit the (almost) inevitable throttle exception, the current invocation will end, and any functions that haven’t been completely cleaned will be cleaned the next time the function is invoked.
Another thing to keep in mind is that, when using a CloudWatch Event as the source of your function, Amazon will retry your function up to 2 more times on failure. In this case, if the function is retried straight away, it’ll just get throttled again. Hence why in the handler we log and swallow any exceptions:
I hope you have found this post useful, let me know in the comments if you have any Lambda/Serverless related questions.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.