
Yan Cui
I help clients go faster for less using serverless technologies.

I recently watched an excellent talk by Matt Lavin on optimization tips for Lambda and saw a slide on making DynamoDB use HTTP keep-alive. It reminded me of a conversation I had with Sebastian Cohnen, so I set out to test the effect this simple optimization has.

What is it all about?
As it turns out, Node.js’s default HTTP agent doesn’t use keep-alive and therefore every request would incur the cost of setting up a new TCP connection. This is clearly inefficient, as you need to perform a three-way handshake to establish a TCP connection. For operations that are short-lived (such as DynamoDB operations, which typically complete within a single digit ms) the latency overhead of establishing the TCP connection might be greater than the operation itself.
With the Node.js AWS SDK, you can override the HTTP agent to use for ALL clients with just a few lines of code. You can also override the settings for individual clients too.
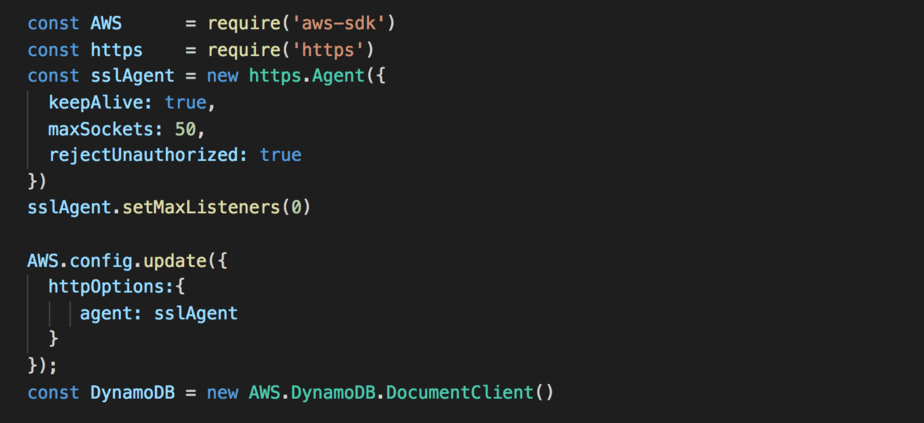
UPDATE 22/09/2019: big thanks to Joe Bowbeer for mentioning this in the comments. Since AWS SDK v2.463.0 you no longer need these couple of lines of code change any more. Instead, set the environment variable AWS_NODEJS_CONNECTION_REUSE_ENABLED to 1 to make the SDK reuse connections by default.
The tests
To test the effect of enabling HTTP keep-alive, I setup a simple Lambda function behind API Gateway. Essentially this function puts an item into a DynamoDB Table, and that’s it.
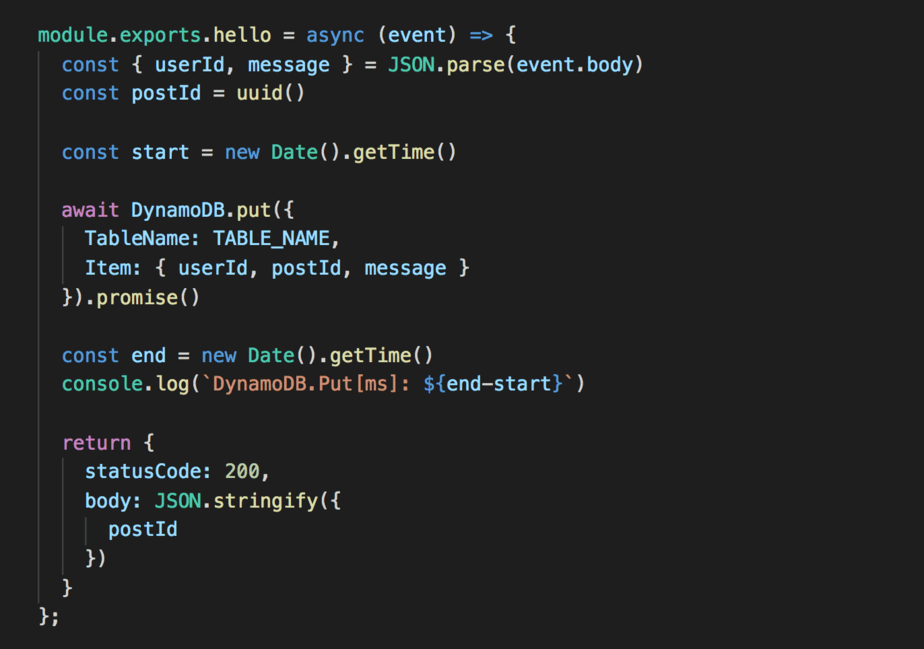
For this experiment, I wanted to see how well the HTTP keep-alive fared across multiple invocations and how much of a difference do we see with this simple change.
The results
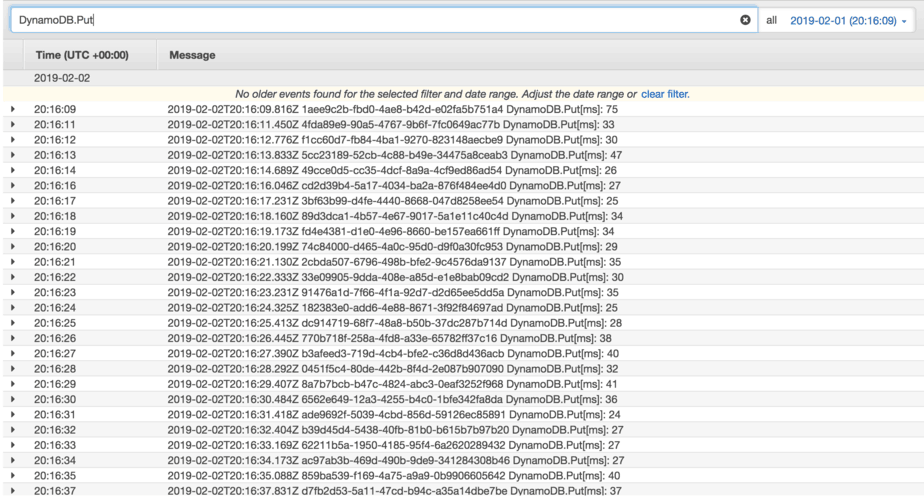
Without HTTP keep-alive, the DynamoDB operation averaged around 33ms.
With HTTP keep-alive, that average drops to around 10ms.
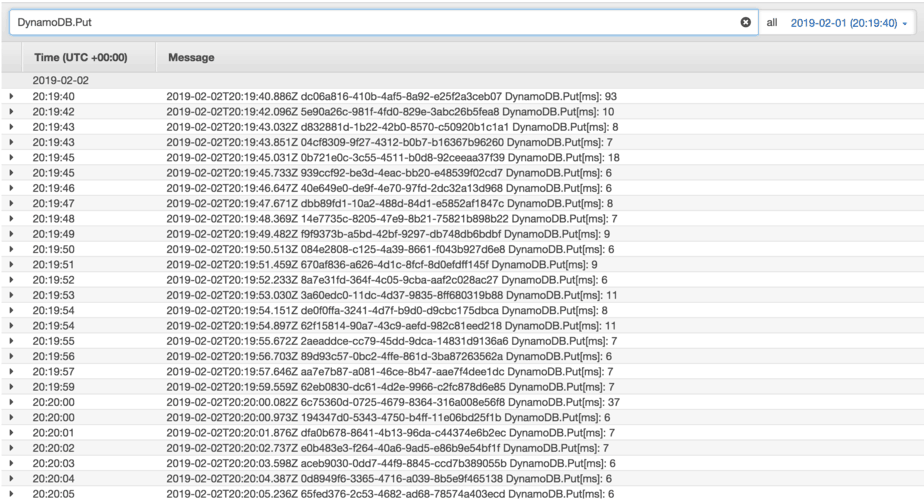
As we suspected, the overhead (33ms-10ms = 23ms) was greater than the cost of the operation itself. The experiment shows that the connection is reused across multiple invocations just fine. With a very simple change, we were able to improve execution time by ~20ms, or to put it more impressively, reduce response time by 70%. That’s good return on investment in my book, but the difference is still not noticeable to the human eye.
But what if we scale this to 10 sequential DynamoDB operations in a single function?
With HTTP keep-alive, the function’s execution time averages around 60ms.
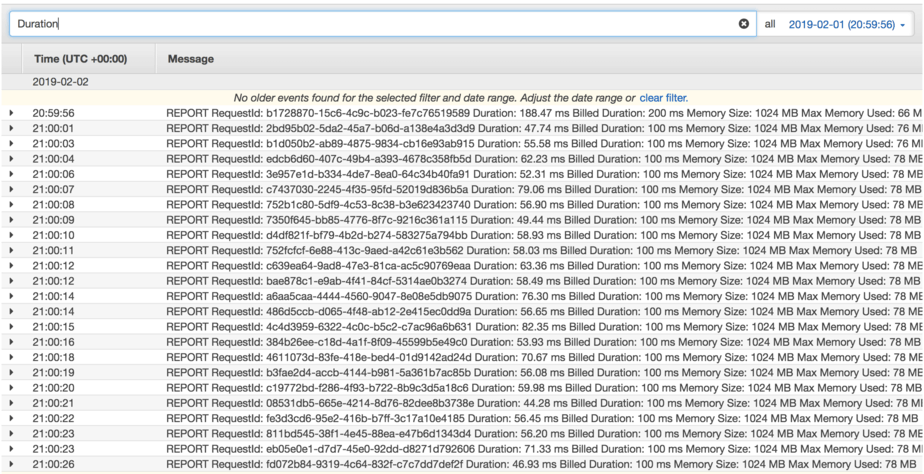
Without HTTP keep-alive, the average execution time rises to 180ms.
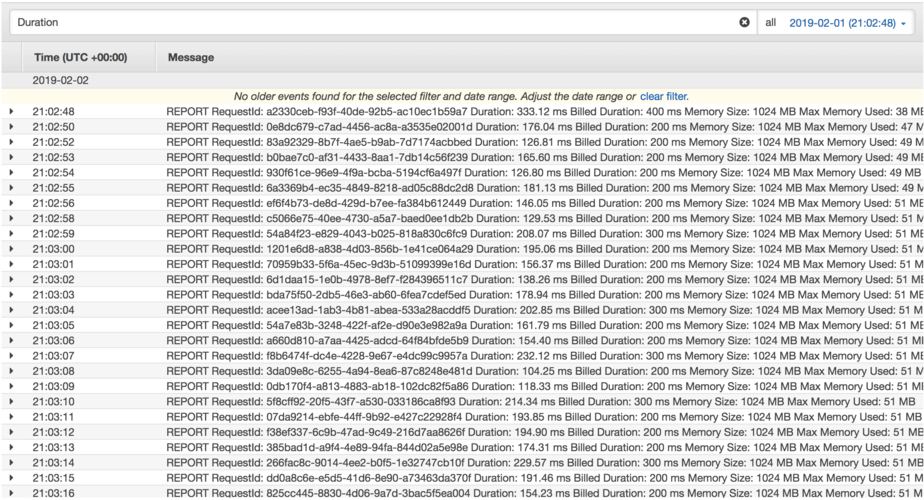
As I curl the endpoint, the difference of 120ms is definitely noticeable. This difference can start to impact user experience, and as Amazon found 10 years ago, adding 100ms of latency can reduce sales by as much as 1%.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.