

Yan Cui
I help clients go faster for less using serverless technologies.

Lambda makes it easy to build event-driven architectures. Each function only needs to look after its own responsibilities. We chain them together through APIs, queues, streams, and other event sources. It’s a good way to build complex systems out of simple components. We need only managed services, and we only pay for them when we use them.
But, sometimes, we make mistakes. A few blog posts had made the rounds on social media a while back. A few people had accidentally got their functions in an infinite recursion. A sizable AWS bill soon followed.
In one incident, S3 triggers a Lambda function which puts a modified file back into the same bucket. Which triggered the same function, which puts the file back into the same bucket. And the cycle continued on and on.
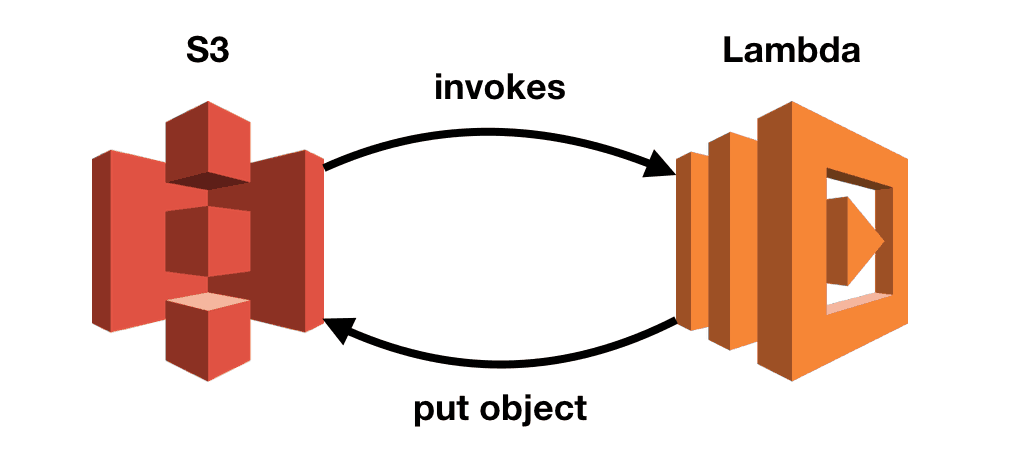
Only if there’s a way to track the number of invocations on a call chain so we can put on a break when it gets too long!
dazn-lambda-powertools
We (at DAZN) recently open-sourced our Lambda powertools project. The goal of the project is to empower our engineers to build production-ready serverless applications. And observability is a big part of that.
The project gives you the tools to automatically extract and forward correlation IDs. It also supports log sampling for the entire call chain. So you’ll always have a sample of debug log messages even when you’re logging at a higher level. In production, you will typically log at WARN or ERROR level to save cost. More details are available here.
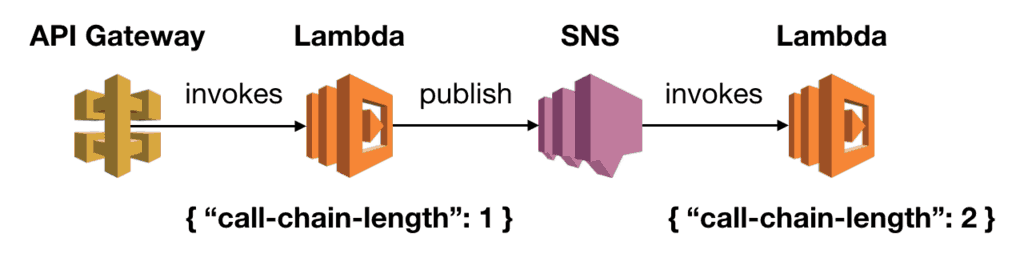
Tracking the length of a call chain
The same mechanisms used to pass correlation IDs along can help track the length of the call chain. All we need is to pass a counter along with the other correlation IDs. Each time we extract the correlation IDs, we will increment the counter by 1.
Stopping infinite loops
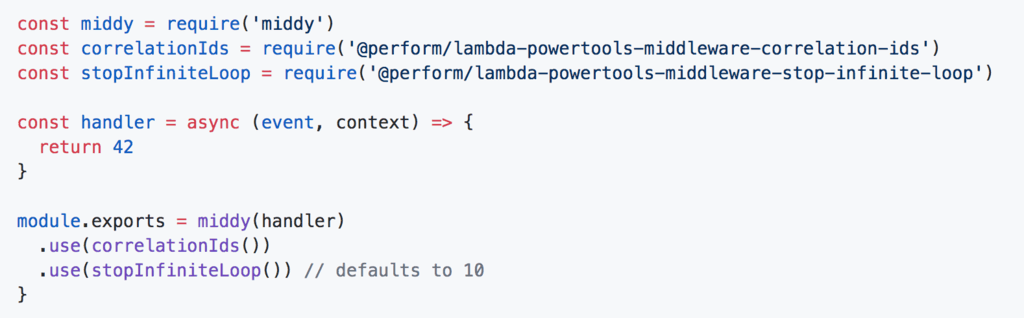
Once we’re able to track the length of call chains, we can stop them when they become too long. We added a middleware to stop invocations when the call chain length reaches a threshold.
Since most call chains are short, the default threshold value is set to 10. But you can override it to suit your needs. You can apply the middleware like any other middy middlewares. And you can also use it in conjunction with other middy middlewares too.
Show me, don’t tell me!
To see this in action, I put together a very simple demo project. The source code is available here.
This demo project consists of a single function, which calls itself every time. This function is missing a termination condition. It will loop indefinitely if left unchecked. Thankfully, the stop-indefinite-loop middleware will stop the call chain on the third invocation.
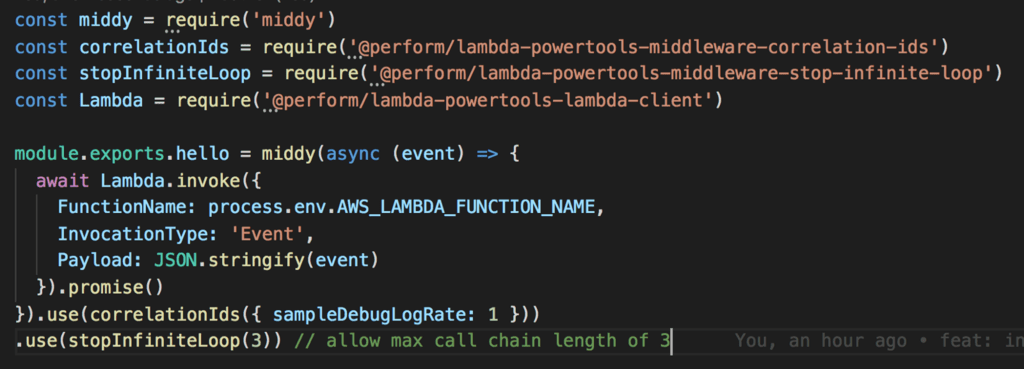
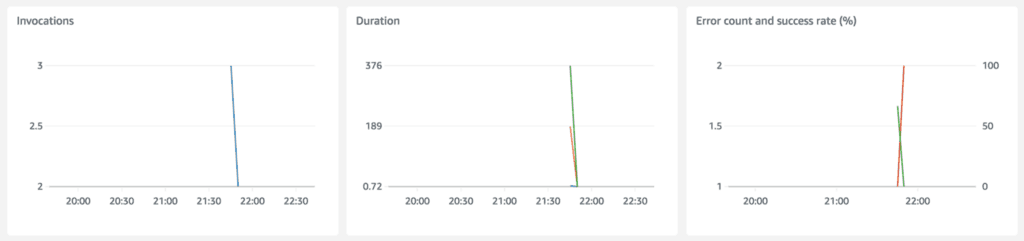
After I triggered the function with sls invoke -f hello I was able to verify the expected behaviour in the logs. On the third recursion, the invocation was stopped dead in its tracks. It even stopped the subsequent retries (Lambda retries failed async invocations twice)!

You can see the invocations were stopped in the metrics as well.
Limitation
The middleware does not work for SQS and Kinesis functions. These event sources send events to Lambda in batches and require special handling. The call chain lengths are still passed along and incremented as you’d expect. But the middleware that stops long call chains does not work here. Instead, you’d need to apply that logic when you process an individual record.
Contributing
We hope these tools would help you in your serverless journey as well. And we welcome your contributions, please feel free to suggest features or report bugs. Please also check out our contribution guide if you want to lend us a hand!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.