

Yan Cui
I help clients go faster for less using serverless technologies.

Caching is still important for serverless architectures. Just because AWS Lambda auto-scales by traffic, it doesn’t mean we can forget about caching. In this post, let’s break down by caching is still relevant for serverless and where we can apply caching in a serverless architecture.
Caching is still VERY relevant.
Yes, Lambda auto-scales by traffic. But it has limits. It takes time to reach your peak throughput.
This is not a problem if your traffic is either very stable or follows the bell curve so there are no sudden spikes.
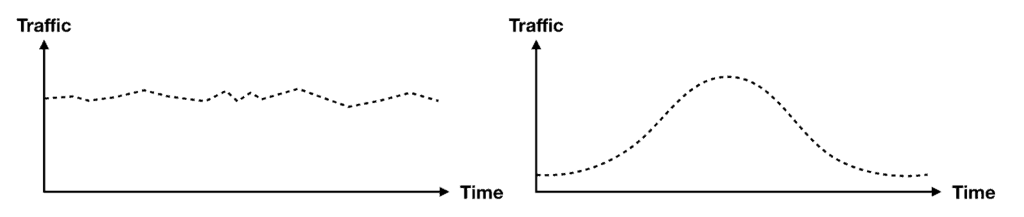
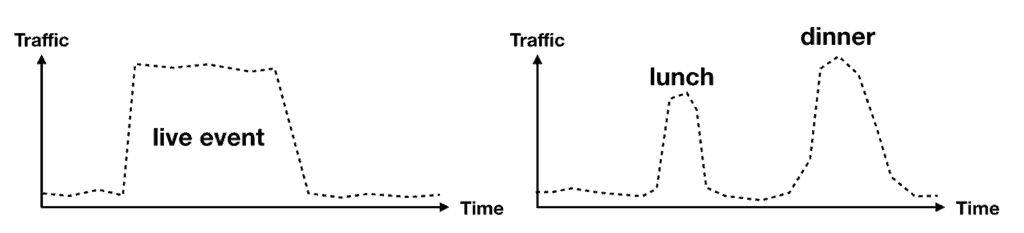
However, if your traffic is very spiky, then you can still run into the various scaling limits:
- There is a region-wide account concurrency limit.
- Individual functions can scale up by 1000 concurrent executions every 10 seconds.
- If you have reserved concurrency configured on a function.
These limits can impact businesses that are prone to seeing large spikes in user traffic. For instance, if you are streaming live events to millions of users or you’re in the food delivery service. In both cases, caching must be an integral part of your application.
There’s the question of performance and cost efficiency.
Caching improves response time as it cuts out unnecessary roundtrips.
In the case of serverless, this also translates to cost savings as most of the technologies we use are pay-per-use. So, fewer requests directly translate to cost savings from requests that we didn’t have to process.
Where should you implement caching?
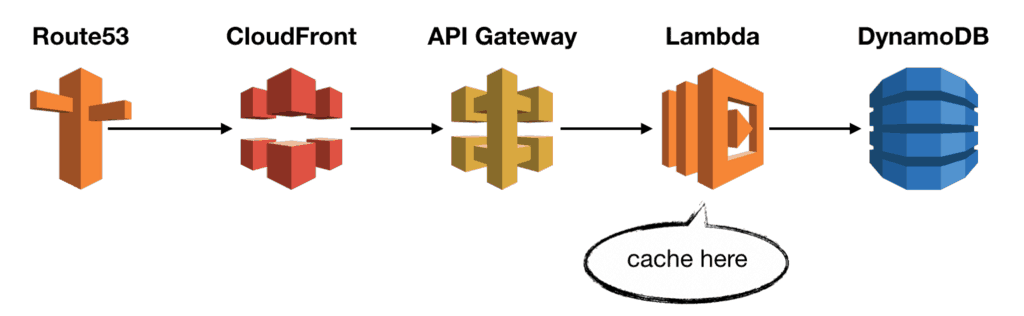
A typical REST API might look like this:
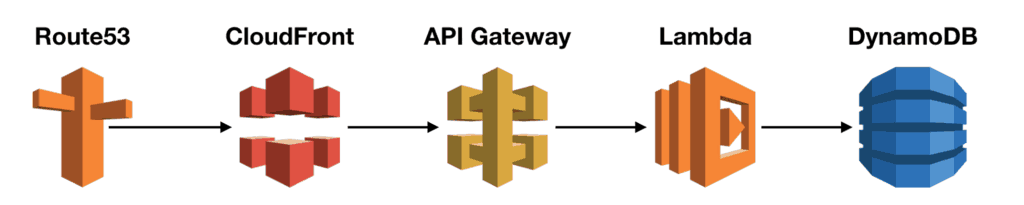
You have:
- Route53 as the DNS.
- CloudFront as the CDN.
- API Gateway to handle authentication, rate limiting and request validation.
- Lambda to execute business logic.
- DynamoDB as the database.
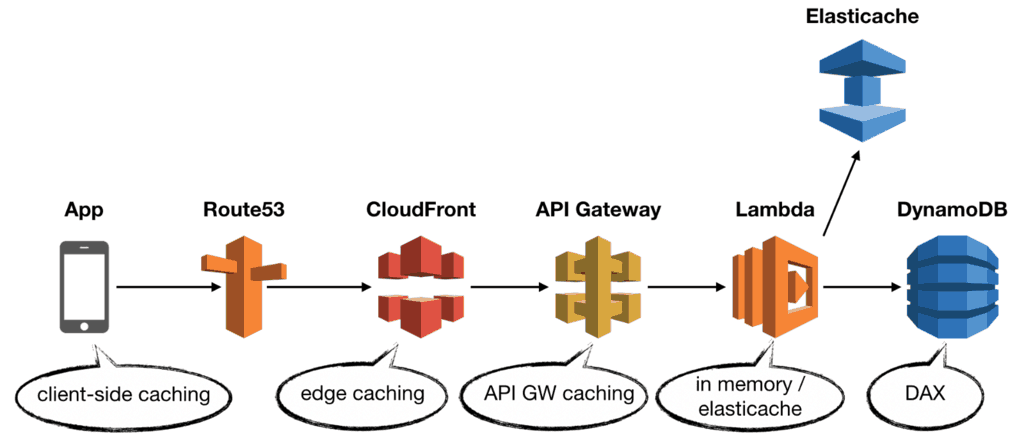
In this very typical setup, you can implement caching in several places. My general preference is to cache as close to the end-user as possible, maximising your caching strategy’s cost-saving benefit.
Caching in the client app
Given the option, I will always enable caching in the web or mobile app.
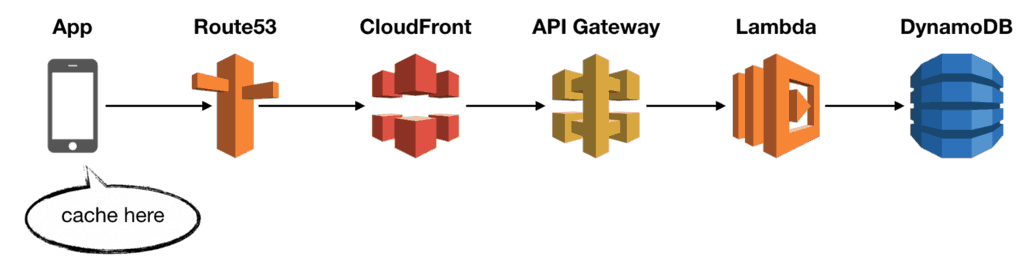
This is very effective for data that are immutable or seldom change. For instance, browsers cache images and HTML markups to improve performance. The HTTP protocol has a rich set of headers to let you fine-tune the caching behaviour.
Often, client-side caching can be implemented easily using techniques such as memoization and encapsulated into reusable libraries.
However, caching data on the client side means responding to at least one request per client. This is still very inefficient, and you should also cache responses on the server side.
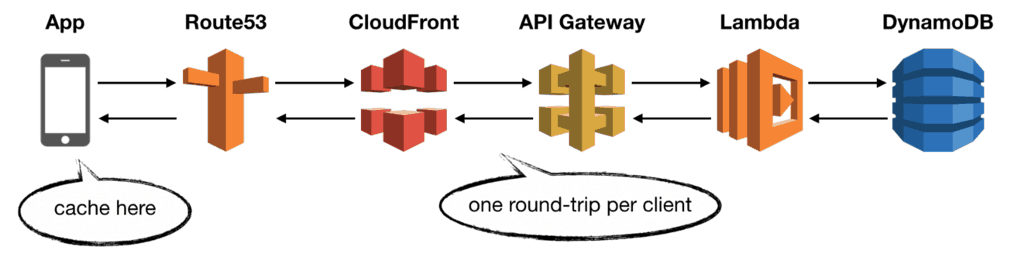
Caching at CloudFront
CloudFront has a built-in caching capability. It’s the first place you should consider caching on the server side.
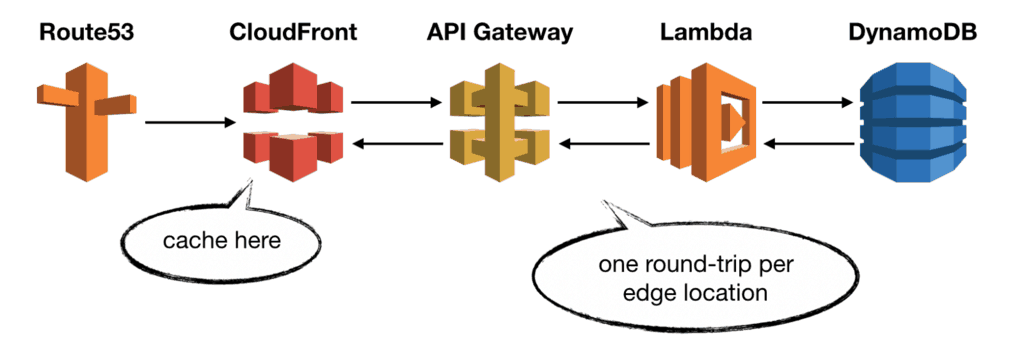
Caching at the edge is very cost-efficient as it cuts out most of the calls to API Gateway and Lambda. Skipping these calls also improves the end-to-end latency and, ultimately, the user experience.
Also, by caching at the edge, you don’t need to modify your application code to enable caching.
CloudFront supports caching by query strings, cookies and request headers [1]. It even supports origin failover [2], which can improve system uptime.
In most cases, this is the only server-side caching I need.
Caching at API Gateway
CloudFront is great, but it, too, has limitations. For example, CloudFront only caches responses to GET, HEAD, and OPTIONS requests. If you need to cache other requests, you need to cache responses at the API Gateway layer instead.
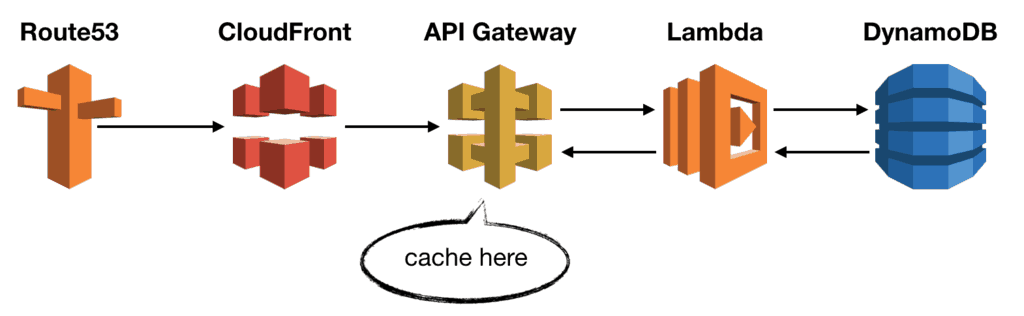
With API Gateway caching, you can cache responses to any request, including POST, PUT and PATCH. However, this is not enabled by default [3].

You also have a lot more control over the cache key. For instance, if you have an endpoint with multiple path and/or query string parameters, e.g.
GET /{productId}?shipmentId={shipmentId}&userId={userId}
You can choose which path and query string parameters are included in the cache key. In this case, it’s possible to use only the productId as the cache key. So, all requests to the same product ID would get the cached response, even if shipmentId and userId are different.
One downside to API Gateway caching is that you switch from pay-per-use pricing to paying for uptime. Essentially, you’ll be paying for the uptime of a Memcached node (that API Gateway manages for you).
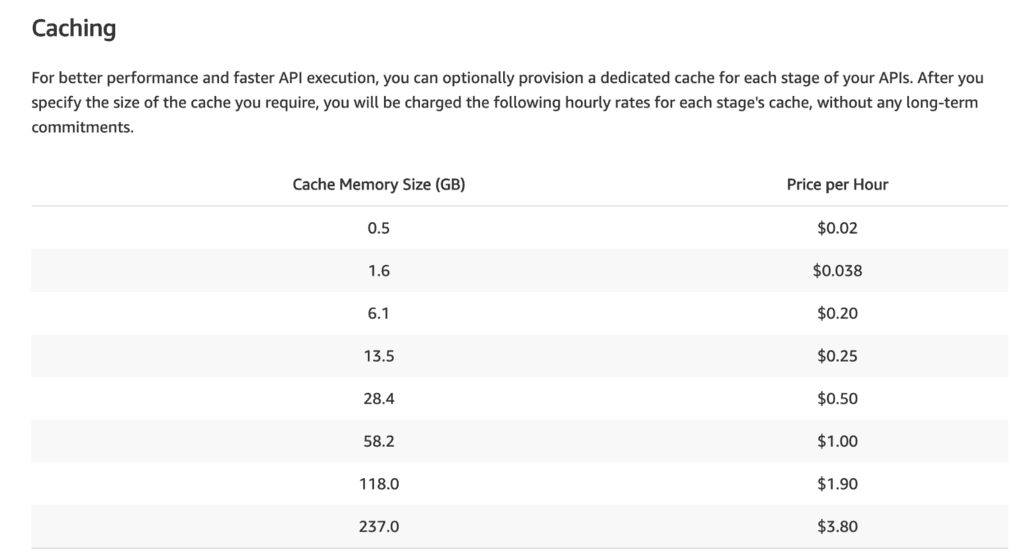
API Gateway caching is powerful, but I have found few use cases for it. My main use case is for caching POST requests.
Caching in the Lambda function
You can also cache data in the Lambda function. Anything declared outside the handler function is reused between invocations.
let html; // this is reused between invocations
const loadHtml = async () => {
if (!html) {
// load HTML from somewhere
// this is only run during cold start and then cached
}
return html
}
module.exports.handler = async (event) => {
return {
statusCode: 200,
body: await loadHtml(),
headers: {
'content-type': 'text/html; charset=UTF-8'
}
}
}
Once created, an execution environment is reused to handle subsequent requests. You can take advantage of this and cache any static configurations or large objects in the Lambda function. This is indeed one of the recommendations from the official best practices guide [4].

However, the cached data is only available for that execution environment, and there’s no way to share it with others. This means the overall cache miss can be pretty high – the first call in every execution environment will be a cache miss.
Distributed cache
Alternatively, you can cache the data in a distributed cache instead. Doing so would allow cached data to be shared across many functions.
Elasticache requires your functions to be inside a VPC, and you must pay for uptime [5] for the Elasticache cluster.
A more serverless solution would be to use Momento [6] instead. Their serverless caching solution means no VPC and no need to manage cache nodes! They also have an on-demand pricing plan that is free for the first 5 GB and only $0.5 per GB thereafter.
However, introducing an external caching solution like Elasticache or Momento would require changes to your application code for both reads and writes.
If you use DynamoDB, then you can also use DAX as a convenient way to add caching to your application and reduce the read & write costs of DynamoDB (which needs to be weighed against the cost of DAX itself).
DAX
DAX lets you benefit from Elasticache without running it yourself. You still have to pay for uptime for the cache nodes, but DynamoDB fully manages them.
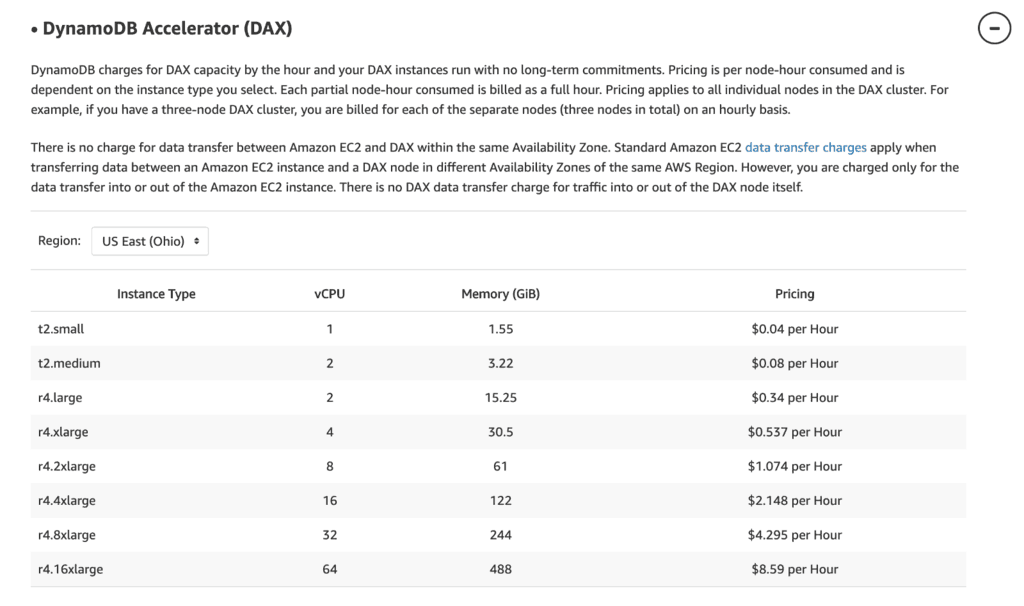
The great thing about DAX is that it requires minimal change from your code. My main issue with DAX is its caching behaviour [7] regarding query and scan requests. In short, queries and scans have their own caches, and they’re not invalidated when the item cache is updated. This means they can return stale data immediately after an update.

Summary
To summarise, caching is still an important part of any serverless application. It improves your application’s scalability and performance and helps you keep your costs in check even when you have to scale to millions of users.
As discussed in this post, you can implement caching in every application layer. You should implement client-side caching and cache API responses at the edge with CloudFront as much as possible. When edge caching is not possible, move the caching further into your application to API Gateway, then Lambda or DAX.
If you’re not using DynamoDB or you need to cache data composed of different data sources, consider introducing Elasticache or Momento to the application.
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications, check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you complete, end-to-end training on building serverless applications for the real world. I will take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Links
[1] CloudFront – caching content based on request headers
[2] Optimizing high availability with CloudFront origin failover
[3] Enabling API caching to enhance responsiveness
[4] Official best practices guide for working with AWS Lambda
Related Posts


Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.