

Yan Cui
I help clients go faster for less using serverless technologies.

TL;DR – Lambda-to-Lambda calls are generally a bad idea except for some select use cases, such as:
- You’re running the Apollo server in a Lambda function.
- To offload secondary responsibilities to another function by invoking asynchronous (that is, using Event as InvocationType).
Avoid synchronous lambda-to-lambda calls
If you utter the words “I call a Lambda function from another Lambda function” you might receive a bunch of raised eyebrows. It’s generally frowned upon for some good reasons, but as with most things, there are nuances to this discussion.
In most cases, a Lambda function is an implementation detail and shouldn’t be exposed as the system’s API. Instead, they should be fronted with something, such as API Gateway for HTTP APIs or an SNS topic for event processing systems. This allows you to make implementation changes later without impacting the external-facing contract of your system.
Maybe you started off with a single Lambda function, but as the system grows you decide to split the logic into multiple functions. Or maybe the throughput of your system has reached such a level that it makes more economical sense to move the code into ECS/EC2 instead. These changes shouldn’t affect how your consumers interact with your system.
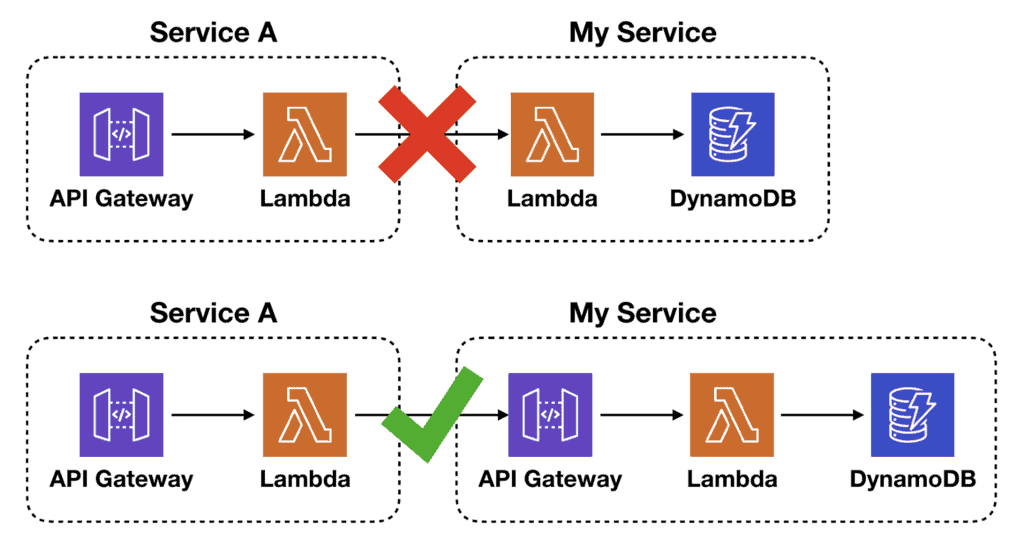
A Lambda function is not a stable interface. The caller needs to know its name, its region and its AWS account. This stops me from refactoring my service without forcing the callers to change, hence creating tight coupling between services.
Amongst other things, I cannot:
- Rename a function.
- Split a fat Lambda (e.g. one that handles all CRUD actions against one entity type) into single-purpose functions.
- Go multi-region, and route requests to the closest region.
- Move the service to another account (e.g. if you’re migrating from a shared AWS account to having separate accounts per team)
In all of these cases, if there’s an API Gateway in front of my service, then, by and large, I can refactor my service without impacting my callers. p.s. I’m only talking about refactoring here, that is, changes that don’t affect the contract with my callers.
If I’m making breaking contract changes then it’s unavoidable that my callers have to make changes too. I avoid these breaking changes like a plague, especially when the cost of cross-team coordination is high.
It’s also worth noting that while API Gateway is a more stable interface for synchronous calls that cross the service boundary, the same logic can be applied to SNS/SQS/EventBridge for asynchronous calls between Lambda functions.
Context Matters
But as with all things, this is not a hard-and-fast rule. There are always exceptions and reasons to break from the mould if you understand the tradeoffs you’re making. But the most important thing to consider here is the organizational environment you operate in.
An important factor to consider is “how expensive is the communication channel between the two teams”.
The bigger the company, the higher these costs tend to be. I’ve seen projects delayed for months or even years because of these cross-team dependencies. And the higher these costs are the more you need to have a stable interface between services. A stable interface affords you more flexibility to make changes without breaking your contract with other teams.
Earlier, I said that you shouldn’t call Lambda functions across service boundaries. This stems from the fact that it creates a tight coupling between services and changes can incur a large communication cost.
But what if you are a small team (or working on your own) and the cost of coordinating changes across services is negligible?
Then maybe you don’t need the flexibility a more stable interface can give you. In which case it’s not a problem to call a Lambda function directly across service boundaries. And what you lose in flexibility you gain in performance and cost efficiency as you cut out a layer from the execution path.
For internal services, you can also use Lambda Function URLs with custom domain names in CloudFront. The custom domain name provides a more stable interface without the overhead and cost of API Gateway. It can be a good compromise solution, provided that Function URL meets your authentication and authorization needs.
To learn more about Function URLs and when to use them, check out this video [1] I made on the topic.
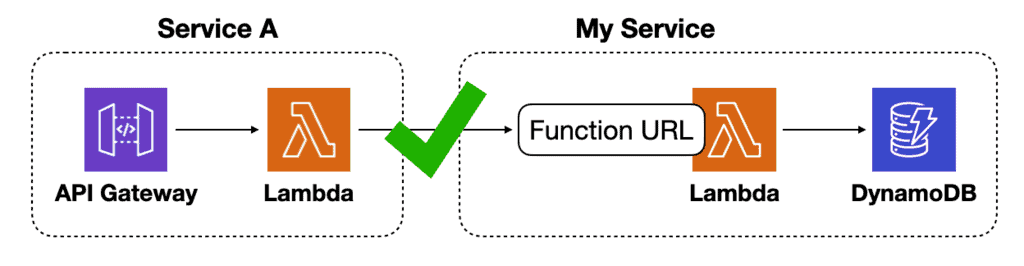
An alternative, more relaxed rule could be to avoid synchronous lambda-to-lambda calls “across ownership lines“.
There are also other exceptions to keep in mind. For example, if you are running GraphQL in a Lambda function, then you do need to make synchronous calls to other resolver Lambda functions. Without this, you’d have to put the entire system into a very fat Lambda function! That’d likely cause far more problems for you than those synchronous Lambda calls.
I prefer to use AppSync for building GraphQL APIs on AWS. If you’re interested in the trade-offs between AppSync and running Apollo in Lambda function then check out this video [2].
Lambda-to-Lambda within a service
But what if the caller and callee functions are both inside the same service? In this case, the whole “breaking the abstraction layer” thing is not an issue. Are Lambda-to-Lambda calls OK then?
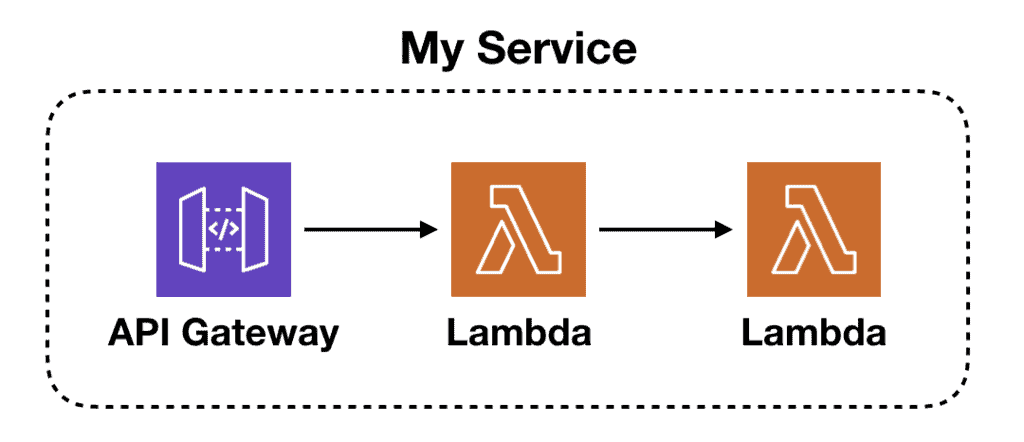
It depends. There’s still an issue of efficiency to consider.
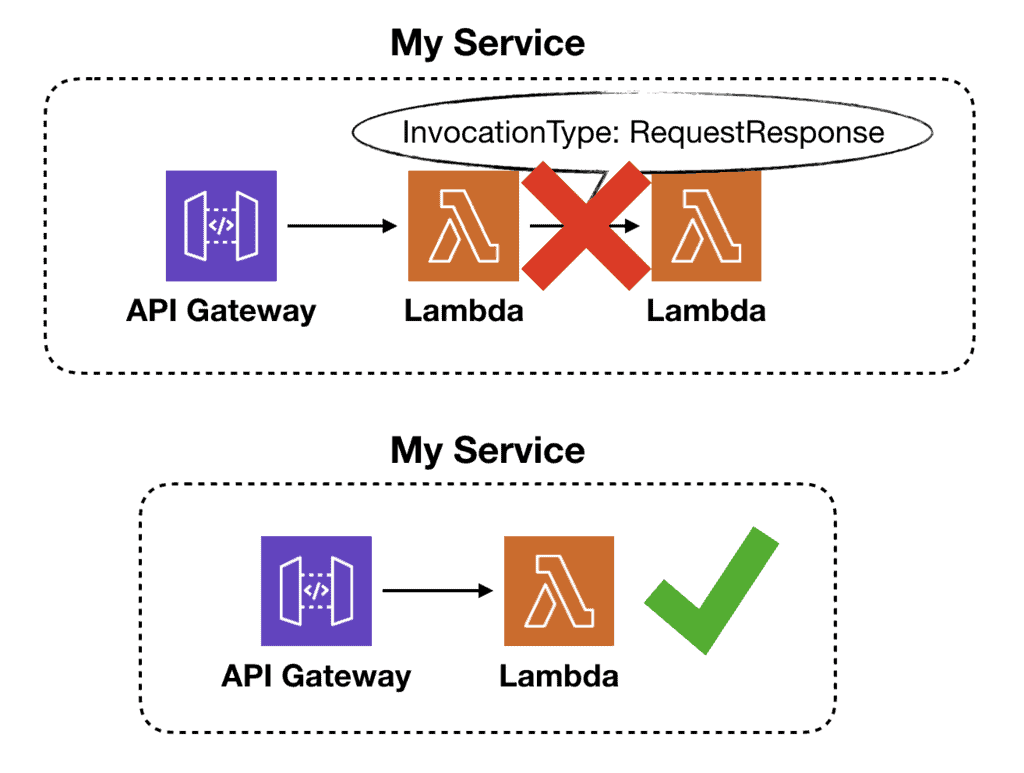
If you’re invoking another Lambda function synchronously (i.e. when InvocationType is RequestResponse ) then you’re paying for extra invocation time and cost:
- There is latency overhead for calling the 2nd function, especially when a cold start is involved. This impacts the end-to-end latency.
- The 2nd Lambda invocation carries an extra cost for the invocation request.
- You will pay for the idle wait time while the caller function waits for a response from the callee. Essentially, you’re paying for the execution time for the 2nd function twice!
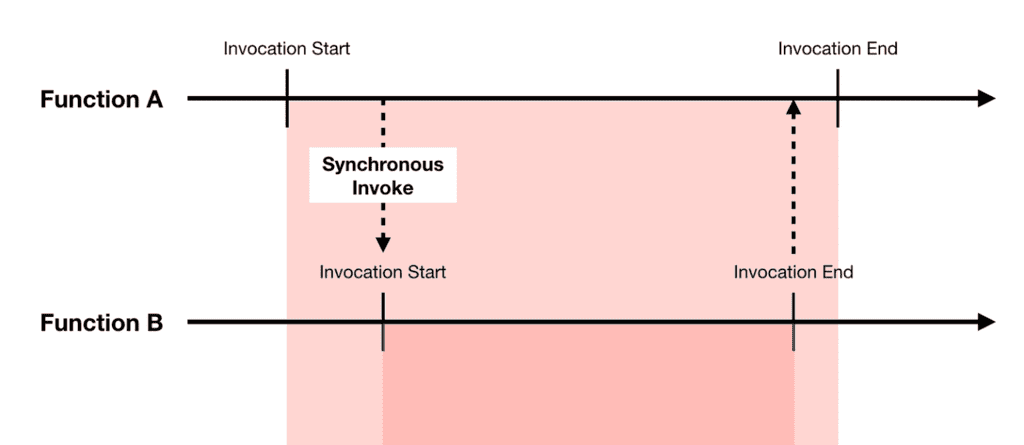
While the extra cost might be negligible in most cases, the extra latency is usually undesirable, especially for user-facing APIs.
If you care about either, then you should combine the two functions into one. You can still achieve separation of concerns and modularity at the code level. You don’t have to split them into separate Lambda functions.
Async Lambda-to-Lambda calls
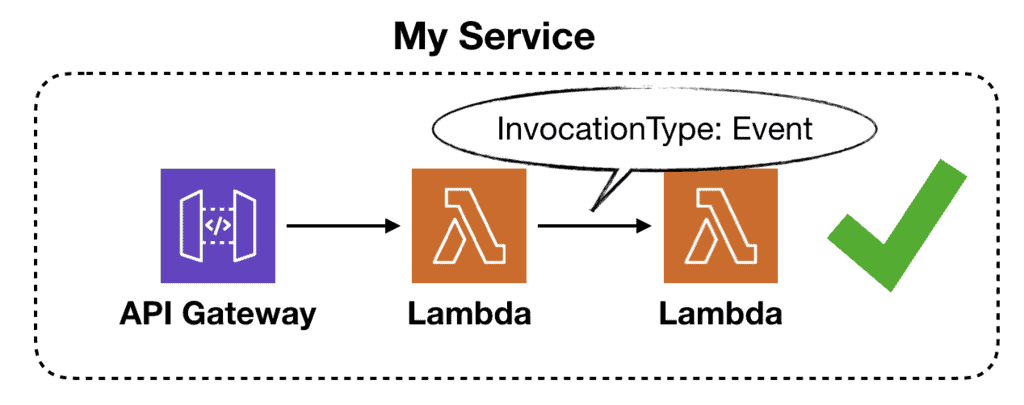
But, if the goal is to offload some work so the calling function can return earlier then I don’t see anything wrong with that.
That is, assuming both functions are part of the same service and the second function is invoked asynchronously.
As a rule of thumb, you should ALWAYS have an on-failure destination for any async functions.
Also, you may still put something between these two functions to regulate concurrency. For example, using SQS or Kinesis allows these tasks to be processed in batches and to amortize traffic spikes. This is especially important when dealing with downstream systems that aren’t as scalable as Lambda.
In this case, you can use Lambda’s scaling behaviour with other event sources to regulate the concurrency of the callee function. Check out this video [2] on how to control Lambda concurrency.
Summary
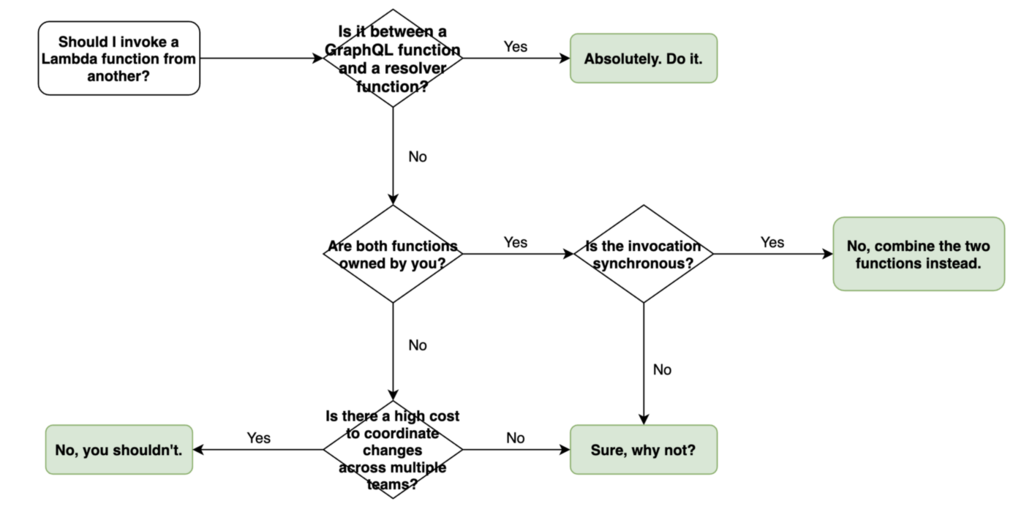
So, to answer the question posed by the title of this post – it depends! And to help you decide, here’s a decision tree for when you should consider calling a Lambda function directly from another.
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications then check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Links
[1] When to use Lambda Function URLS?
[2] AppSync vs running Apollo in Lambda
[3] How to achieve concurrency control with AWS Lambda
Related Posts
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.