
Yan Cui
I help clients go faster for less using serverless technologies.

I have been working on a large AppSync project for a client these past few months. The initial version of the app was built in just a few weeks, but the client has commissioned additional features and the project has kept growing. At the time of writing, this project has over 200 AppSync resolvers and 600 CloudFormation resources.
Along the way, I learnt a few things about scaling a large AppSync project like this and hope you find them useful too.
But first, let me catch you up on where we are in the project:
- I’m the only backend developer on this project.
- This project uses 100% serverless components – AppSync, DynamoDB, Lambda, S3, etc.
- There is a monorepo for the entire backend for the app.
- There is one Serverless framework project (as in, one
serverless.yml) in the repo, and one CI/CD pipeline. - This
serverless.ymlcontains every backend infrastructure – AppSync APIs, DynamoDB tables, S3 buckets, Lambda functions, etc. - The project uses the serverless-appsync-plugin to configure the AppSync APIs.
- There are two AppSync APIs – one for the mobile app and one for a browser-based CMS system.
- There are two Cognito User Pools – one for the mobile app and one for the CMS.
- There are a total of 26 DynamoDB tables. There is one table per entity, with a few exceptions where I applied Single Table Design for practical reasons.
This might be very different from how your projects are set up. Every decision I made here is to maximize feature velocity for a small team. The client is a bootstrapped startup and cannot afford a protracted development cycle.
If you want to learn more about this project and how I approach it from an architectural point-of-view, please watch this talk:
On a high-level, the backend infrastructure consists of these components:
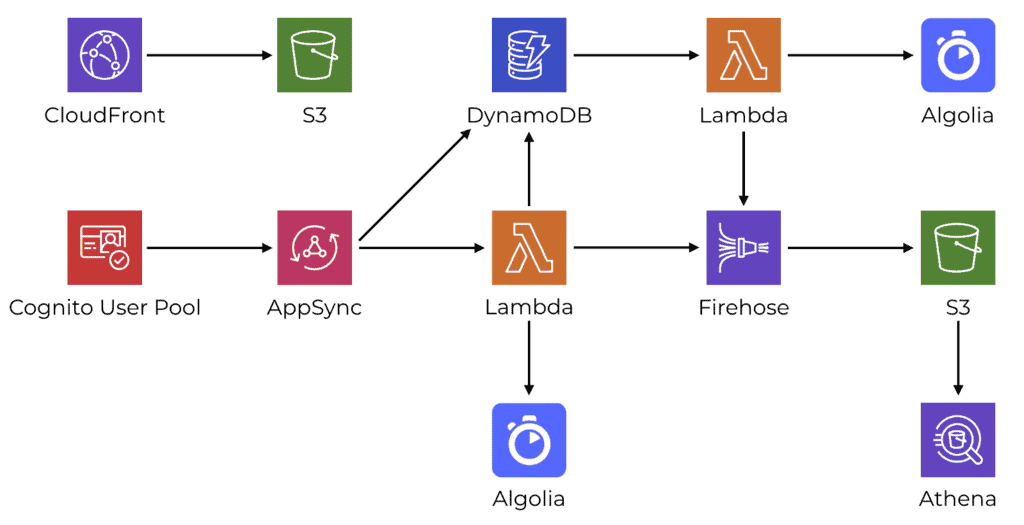
- CloudFront and S3 for hosting static assets.
- Cognito User Pool for authentication and authorization.
- AppSync mostly integrates directly with DynamoDB tables. But more complex operations are moved into Lambda functions instead.
- Algolia for search. It’s the closest thing (that I have found) to a “serverless ElasticSearch”.
- DynamoDB Streams are used to trigger Lambda functions to perform background tasks such as synching changes to Algolia.
- Firehose is used to collect BI (business intelligence) events and stores them in S3.
- Athena is used to run reports against these BI events.
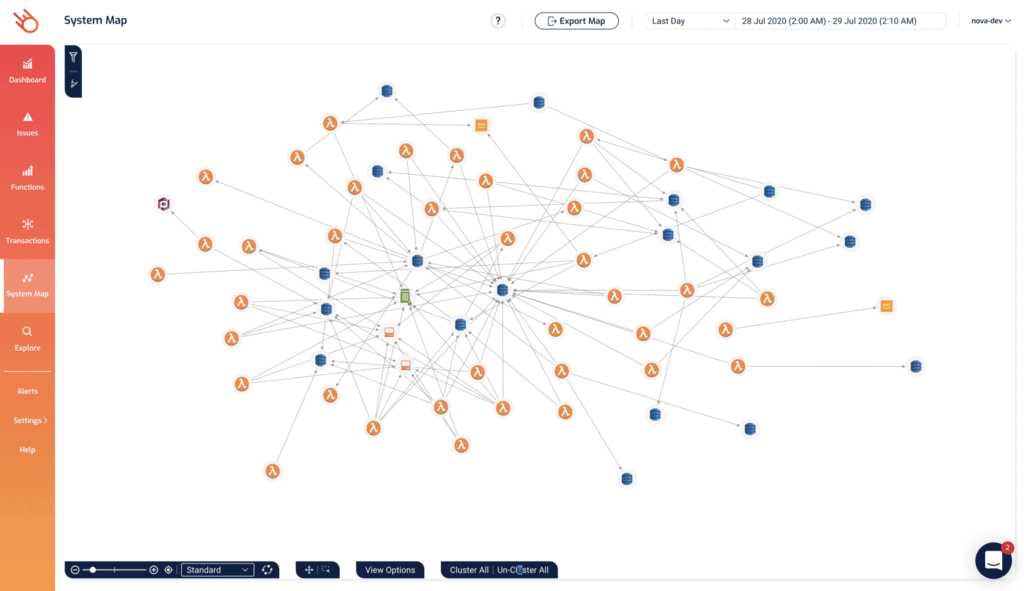
Even though AppSync integrates with DynamoDB directly in most cases, there are still quite a few Lambda functions in the project. As you can see from the System Map in Lumigo.
In the Beginning
At first, everything was in one CloudFormation stack and it didn’t take long before I hit CloudFormation’s 200 resources limit per stack.
Since I’m using the Serverless framework, I can use the split-stacks plugin to migrate resources into nested stacks.
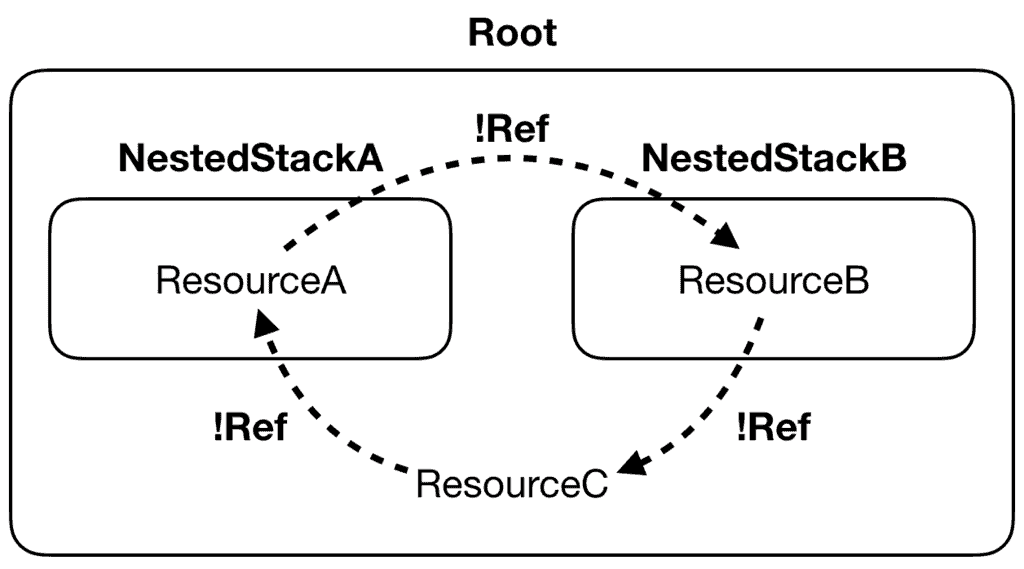
The advantage of this approach is that it doesn’t require any code change to my serverless.yml. Existing references through !Ref and !GetAtt still work even when the resources have been moved around.
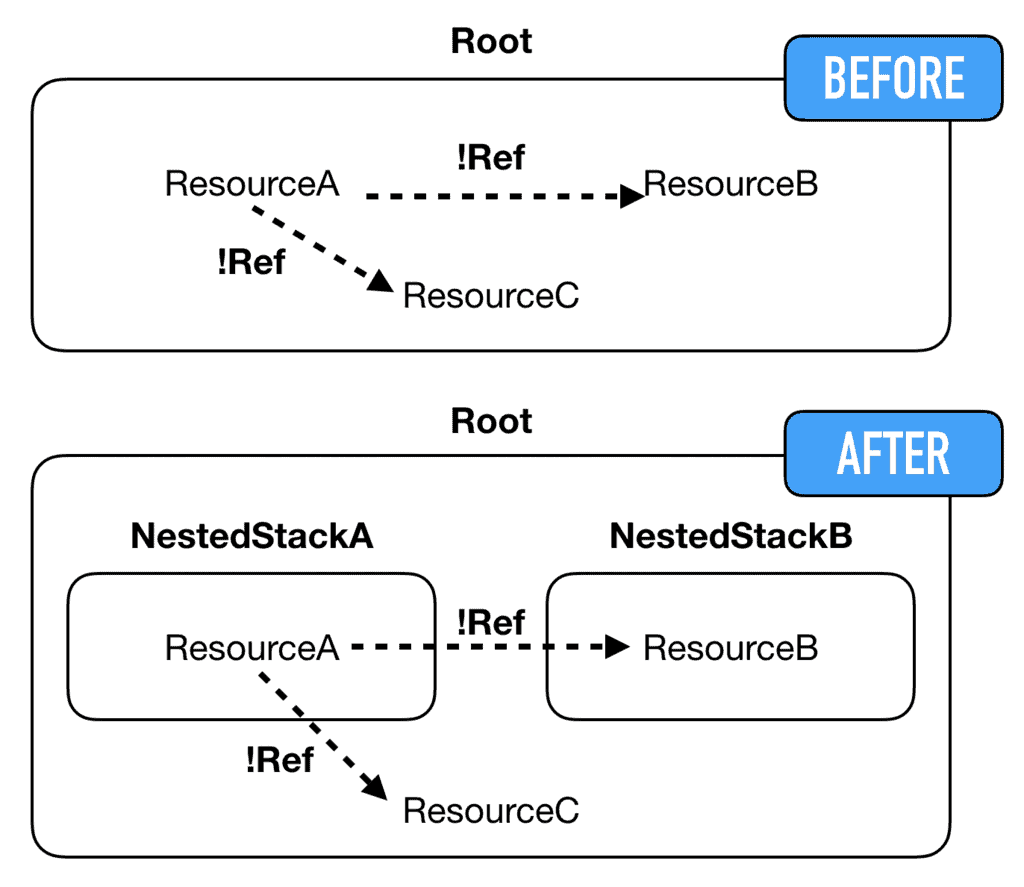
The split-stacks plugin converts these references into CloudFormation Parameters in the nested stack where the references originate from (let’s call this NestedStackA):

If the referenced resources are defined in the root stack, then they are passed into the nested stack as parameters.

If the referenced resources are defined in another nested stack (let’s call this NestedStackB), then the referenced values are included in the Outputs of NestedStackB. The root stack would use GetAtt to pass these outputs as parameters to NestedStackA.
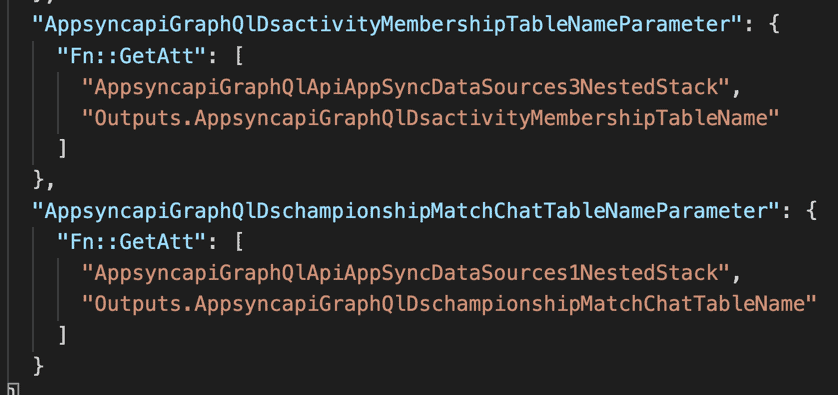
In the generated CloudFormation template, this is what it looks like. Here the root stack passes the output from one nested stack as a parameter to another.
The plugin has a number of built-in migration strategies – Per Lambda, Per Type and Per Lambda Group.
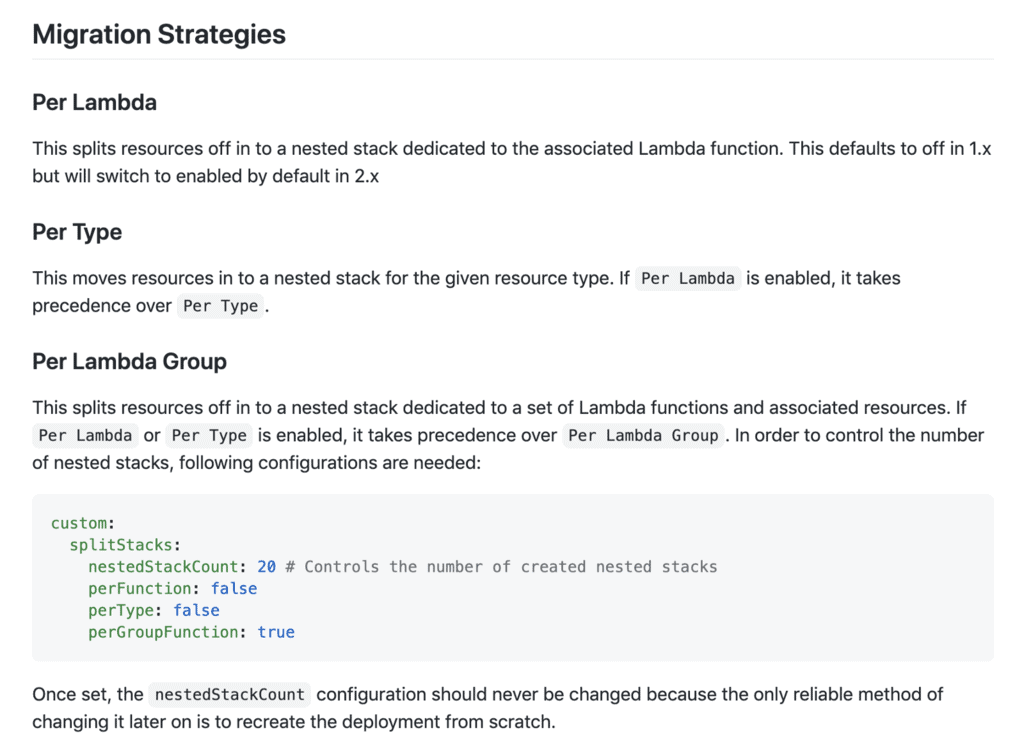
However, I needed more control of the migration process to avoid circular dependencies. Fortunately, the plugin gives me fine-grained control of the migration process by adding a stacks-map.js module at the root of the project.
Beware of Circular References
How you organize the resources into nested stacks is important. There are ample opportunities for circular references to happen.
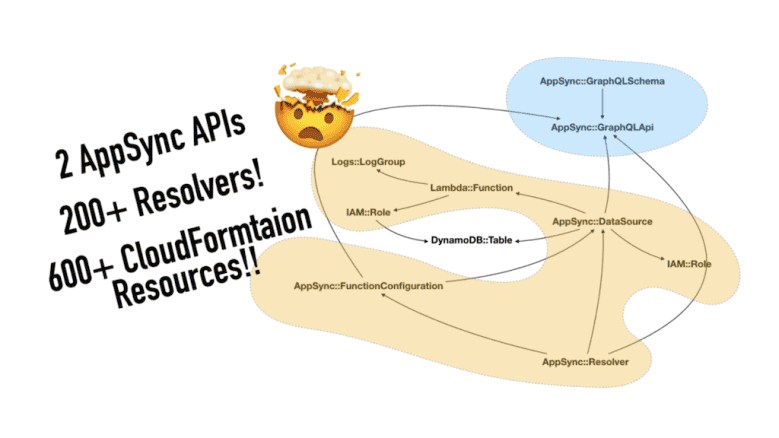
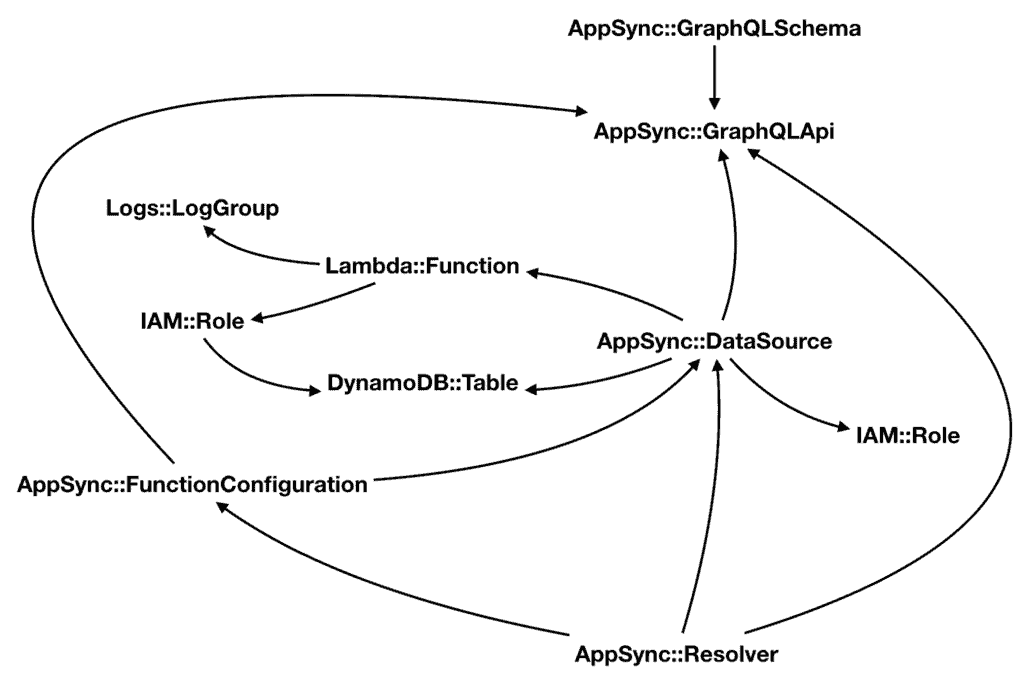
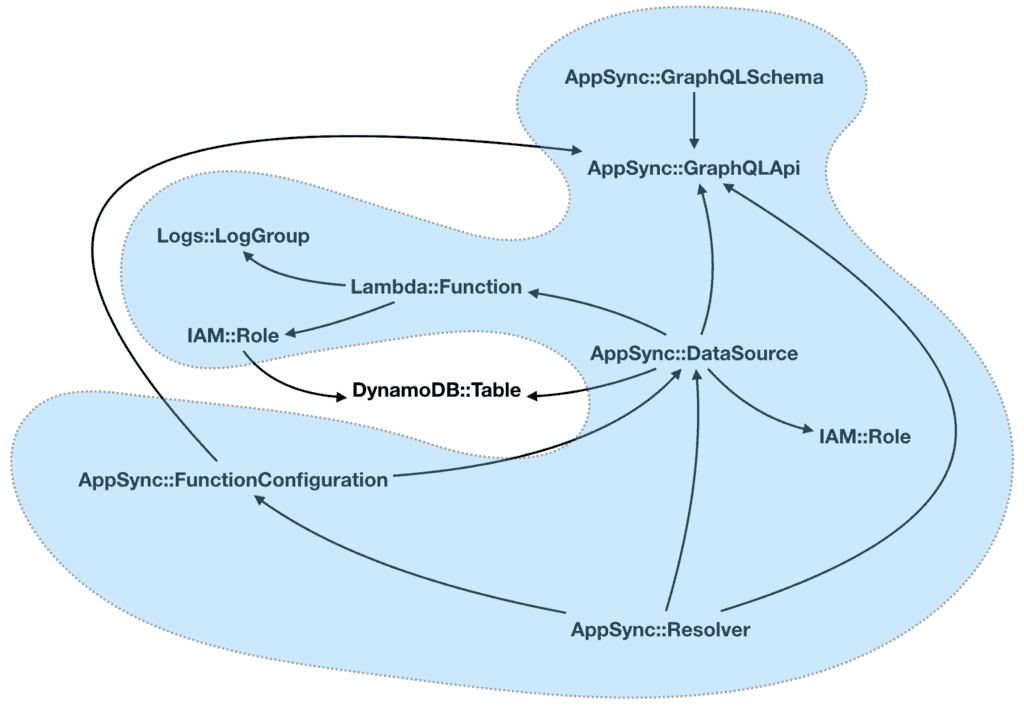
This is especially true when you’re working with AppSync as there are quite a few different types of resources involved. For example, AWS::AppSync::DataSource references Lambda functions or DynamoDB tables, and also references the AWS::AppSync::GraphQLApi for ApiId.

All and all, these are the resource types I have for the AppSync APIs. The arrows represent the direction of the reference.
As the project grew, I had to get creative about how I group the resources into nested stacks. This post describes the 3 stages of that evolution.
Stage 1 – group by API
As a first attempt, I sliced up the resources based on the AppSync API they belong to. The DynamoDB tables are kept in the root stack since they are shared by the two AppSync APIs. Other than that, all the other resources are moved into one of two nested stacks (one for each AppSync API).
Additionally, the split-stacks plugin automatically puts the AWS::Lambda::Version resources into its own nested stack.
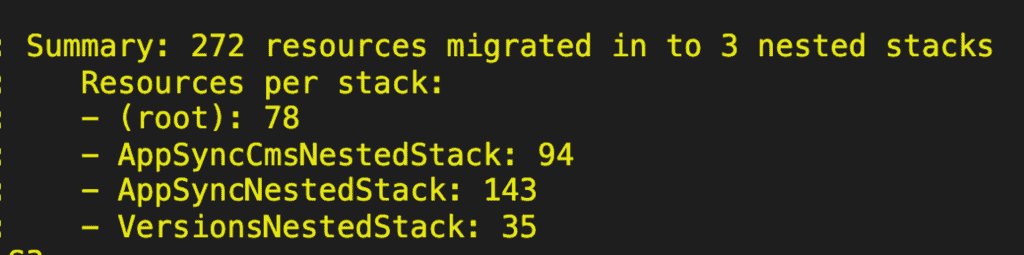
This was the simplest and safest approach I could think of. There was no chance for circular dependencies since the two nested stacks are independent of each other. Although they both reference the same DynamoDB tables in the root stack, there are no cross-references between themselves.
But as you can see from the screenshot above, there are a lot more resources in the AppSyncNestedStack than the AppSyncCmsNestedStack. Pretty soon, the nested stack for the AppSync API for the mobile app would grow too big.
Stage 2 – moving Lambda functions out
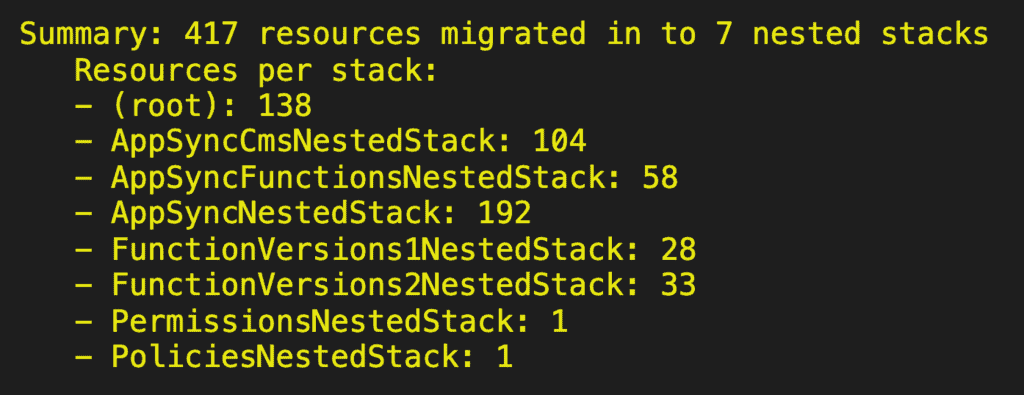
The AppSyncNestedStack contains a lot of resources related to its Lambda functions. So the natural thing to do next was to move the Lambda function resources out into their own nested stack.
This made a big difference and allowed the project to grow much further. But soon, I hit another CloudFormation limit – a stack can have only 60 parameters and 60 outputs.
This was because the project now has over 60 Lambda functions. So the VersionsNestedStack had over 60 AWS::Lambda::Version resources, each requiring a reference to the corresponding AWS::Lambda::Function. Therefore, the stack had over 60 parameters, one for every function.
And so I also had to split the VersionsNestedStack in two.
This bought me time, but the project kept growing…
As the AppSync API for the mobile app approach 150 resolvers, the AppSyncNestedStack hit the 200 resources limit again.
Stage 3 – group by DataSource
From here on, I need to find a strategy that minimizes the number of cross-stack references so to not run foul of the 60 parameters limit per stack. Therefore, each nested stack needs to be as self-contained as possible.
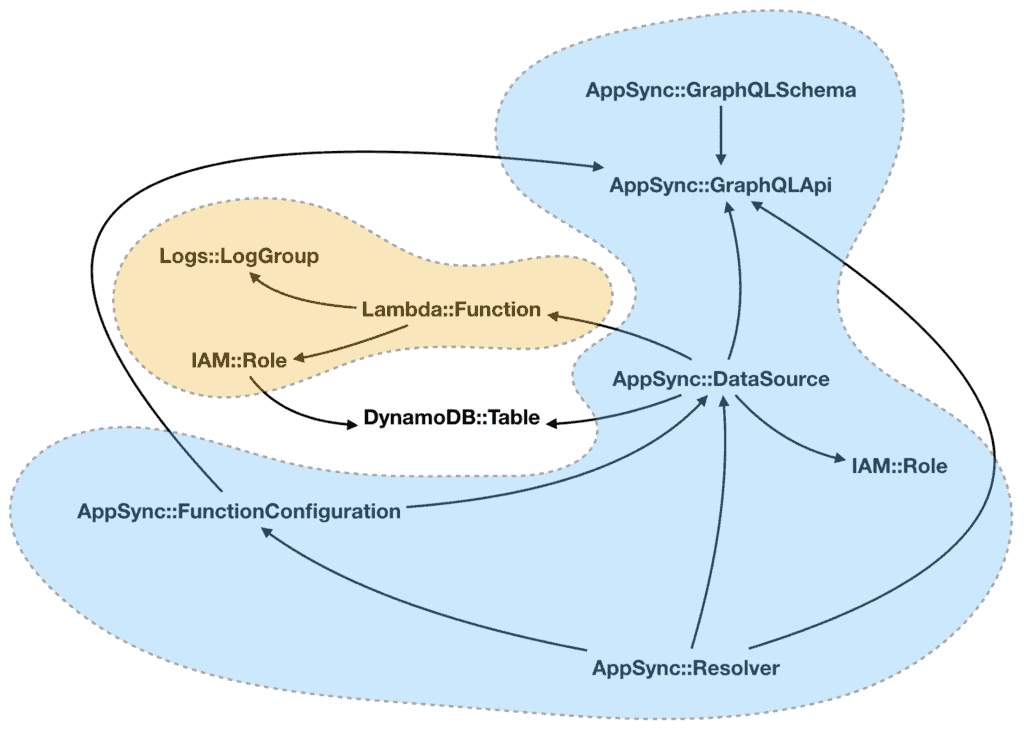
Looking at the resource graph, I realised that the data sources are at the centre of everything. If I start from the data sources, I can create groups of resources that revolve around a single data source (the orange resources below) and are independent of other such groups.
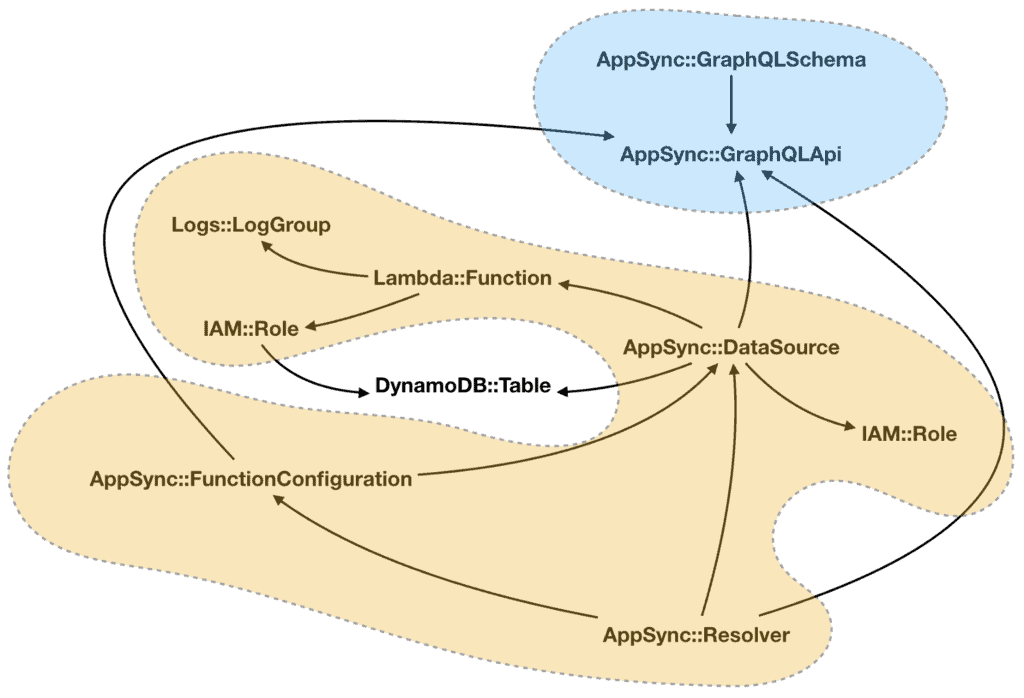
I can pack these mutually-independent groups into nested stacks. Since they don’t reference resources in another group, there’s no chance for circular references.
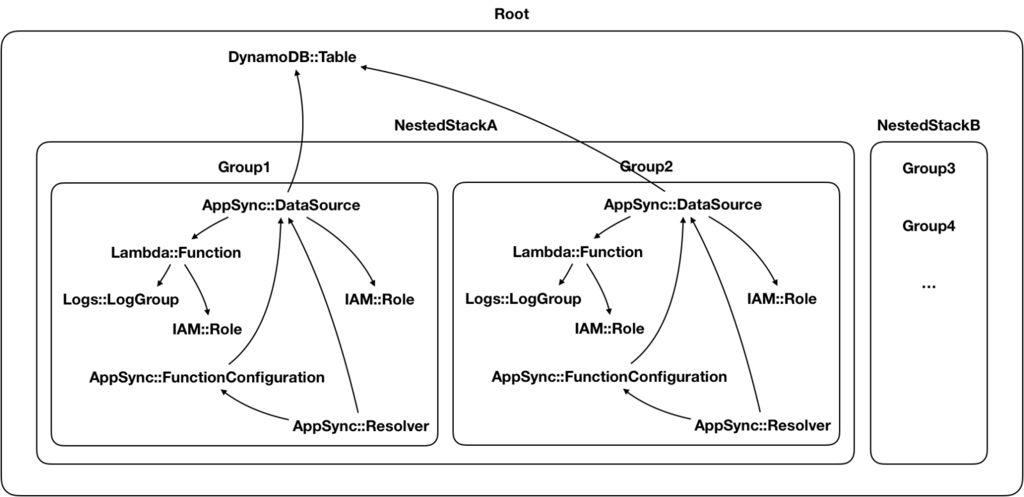
With this strategy, I am now able to split the resources into many more nested stacks. Compared to my earlier attempts, this approach is also very scalable. If need be, I can add as many nested stacks as I want (within reasons).
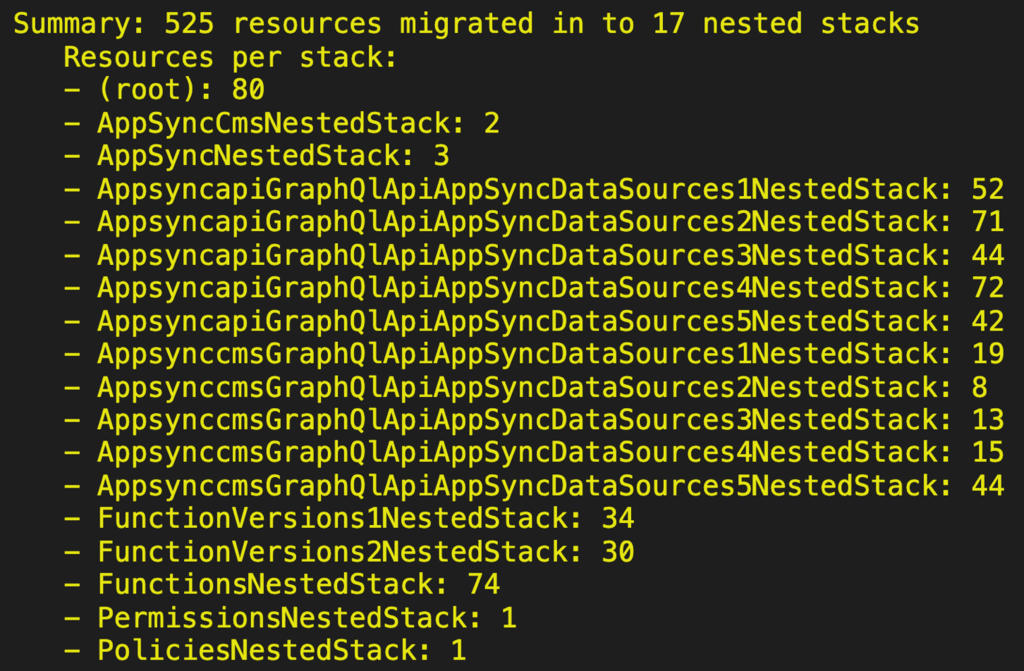
With this change, I was able to add another batch of resolvers to support a new feature.
Other considerations
As you move resources around, there are several things to keep in mind.
No duplicate resource names
For instance, if a Lambda function is moved from one nested stack to another, then the deployment will likely fail because “A function with the same name already exists”. This race condition happens because the function’s new stack is deployed before its old stack is updated. The same problem happens with CloudWatch Log Groups as well as IAM roles.
To work around this problem, I add a random suffix to the names the Serverless framework generates for them.
No duplicate resolvers
Similarly, you will run into trouble if an AppSync resolver is moved from one nested stack to another. Because you can’t have more than one resolver with the same TypeName and FieldName.
Unfortunately, I haven’t found any way to work around this problem without requiring downtime – to delete existing resolvers, then deploy the new nested stacks. Instead, my strategy is to pin the resolvers to the same nested stack by:
- use a fixed number of nested stacks
- hash the logical ID of the data source so they are always deployed to the same nested stack
- when I need to increase the number of nested stacks in the future, hardcode the nested stack for existing data sources
If you can think of a better way to do this, then please let me know!
So that’s it on how I scaled an AppSync project to over 200 resolvers, hope you have found this useful!
Related Posts

Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.