
Yan Cui
I help clients go faster for less using serverless technologies.

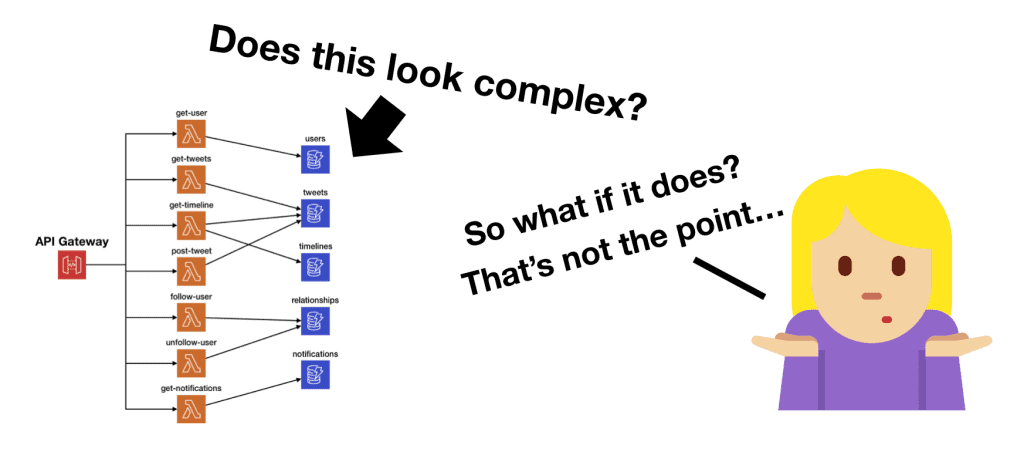
A common complaint I hear about serverless architectures is that they look complicated on architecture diagrams, with many moving parts. But does it mean serverless architectures are more complex compared to their serverful counterparts?
Before I get to that, let’s do a simple exercise.
Serverful architectures
Which of these two serverful applications is more complex?
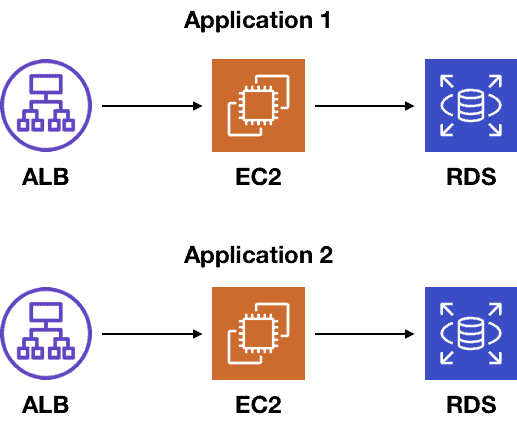
It’s pretty hard to tell, right? Since the architecture diagram alone doesn’t tell the full story, those EC2 icons are great at hiding all the complexities buried in your code.
What if we had a more honest representation of what these two applications actually look like? You know, by not omitting 90% of what is actually going on in them.
We might end up with something like this:
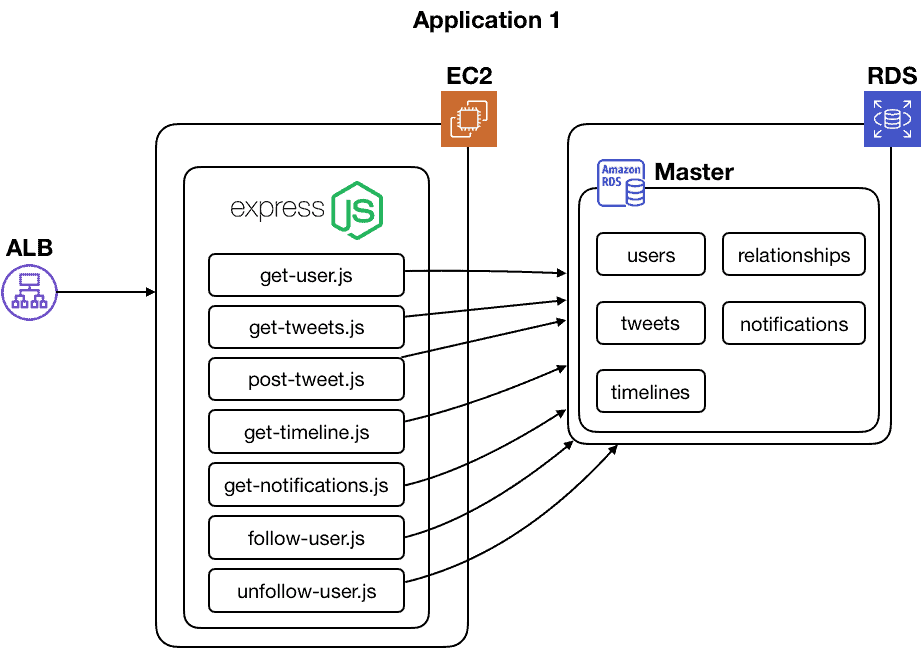
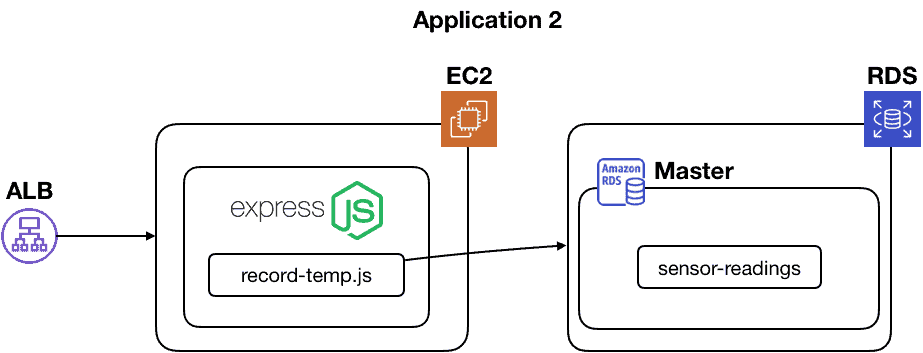
Suddenly, it’s clear to see that Application 1 is far more complex than Application 2. We have gained a better understanding of their true nature.
The architecture diagrams have become more complex, but is that a bad thing in and of itself?
It reveals your application for what it actually is.
Just because you previously omitted those database tables and handler modules doesn’t mean they didn’t exist. It certainly didn’t mean you were immune to all the complexity and headache they would cause you.
Ignorance is not bliss, not when you have to support the application and wake up at 3 AM when the server goes down.
Speaking of servers going down, you don’t just run one server in production. If you follow AWS best practices, you will run your application in at least two availability zones.
You would definitely not have just a single RDS instance. At the minimum, you will have a read-replica if the master goes down.
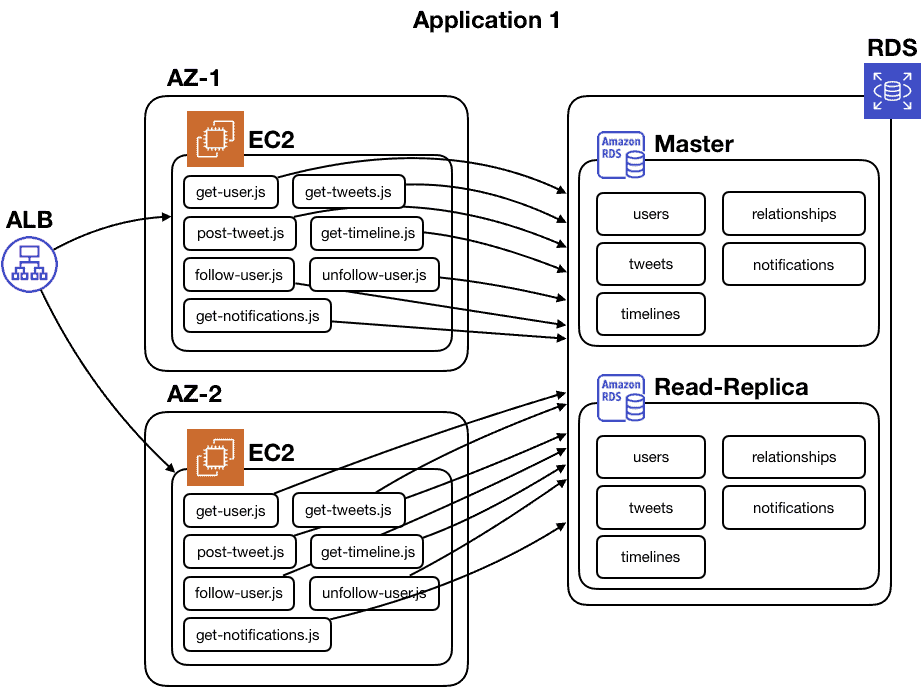
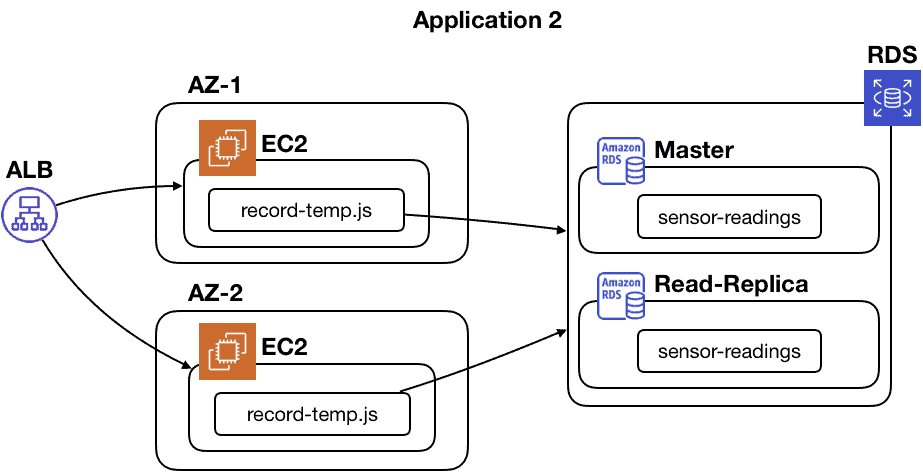
It’s starting to get a bit complicated once you don’t omit important implementation details, right?
Serverless architecture
What would an equivalent serverless application look like?
Well, most likely, you’ll have API Gateway, Lambda and DynamoDB. Of course, you can still use RDS with Lambda, but honestly, if DynamoDB is sufficient for your data access patterns, then you should use DynamoDB instead. It’s just far easier to work with – no infrastructure to manage, and you get consistent and fast performance at any scale.
Our two applications might look something like this in a serverless implementation.
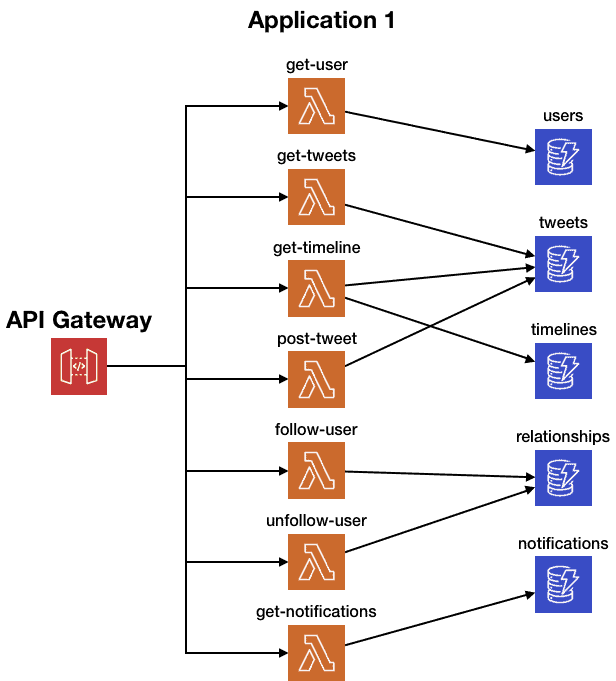

Wait, where are those multi-AZ boxes?
API Gateway, Lambda and DynamoDB all give you multi-AZ out-of-the-box, so it’s no longer your responsibility.
And what about all the other complexities that are not captured by an architecture diagram but have to be tackled nonetheless? You know, things like collection logs and metrics, patching the OS with security updates, configuring auto-scaling groups, working out how many reserved instances you should buy?
Not to mention all the complexities that are in your CI/CD pipeline – how you package and deploy your code, how to do blue-green deployment to avoid deployment downtime, and so on.
Just because they aren’t captured in architecture diagrams doesn’t mean they don’t exist. In fact, I have been building applications on AWS for 15 years and I easily spent 80% of my working hours dealing with infrastructure-related tasks before serverless.
For serverless applications, these infrastructure concerns are either provided by the platform or they have been drastically simplified. For example, to package and deploy my application with the Serverless framework, all I need is one command:
sls deploy
That’s it.
Lambda performs the traditional blue-green deployment out-of-the-box, automatically redirecting incoming requests to new workers running my new code. Once the old workers finish processing the already inflight requests, they are deprecated.
When traffic spikes, Lambda auto-scales the number of workers running my code. I don’t have to pay for those extra resources when no one’s using my application. As mentioned before, Lambda also deploys my code to three availability zones by default.
And I don’t have to worry about a whole class of security vulnerabilities and attack vectors around the OS and EC2 instance!
The infrastructure running my code is managed and secured by AWS. No one can just log on to the server running my code and snoop around. The OS is constantly updated and patched with the latest security patches.
When Meltdown and Spectre were publicly disclosed, I spent a week patching all the docker images and AMIs at my previous company. All the while, our Lambda functions were patched on day 1, and we didn’t have to lift a finger.
Wile more granular architectural components, I can also apply better security practices and limit the permissions of each function to just what it needs. In the event of a breach and an attacker is able to get into your AWS environment through your code (maybe through a compromised dependency, or a successful code injection attack), this limits the amount damages the attacker can cause.
Conclusion
Ask yourself what’s more important – having a simple-looking diagram of your application or actually having a simpler application.
A serverless application might look more complex on paper than its serverful counterpart.
But only one of these diagrams is a true representation of what you are running. Only one of these diagrams will give you a nasty surprise when you dare to open the box and see what’s inside.
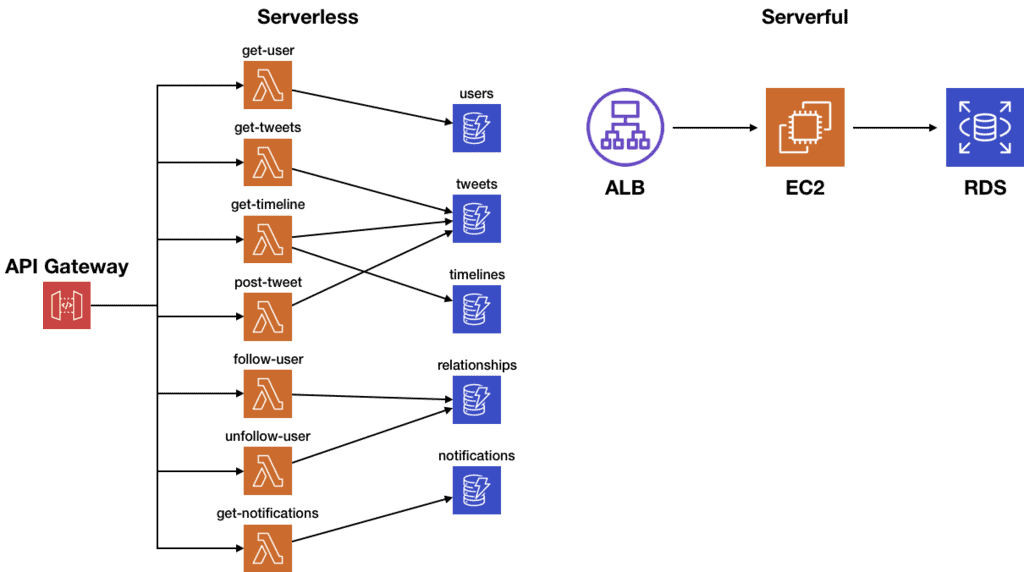
Serverless applications don’t have more complex architecture diagrams. They have more honest architecture diagrams of what your application actually is. And once you factor in the built-in scalability, resilience and security you get, serverless applications are far simpler than an equivalent serverful application that ticks all the same boxes.
The argument that “even simple serverless applications have complex architecture diagrams” simply reflect the fact that a lot of the hidden complexities in your application are revealed and surfaced to the top.
This is a good thing.
Because now, you can actually see the true complexity of your application, gain a better understanding of it, and make better architectural decisions because you’re armed with deeper and more accurate information about what your application is.
So what if the architecture diagram looks more complex, the application itself is simpler to build and maintain since you don’t have to worry about the underlying infrastructure that runs your code, and not to mention the deployment and operational models are simpler and far less demanding of your developers. All and all, serverless is a massive net win.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.