

Yan Cui
I help clients go faster for less using serverless technologies.

An interesting question came up on the AppSync Masterclass forum, and it highlights a common way you can get into CloudFormation circular dependencies.
In the CloudFormation stack, there is an AppSync API, which uses a Cognito User Pool for authentication and authorization. When a user signs up, the app should fire an update on a subscription. To do this, the intuitive solution would be to use Cognito User Pool’s PostConfirmation hook to trigger a Lambda function to make a mutation operation against the AppSync API.
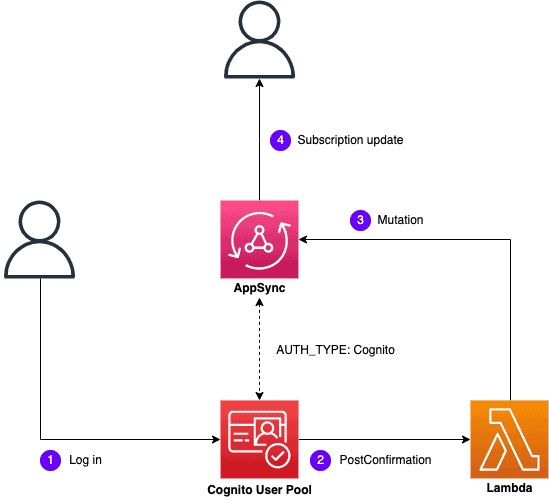
On paper, this solution should work if you can get CloudFormation to deploy it!
The problem is that, for this Lambda function to work, it needs to know:
- the URL of the AppSync API
- the ARN of the AppSync API so it can construct the ARN for the mutation operation it needs to perform
onUserSignUp:
handler: functions/onUserSignUp.handler
environment:
GRAPHQL_API_URL: !GetAtt GraphQLApi.GraphQLUrl
iamRoleStatements:
- Effect: Allow
Action: appsync:GraphQL
Resource: !Sub ${GraphQLApi.Arn}/types/Mutation/onUserSignUp
In doing so, it introduced a circular dependency between the AppSync API, the Cognito User Pool, the Lambda function and its IAM role. In fact, as you can see from the below, there are two circular dependencies here.
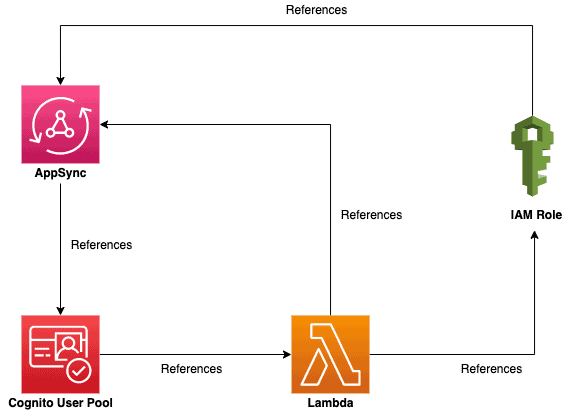
Let’s use this problem to illustrate three approaches that I use to break circular dependencies in CloudFormation, in order of preference.
Approach 1: replace CloudFormation pseudo-functions with handcrafted strings
CloudFormation builds a resource graph based on how resources reference each other using pseudo-functions such as !Ref, !GetAtt or !Sub. This dependency graph tells CloudFormation the order to create the resources.
However, a circular dependency puts CloudFormation in a pickle because there’s no way to determine which resource to create first.
The simplest way to break this circular dependency in the eyes of CloudFormation is to replace pseudo-functions with handcrafted strings.
In this example, we can break both circular dependencies by replacing one of these two resources:
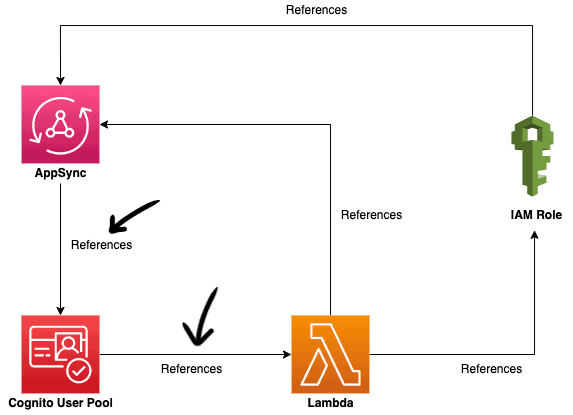
If you decide to go with the Cognito User Pool’s reference to the Lambda function, then we need to replace this:
CognitoUserPool:
Type: AWS::Cognito::UserPool
Properties:
...
LambdaConfig:
PostConfirmation: !GetAtt OnUserSignUpLambdaFunction.Arn
with this:
CognitoUserPool:
Type: AWS::Cognito::UserPool
Properties:
...
LambdaConfig:
PostConfirmation: arn:aws:lambda:xxx:xxx:function:<function name>
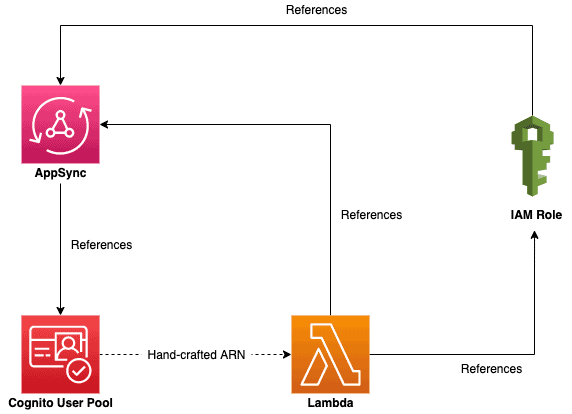
Where this approach doesn’t work
If the string produced by the CloudFormation pseudo-function is not deterministic then this approach won’t work.
For example:
- If you don’t explicitly name the resource and let CloudFormation name the resources for you. The resource’s name and ARN would have trailing random strings. This is the case with Lambda functions, DynamoDB tables and many other types of resources.
- If the pseudo-function returns a non-ARN string, such as an AppSync API’s URL. In our example above, the
onUserSignUpfunction needs the AppSync API’s URL, which looks like this:https://xjjykitgtfisdgrwgegwizrwdu.appsync-api.eu-west-1.amazonaws.com/graphql. In cases like this, you can work around the limitation using custom domain names.
onUserSignUp:
handler: functions/onUserSignUp.handler
environment:
GRAPHQL_API_URL: !GetAtt GraphQLApi.GraphQLUrl
iamRoleStatements:
- Effect: Allow
Action: appsync:GraphQL
Resource: !Sub ${GraphQLApi.Arn}/types/Mutation/onUserSignUp
Approach 2: introduce a layer of indirection
Another approach would be to rearchitect the system to introduce a layer of indirection to separate:
- the capturing of the user signup event, and
- the action of making a mutation request to the AppSync API
This could be using events with EventBridge or leveraging DynamoDB streams. My preference is to use EventBridge in these situations, but I previously wrote about when to use DynamoDB streams, have a read here.
In this case, the PostConfirmation function would publish a UserSignedUp event to an EventBridge bus. This triggers a downstream Lambda function that makes the GraphQL mutation request to the AppSync API.
The revised architect would look like this:
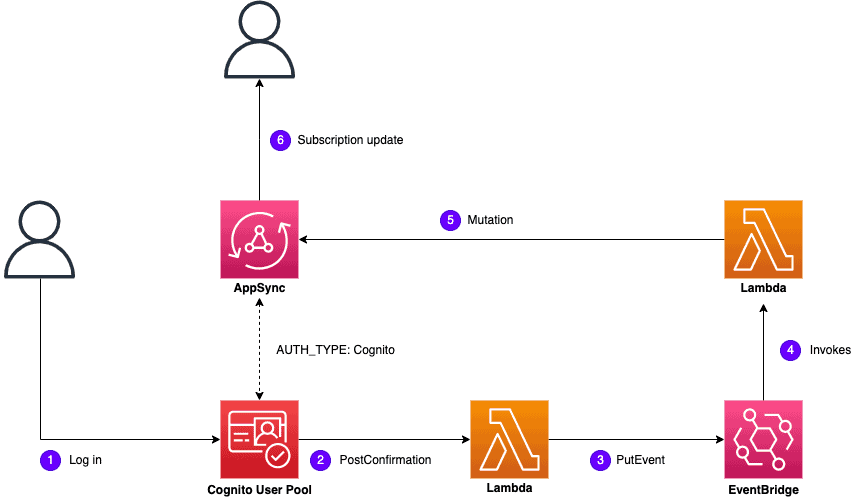
The CloudFormation resource graph would look like this:
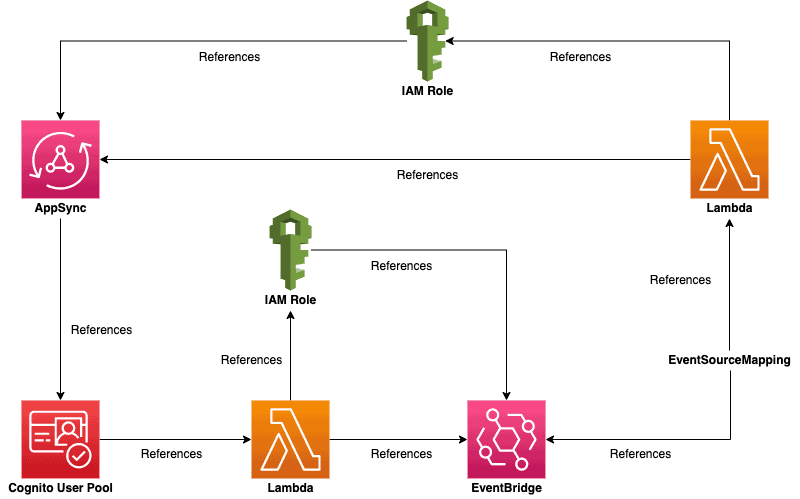
As you can see, there are no more circular dependencies.
Pros of this approach
Although I had framed this approach in the context of resolving a CloudFormation circular dependency, this event-driven approach has its own merits:
- The
UserSignedUpevent is a useful business domain event and should be part of a business’s KPI metrics. These domain events captured by EventBridge can be forwarded to a Firehose Delivery Stream and aggregated, compressed, and delivered to an S3 bucket. You can then analyze them with Athena and/or visualize them in QuickSight. - You can build new business capabilities incrementally using these events. For example, to issue a first-time user coupon as part of a new “promotion” microservice. This event-driven approach allows you to build these microservices in a loosely-coupled way and allow them to scale and fail independently.
- EventBridge provides built-in archiving and replay capabilities.
This approach works best as part of an overarching architectural approach to use events as the driving force of your architecture. When employed as an isolated use case to solve a CloudFormation circular dependency issue, it’s akin to taking a hammer to crack an egg given the following drawbacks.
Cons of this approach
- The biggest drawback is the additional complexity:
- there are more moving parts in the architecture;
- observability becomes more challenging, although tools like Lumigo can greatly mitigate this challenge;
- There is extra end-to-end latency. Instead of a single mutation request to AppSync, we now have:
- A PutEvents request to EventBridge;
- The time it takes EventBridge to the event (typically within a few seconds);
- The invocation time (including any cold start time where relevant) of the 2nd Lambda function;
- The latency of the GraphQL mutation request.
Approach 3: make the dependency a parameter that can be loaded at runtime
You can also capture the desired value as an SSM parameter and have the Lambda function load it at runtime.
Using the above example, we can capture the GraphQL URL as an SSM parameter:
GraphQLUrlParameter:
Type: AWS::SSM::Parameter
Properties:
Name: /${sls:stage}/graphql-url
Type: String
Value: !GetAtt GraphQLApi.GraphQLUrl
But you will still end up with a circular reference because the Lambda function would need permissions to access the parameters at runtime.

The difference now is that you have named the SSM parameter and therefore its ARN is predictable. So the IAM policy’s reference to the parameter can be replaced with a handcrafted ARN string:
arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:parameter/${sls:stage}/graphql-urlHence breaking the circular dependency.
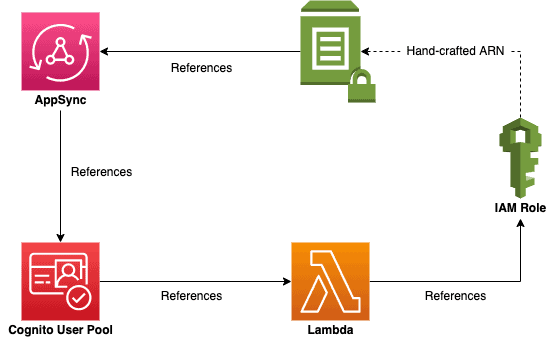
Unlike approach 2, there are no architectural benefits that we can derive from this approach.
And since there are additional runtime dependencies on SSM parameters, it would also introduce extra latency to the Lambda function. You can mitigate this latency overhead somewhat by caching the retrieved values during cold start (for example, by using middy’s SSM middleware).
Another problem with this approach is that it doesn’t work for a lot of situations. For example, if the circular reference is introduced by an IAM policy:
onUserSignUp:
handler: functions/onUserSignUp.handler
environment:
GRAPHQL_API_URL: !GetAtt GraphQLApi.GraphQLUrl
iamRoleStatements:
- Effect: Allow
Action: appsync:GraphQL
Resource: !Sub ${GraphQLApi.Arn}/types/Mutation/onUserSignUp
In these cases, it’s not possible to simply move the AppSync API’s ARN to an SSM parameter. And unfortunately for us, the ARN of an AppSync API contains the API ID, which is generally generated. In case you’re wondering, they look like this: arn:aws:appsync:<region>:<account-id>:apis/er4emjzpqfhkbfithluoormr64.
Wrap up
In this post, we discussed the problem of circular dependencies in a CloudFormation stack and highlighted a common way of getting yourself into such situations. I outlined three different approaches that I use to resolve this problem:
- replace one of the CloudFormation pseudo-functions in the circular dependency with a handcrafted string;
- rearchitect your solution and introduce a layer of indirection, such as an EventBridge bus or a DynamoDB Stream;
- capture the desired value as an SSM parameter and load it at runtime instead.
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications then check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.