

Yan Cui
I help clients go faster for less using serverless technologies.

As a consultant, I have helped many clients with their architecture [1] and built several serverless applications for clients from scratch. And the no. 1 question I get about serverless is around testing.
“How should I test these cloud-hosted functions?”
“Should I use local simulators?”
“How do I run these in my CI/CD pipeline?”
In this post, let me share my approach to testing serverless applications and how I achieve a fast feedback loop.
LocalStack
There is a lot of value in testing your code locally. You can catch problems without waiting for a full deployment cycle and get that all-important fast feedback loop.
One option is to simulate AWS services locally with LocalStack [2]. I had been sceptical of them in the past because they used to take a lot of effort to set up, and the local environment tends to be very brittle and hard to maintain. The LocalStack team has improved greatly on these in the last two years, and LocalStack v3 is looking very impressive [3].
However, you must still deploy your changes to the local simulated environment. This doesn’t take as long as deploying to the real AWS account, but it’s a delay nonetheless.
Also, LocalStack is not a perfect simulation. No local simulation will be a perfect replica of the real AWS environment. The simulator will always have missing APIs, behaviour differences, or bugs. You will experience some false negatives – somethings don’t work against LocalStack but work just fine in the real AWS environment.
These false negatives can be difficult to track down, and you can easily lose hours or days of development time when they occur.
Besides, you still need to write automated tests. The local simulator will not execute all your application paths for you. So the question remains – how can I achieve a fast dev & test loop as I iterate on my code changes?
Remocal Testing
For Lambda functions, I prefer to use remocal testing while leveraging ephemeral environments. Read this post [4] to see why you should use ephemeral environments for your workflow.
A remocal test is when you execute your code locally against remote resources. It combines the best of local testing with remote testing (aka testing in the cloud). It provides a fast feedback loop while ensuring high confidence in the tests.
My workflow
When starting a new feature, I will create an ephemeral environment by running the command sls deploy -s my-feature using the Serverless Framework. This provisions a temporary environment in AWS, in a dev account I share with other developers in the team.
The new environment is represented by a CloudFormation stack, encapsulating everything necessary to run the service that I’m working on. This environment is dedicated to the feature I’m working on and is short-lived.
I then write tests that execute my function code locally against real AWS services such as DynamoDB tables. As I make changes to my code, I can execute the tests to make sure my code is working before I deploy the changes to the AWS account. If you’re using jest and VS Code as your IDE, you can even install the jest runner plugin for VS Code so the relevant tests are executed every time you make a change.
This gives me a fast feedback loop and the option to step through the code line-by-line with a debugger, which makes debugging failing tests much easier.
You only need to redeploy the CloudFormation stack when you make certain infrastructure changes, such as adding new DynamoDB tables or a new index to an existing DynamoDB table. This is because your code depends on these AWS resources existing in your AWS account to work. These deployments also help verify that your infrastructure code works correctly.
You can also test your code against LocalStack instead of the real AWS services. The same principle applies.
These “integration tests” (or “sociable tests” as Martin Fowler calls them [5]) test your code against real AWS services and catch integration problems as well as business logic errors quickly and give you fast feedback for code changes. But what about unit tests that use mocks and stubs?
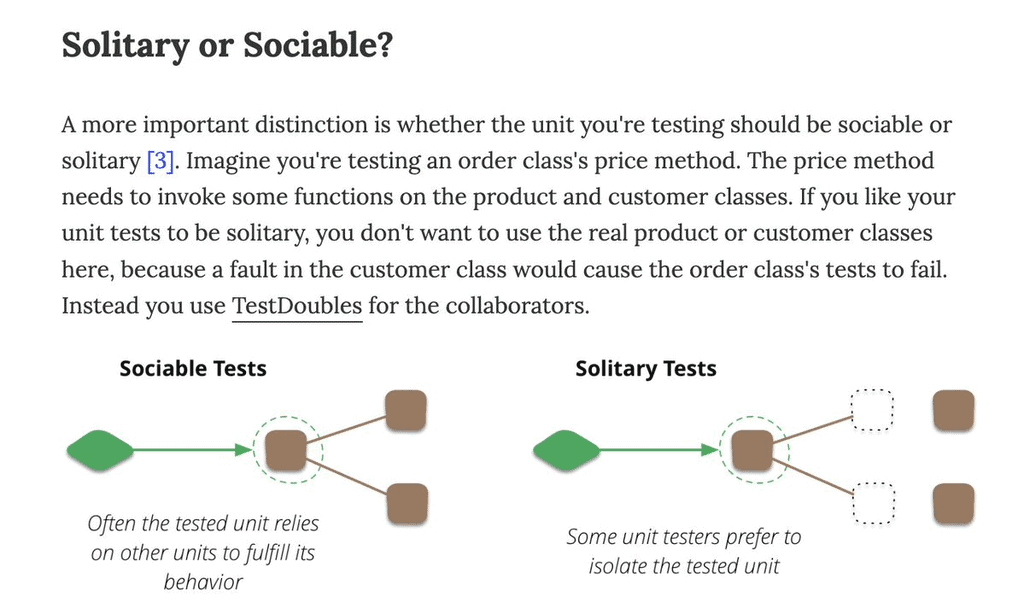
Unit Tests, or not
I generally think “unit tests” (what Martin Fowler calls “solitary tests”) don’t have a great return on investment, and I only write these if I have genuinely complex business logic. Most of my Lambda functions are IO-heavy and perform simple data transformations. They can be sufficiently tested by my remocal tests.
However, when dealing with complex business logic, I encapsulate them into modules, write unit tests for them, and ensure these tests don’t deal with any external dependencies. They work exclusively with domain objects. And yes, I use mocks and stubs in these tests to exercise the desired code paths.
End-to-End Tests
Once I am confident that my code works, I will write end-to-end tests to check that the whole system works (without the front end) by testing it from its external-facing interface, which can be a REST API, an EventBridge bus, or whatever.
These end-to-end tests will catch problems outside my code – configurations, IAM permissions, etc.
Often, I write tests in such a way that I can reuse the same test case as both integration and end-to-end tests. This is so that they’re not as labour-intensive to produce and maintain. If you’re following a contract-first approach and designing your APIs with their consumers (e.g., the web and mobile teams), you should also write these end-to-end tests first and use them to check the design of your APIs.
For HTTP APIs, these end-to-end tests will call the deployed API and check the responses. For data pipelines, they will publish events into an event bus and wait for the expected side effect to occur (e.g., data written to a DynamoDB table).
Again, using temporary environments really helps here. You don’t have to worry about pushing events to a shared event bus and unintentionally triggering other subscribers.
If the side effect you’re looking for is “an event is published to Kinesis/EventBridge/SNS,” it can be tricky to detect them. Read this post [6] for a few ways to capture the published events and feed them back to your tests.
Once all my end-to-end tests also pass, I’m confident everything is working. Now, I’m ready to commit code and create a PR. I will destroy the ephemeral environment by running the sls remove -s my-feature command. This removes all the resources I had created earlier and wipes any test data I generated along the way.
CI/CD pipeline
As part of the CI/CD pipeline, I will create another ephemeral environment and run the remocal and end-to-end tests against it. This way, we avoid polluting the shared environments (e.g. dev) with test data. The CI/CD pipeline will create the ephemeral environment at the start and destroy it at the end.
If all the tests are passed, I can proceed to deploy the application to the shared environments such as dev, staging and production.
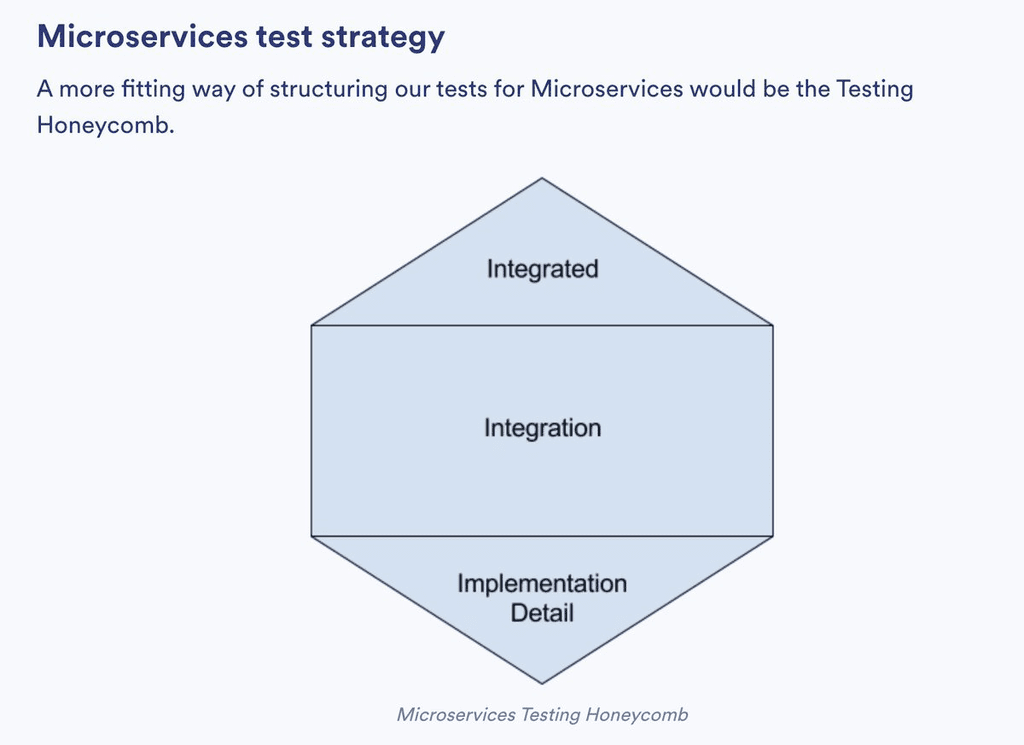
Testing honeycomb
This approach to testing serverless applications is broadly in line with and inspired by the testing honeycomb [7].
It gives me a fast feedback loop for small code changes and the confidence I need to operate complex applications with many moving parts.
As the honeycomb shape suggests, most of my tests are integration tests (written as remocal tests) for my Lambda functions. These tests exercise my code’s integration with other AWS services.
Testing in production
Of course, testing doesn’t stop there!
There is a whole school of thought around testing in production [8]. It includes observability, canary testing, smoke testing, load testing, chaos experiments, and more. You don’t need to do all of them, but good observability in your application is a must.
My go-to solution is Lumigo [9], which I use in all of my projects. It takes only a few minutes to set up, there’s no need for manual instrumentation, and it gives me everything I need to troubleshoot issues that I haven’t seen before.
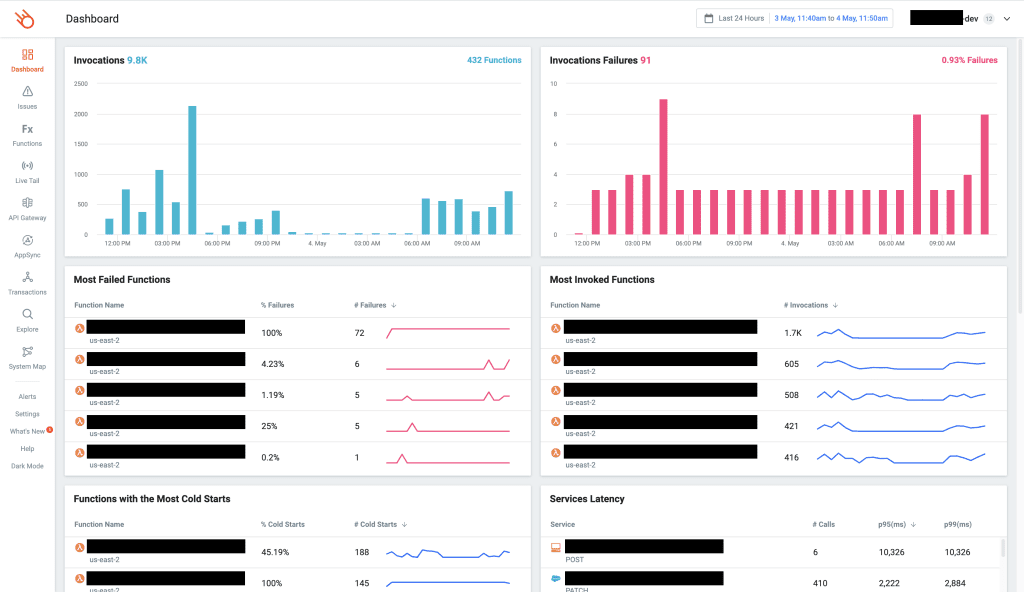
And I love the built-in dashboard, designed by serverless users for serverless users. I can see at a glance all the important information about my application and quickly identify functions that require further inspection, e.g.
- Lambda functions with a high error rate.
- Lambda functions with a high percentage of cold starts.
- Dependencies (services that I call from my Lambda function) with a high tail latency would, therefore, affect my application’s performance.
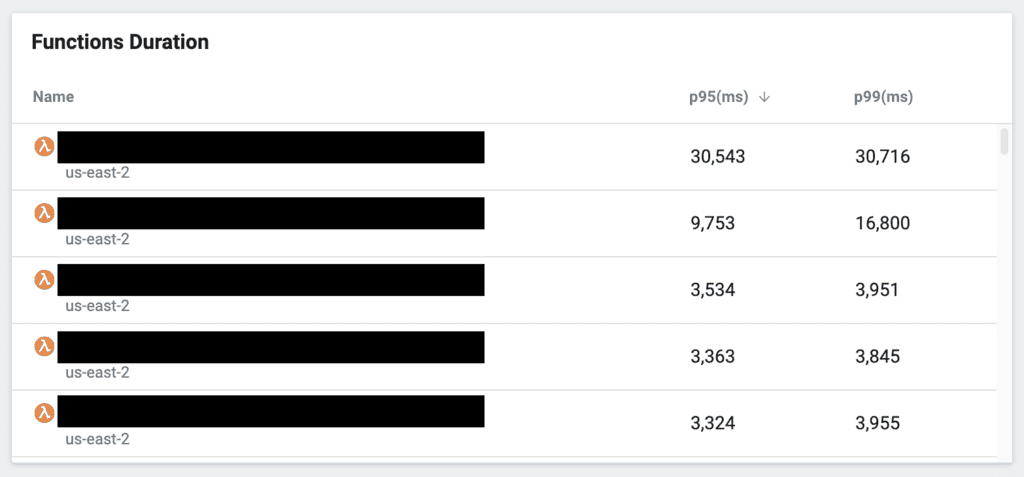
I can also identify functions with a high tail latency (likely affected by poor-performing dependencies above), drill into individual invocations, and determine the root cause.
It’s been an invaluable tool for me, and it’s a big part of how I stay productive and resolve client issues quickly. If you’re working with Lambda, you owe it to yourself and your team to check it out. I promise you, it will be a game-changer.
Wrap up
I hope that this post was useful to you. If you haven’t experimented with remocal testing using ephemeral environments yet, make that the first thing you do. They are a big part of my general strategy towards testing serverless applications and have transformed my workflow.
If you want to learn more about testing serverless applications, check out my latest course, Testing Serverless Architectures [10]. I’m able to go into much more detail with how I write tests and apply this strategy to different types of serverless architectures:
- API Gateway
- AppSync
- Event-Driven Architectures with EventBridge
- Step Functions
Hope to see you in the course :-)
Links
[2] LocalStack
[3] LocalStack v3 is here and it’s kinda amazing!
[4] Why you should use ephemeral environments when you do serverless
[5] On the Diverse And Fantastical Shapes of Testing by Martin Fowler
[6] How to include SNS and Kinesis in your e2e tests
[7] What is the test honeycomb, and why you should care
[8] What do we mean by “Testing in Production”?
[9] Lumigo, the best observability platform for serverless applications
[10] Testing Serverless Architectures, your guide to master serverless testing
Related Posts



Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.