
Yan Cui
I help clients go faster for less using serverless technologies.

One of the benefits of serverless is the pay-per-use pricing model you get from the platform. That is, if your code doesn’t run, you don’t pay for them! Combined with the simplified deployment flow (compared with applications running in containers or VMs) it has enabled many teams to use ephemeral environments to simplify their workflow and go faster.
In this post, we will discuss two ways you can use ephemeral environments when working with serverless technologies. Disclaimer: This shouldn’t be taken as a prescription. It’s a general approach with pros and cons, which we will discuss below.
What is an “environment”?
An environment consists of everything your application needs to operate. It’s a complete copy of your application, encompassing any API Gateway, Lambda functions, DynamoDB tables, EventBridge buses, etc., that your application needs.
You can have multiple environments (i.e. multiple copies of your application) running in the same AWS account. As long as the resource names don’t clash, they don’t interfere with each other.
You should prefer monolithic deployments. All the related changes for a feature should be deployed together so the deployment is as close to an atomic action as possible. This means you should keep stateful resources (e.g. DynamoDB tables) and stateless resources (e.g. Lambda functions) together where possible (see this post [1] for more details). This is not always possible.
When working with serverful resources (i.e. those that charge by up-time, such as RDS databases), you should avoid creating many copies of them to avoid paying up-time multiple times. This requires special handling when using ephemeral environments. See this post [2] for more details.
With Infrastructure-as-Code tools such as AWS SAM or the Serverless Framework, your project is compiled into a CloudFormation template and deployed with CloudFormation. And if you keep both stateful and stateless resources in the same stack then a CloudFormation stack is an approximation to an environment.
With AWS CDK, the picture looks a little different. You can still achieve monolithic deployments while making use of multiple CloudFormation stacks in the same CDK application. So an environment is synonymous with a CDK application instead.
Ephemeral environments for feature branches
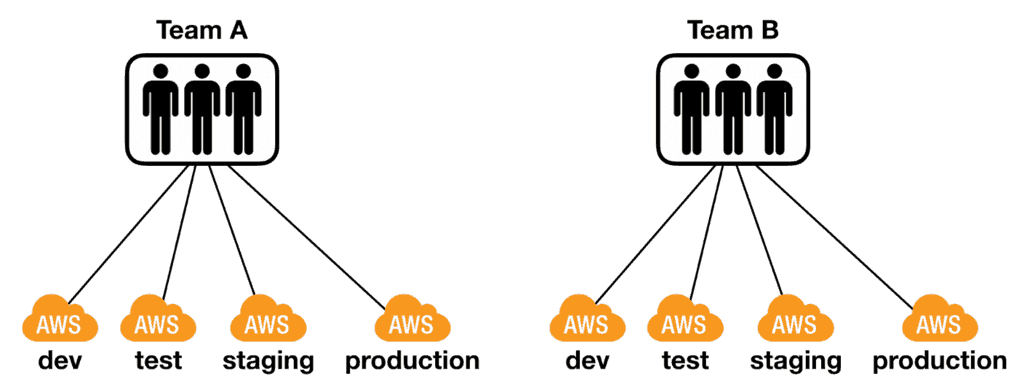
It’s common for teams to have multiple AWS accounts, one for each environment. While there doesn’t seem to be a consensus on how to use these environments, I tend to follow these conventions:
devis shared by the team. This is where the latest development changes are deployed and tested end-to-end. This environment is unstable by nature and shouldn’t be used by other teams.testis where other teams can integrate with your team’s work. This environment should be fairly stable to avoid slowing down other teams.stagingshould closely resemble production and would often contain a dump of production data. This is where you can stress test your release candidate in a production-like environment.- and then there’s
production
Having one account per environment is considered best practice. Some of my AWS friends would go even further and have one AWS account per developer.
I have never felt the need to have one account per developer. After all, there is some overhead associated with having an AWS account. Instead, I usually settle for one AWS account per team per environment.
I would have a separate deployment CloudFormation stack per developer (but in the same dev account). This is especially useful when I’m working on feature branches.
When I start work on a new feature, I’m still feeling my way towards the best solution for the problem. The codebase is still unstable and many bugs haven’t been ironed out yet. Deploying my half-baked changes to the dev environment can be quite disruptive:
- it risks destabilising the team’s shared environment
- it’d overwrite other features the team is working on
- team members would be fighting over (not literally!) who gets to deploy their feature branch to the shared environment
Some of these challenges can be mitigated with feature toggles. Different feature branches can be live simultaneously and only enabled for the developers working on them. Services like LaunchDarkly [3] are great for this.
But what do you do when you need to deploy and test some unfinished changes? That is, the change is not complete and not yet ready to be reviewed and merged back into master. Feature toggles won’t help you in this case.
Instead, I can deploy the feature branch to a dedicated environment, e.g. dev-my-feature. Using the Serverless framework [4], it is as easy as running the command sls deploy -s dev-my-feature. This would deploy all the Lambda functions, API Gateway and other related resources (DynamoDB, etc.) in its own CloudFormation stack. I could test my work-in-progress feature in a live AWS environment.
Having these temporary CloudFormation stacks for each feature branch has negligible cost overhead. The dev account has no traffic because it’s only used by the team. When the developer is done with the feature, the temporary stack can be easily removed by running sls remove -s dev-my-feature.
However, long-lived environments exhibit the same problems as long-lived feature branches. Namely, they get out-of-synch with other systems they need to integrate with. Both in terms of the events coming into your function, such as the payloads from SQS/SNS/Kinesis, etc. As well as data your function depends on, such as those that reside in DynamoDB.
Teams that use serverless tend to move faster, so the problems with long-lived feature branches become more prominent and noticeable as well.
Don’t leave feature branches hanging around for more than a few days. If the work is large and takes longer to implement, then break it up into smaller features. When you’re working on a feature branch, integrate from the master regularly (no less than once per day).
LocalStack vs talking to AWS
Instead of spending lots of time to get tools such as LocalStack [5] working, I find it much more productive to deploy a temporary CloudFormation stack in AWS and run against the real thing.
The main downsides are:
- you need an internet connection
- deploying to AWS is slower than running code locally, which slows down the feedback loop
The internet access argument is only relevant for a handful of people who spend most of their time on the road. I travel more than most and do a lot of work while I’m at airports, and internet access is rarely a problem for me.
As for the slower feedback loop, it probably feels worse than it is. To maintain a fast feedback loop, I also use remocal testing [6] extensively so I can test code changes without having to deploy my code repeatedly. Furthermore, I can use the sls invoke local command to invoke my functions locally and attach a debugger to step through the code line-by-line.

Temporary stacks for end-to-end tests
Speaking of testing, another common use of temporary CloudFormation stacks is for running end-to-end tests.
One of the common problems with these tests is that you need to insert test data into a live, shared AWS environment. As a rule of thumb I always:
- insert the data a test case needs before the test
- delete the data after the test finishes
These help keep my tests robust and self-contained as they don’t implicitly rely on outside data. They also help reduce the amount of junk that is floating around in the shared environments as well.
However, despite our best intentions, mistakes happen and sometimes we deliberately cut corners to gain agility in the short term. Over time, our shared environments are filled with test data, which can interfere with normal operations.
As a countermeasure, many teams would use cron jobs to wipe these environments from time to time.
An emerging practice to combat these challenges is to create an ephemeral environment during the CI/CD pipeline instead. This temporary environment is used to execute the end-to-end tests and destroyed afterwards.
This way, there is no need to clean up test data, either as part of your test fixture or with cron jobs.
The drawbacks are:
- the CI/CD pipeline takes longer to run
- you still leave test data in external systems, so it’s not a complete solution
You should weigh the benefits of this approach against the delay it adds to your CI/CD pipeline and decide if it’s right for a project. I think it’s a great approach and I’d encourage more teams to adopt it. However, the more data you have to clean up in external systems (that is, systems that are not part of the ephemeral environment) the less useful it becomes.
Summary
In summary, here are two ways you can use ephemeral environments to improve your development flow for serverless applications:
- Use ephemeral environments for feature branches to avoid destabilising shared environments.
- Use ephemeral environments during CI/CD pipeline to run end-to-end tests to remove the overhead of cleaning up test data.
These approaches should not be considered as a prescription. You need to consider their pros and cons and see if they fit with your constraints and how your teams work.
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications, check out my upcoming workshop, Production-Ready Serverless [7]!
In the workshop, I will give you complete, end-to-end training for building serverless architectures in the real world. Along the way, I will take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Links
[1] This is why you should keep stateful and stateless resources together
[2] How to handle serverful resources when using ephemeral environments
[3] LaunchDarkly – a really good service for feature toggling.
[4] Serverless framework – still the most popular deployment framework for serverless projects.
[5] LocalStack – a tool for simulating AWS locally.
[6] My strategy for testing serverless applications
[7] Production-Ready Serverless – your one-stop shop to master serverless development for the real world
Related Posts

Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.