
Yan Cui
I help clients go faster for less using serverless technologies.

I’m a big fan of using ephemeral (or temporary) environments when I’m building serverless architectures. I have written about this practice before and I believe it’s one of the most important practices that have co-evolved with the rise of serverless technologies.
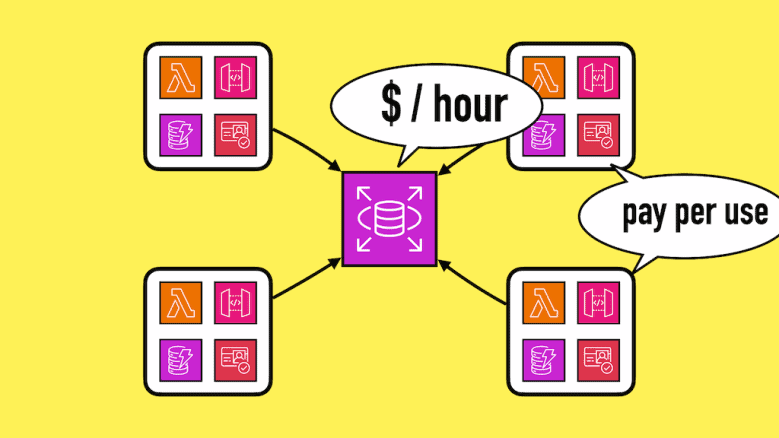
It takes advantage of the pay-per-use pricing model offered by many serverless technologies such as Lambda and DynamoDB. You can create as many ephemeral environments as you need (resource limits permitting, of course). There are no extra charges for having these environments.
You can create an ephemeral environment when you start working on a feature and delete it when you’re done. You can even create a fresh environment for every CI/CD run so you can test your code without worrying about polluting your dev/test environments with dummy test data.
To make it easy to create ephemeral environments for your services, I also prefer to keep stateful (e.g. databases) and stateless resources together. I wrote about this recently and addressed the most common counterarguments.
Using these two practices together has supercharged my development flow and I have seen these practices in organizations of all sizes.
However.
What about serverful resources?
Few things in life are black and white, and few practices are universally “best” for everyone.
When your serverless architecture relies on serverful resources such as RDS or OpenSearch, it can be a challenge to use ephemeral environments.
You wouldn’t want to have lots of RDS instances sitting around and paying for uptime for all of them.
These serverful resources also take longer to spin up, which also doesn’t play well with using ephemeral environments.
As such, I don’t include these serverful resources as part of the ephemeral environments and would share them instead.
For example, I would have one RDS cluster in the dev account. All ephemeral environments in the dev account would use the same cluster but have their own tables/databases. This lets me keep the ephemeral environments self-contained without multiplying my RDS cost.
Furthermore, serverful resources also affect another of my favourite practices — keeping stateful and stateless resources together.
Serverful resources such as RDS is also an exception to my preference here.
The RDS cluster would be in a separate stack and have its own deployment and update cycle. As part of this stack, I will create SSM parameters with the ARN, connection string, etc. of the RDS cluster. The service stack would be able to reference them with these SSM parameters.
For example, I would create these SSM parameters:
/my-service/dev/rds-arn
/my-service/dev/rds-connection-string
/my-service/dev/rds...
But you might be wondering “Do I need to duplicate these SSM parameters every time I create an ephemeral environment?”
Luckily, you don’t have to!
Sharing SSM parameters
In situations where your ephemeral environments have to share resources such as RDS instances, it’s common to use shared SSM parameters.
With the Serverless framework, you can refer to the stage name (or environment name) with the ${sls:stage} variable. So if you were to create an ephemeral environment called dev-yan then ${sls:stage} would resolve to dev-yan.
So, to tell the deployment to use SSM parameters from another environment, we can introduce a custom variable. Let’s call this ssmStage.
custom:
ssmStage: ${param:ssmStage, sls:stage}
This would use an ssmStage parameter that can be passed in through the CLI commands, e.g. npx sls deploy --param="ssmStage=dev". If the parameter is not set, then it will fallback to the ${sls:stage} variable.
Once this is defined, I can use ${self:custom.ssmStage} any time I need to refer to the shared SSM parameter.
For example, to reference an ARN in the IAM permissions:
provider:
iam:
role:
statements:
- ...
Resource: ${ssm:/${self:service}/${self:custom.ssmStage}/some-arn
You only need to set the ssmStage parameter when you’re working with an ephemeral environment. When working with any of the main environments (such as dev, test or staging) you can omit it and rely on the fallback.
What about shard infra like VPCs?
I consider things like VPCs, subnets, etc. as part of the “platform”, not the service. These are often managed centrally (e.g. by a platform team) and deployed as part of the landing zone for an account/region.
Of course, they should have their own stack and repo and pipeline.
It’s an important nuance to consider when applying best practices in a mixed environment with both serverless and serverful components.
Shout out to Chris Townsend for bringing this up during my most recent workshop!
If you want to level up your serverless skills and learn best practices for building serverless architectures, then check out the dates for my upcoming workshops.
Related Posts

Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.