

Yan Cui
I help clients go faster for less using serverless technologies.

Many software engineering concepts appear in different contexts. Modularity, the single-responsibility principle and separation of concerns are just a few examples that come to mind. They apply equally to how we write code, architect our systems and organize our teams. In this post, let’s discuss three ways we can control the concurrency of a serverless application by taking ideas from coding patterns such as Thread Pool and Fork Join.
Using reserved concurrency
To implement a “thread pool”, you can use reserved concurrency on a Lambda function.
Specifying resource concurrency on a function reserves some of your available regional concurrency units for it. This ensures that the function always has the appropriate amount of concurrency when it needs to scale. Simultaneously, it reduces the total concurrency that other functions in the region can use to scale on demand.
Interestingly, reserved concurrency functions as the maximum concurrency on the Lambda function.
It’s great for controlling the concurrency of Lambda functions that process events from asynchronous sources [1] (e.g., EventBridge, SNS, S3). You can control the concurrency at which events are processed. This is a useful pattern for dealing with downstream systems that are less scalable.
This is the simplest way to manage the concurrency of a serverless application. But it has limitations.
Limitations
Reserved concurrency is useful when using it for a few functions. However, the assigned concurrency units are removed from the regional pool, leaving less concurrency available for all your other functions. When managed poorly, this can lead to API functions being throttled and directly impacting user experience.
Reserved concurrency is, therefore, not something that should be used broadly.
Alternatively, workloads that require frequent use of reserved concurrency should be moved to their own account to isolate them from workloads that require a lot of on-demand concurrencies, such as user-facing APIs.
Using EventSourceMapping
If you need to process events in the order they’re received, you should use Kinesis Data Streams or a combination of SNS FIFO and SQS FIFO.
In both cases, you can control your serverless application’s concurrency with the relevant settings on the EventSourceMapping [2].
With this approach, you don’t need to use Lambda’s reserved concurrency, so you don’t need to manage the concurrency allocation of individual functions manually. This makes it a viable solution that can scale to as many functions as you need.
With Kinesis, ordering is preserved within a partition key. For example, if you need to ensure events related to an order are processed in sequence, then you would use the order ID as the partition key.
You can control the concurrency using several settings:
- Batch Size: How many messages do you process with each invocation?
- Batch window: How long should the Lambda service wait to gather records before invoking your function?
- Concurrent batches per shard (max 10): The max number of Lambda invocations for each shard in the stream.
- The number of shards in the stream: How many shards are there in the stream? Multiplying this with the concurrent batches per shard gives you the maximum concurrency for each subscriber function. Please note that this setting is only applicable for the Kinesis provisioned mode.
With SNS FIFO, you can’t fan out messages to Lambda functions directly (see official documentation here [3]).

This is why you always need to have SQS FIFO in the mix as well.
Like Kinesis, event orders are preserved within a group and identified by the group ID in the messages. Recently, AWS introduced a max concurrency setting for SQS event sources (see here [4]). This solves the long-standing problem of using reserved concurrency for SQS functions.
So, now you can also use EventSourceMapping for SQS to control the concurrency of your application. You don’t have to micro-manage the Lambda concurrency units in the region and worry about not having enough units for other functions to scale into.
Dynamic concurrency control
Both approaches we have discussed so far allow us to control the concurrency of our serverless applications. This is useful, especially when we’re working with less scalable downstream systems.
In both cases, we have a ballpark concurrency value in mind. That value is informed by our understanding of what these downstream systems can handle. However, in both cases, these settings are static. We would likely need to change our code and redeploy our application with the new settings to change them.
But what if the situation calls for a system that can dynamically change its own concurrency based on external conditions?
I have previously written about this approach [5] and how to implement an “async circuit breaker” for Kinesis functions.
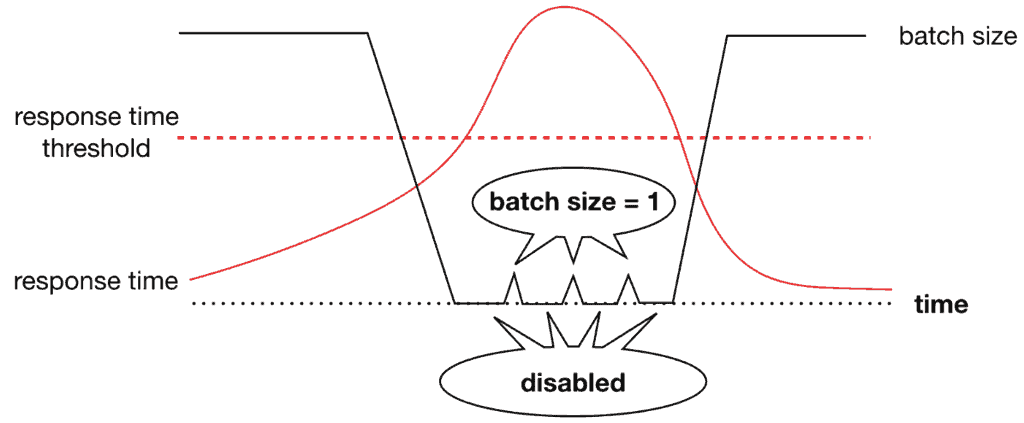
In 2018, I also wrote about how to implement “semaphores” for Step Functions (see the post here [6]).
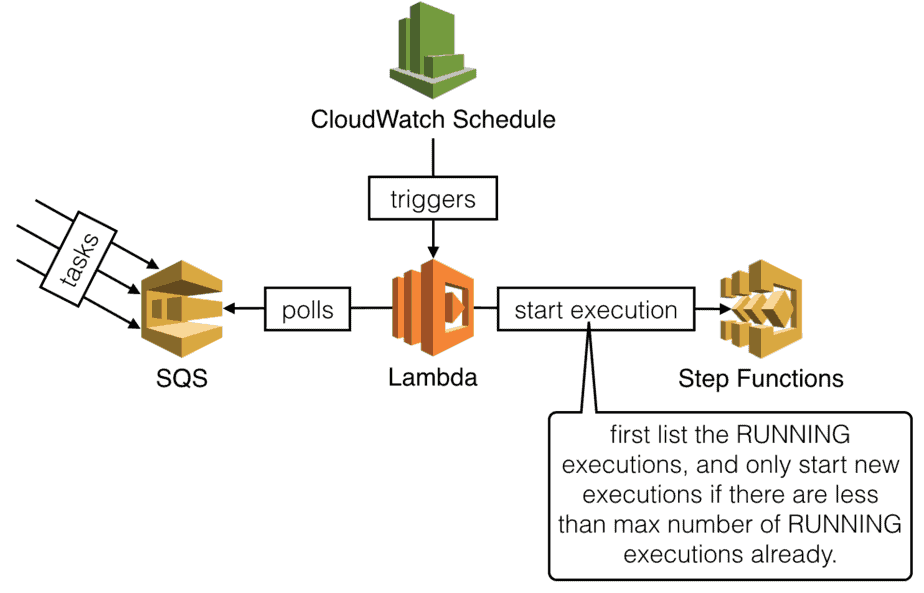
The implementation details from these posts are fairly outdated now, but the core principles behind them are still relevant.
Metaprogramming: Lambda functions can change their own settings on the fly by making API calls to the Lambda service.
They can react to external conditions, such as changes to the response time and error rate from downstream systems, and adapt their concurrency settings accordingly.
You would need some additional concurrency control here to ensure that only one invocation can change the relevant settings at a time.
Using a controller process to manage concurrency: Instead of the functions changing their own settings on the fly, you can have a separate process to manage them.
Here, you can distinguish between “blocking an ongoing execution from entering a critical section” and “don’t start another execution at all”. The trade-offs I discussed in the Step Functions semaphore post are still relevant. Most importantly, locking an execution mid-way makes choosing sensible timeouts more difficult.
Luckily, with Step Functions, we can now implement callback patterns using task tokens [7]. No more polling loops in the middle of your state machine!
You can still apply this approach outside of the context of step functions. For example, you can have a separate (cron-triggered) Lambda function change the concurrency of your main function.
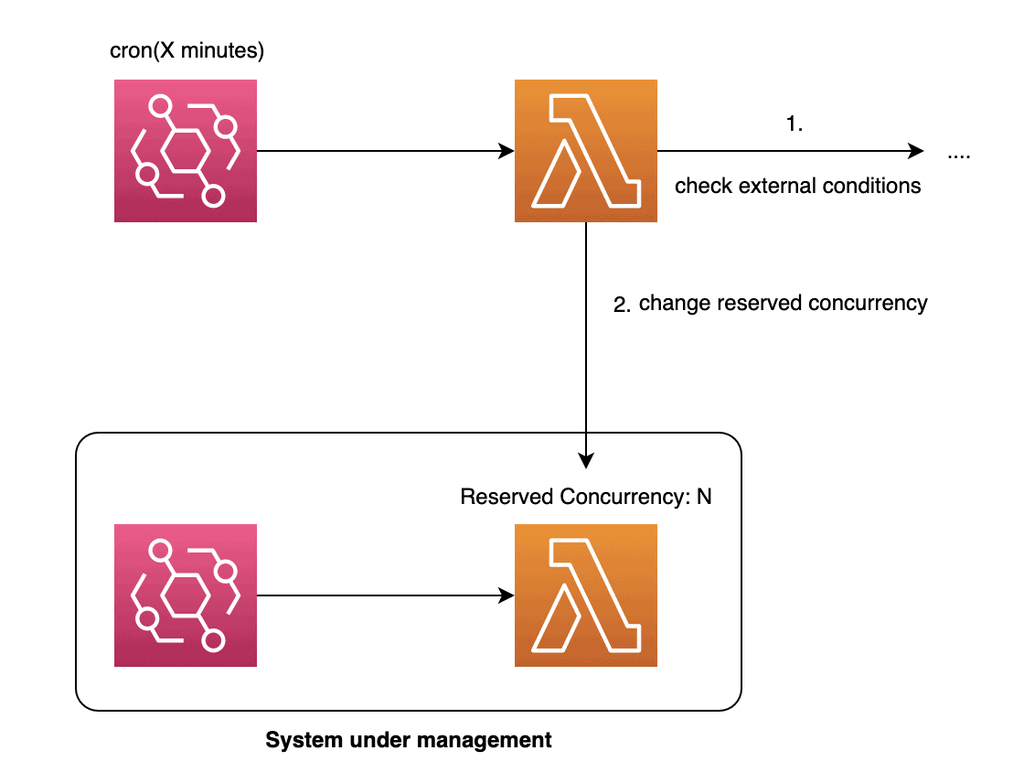
Applications that require this kind of dynamic concurrency control are few and far between. But in the unlikely event that you need something like this, I hope I have given you some food for thought and some ideas on how you might approach the problem!
Wrap up
I hope you have found this article insightful. It’s not the most flashy topic, but it’s a real-life problem people often face.
If you want to learn more about building serverless architectures for the real world, check out my upcoming workshop [8]. I will cover topics such as testing, security, observability and much more.
Hope to see you there.
Links
[1] Asynchronous invocations for Lambda functions
[2] The EventSourceMapping object
[3] Message delivery for SNS FIFO topics
[4] Introducing maximum concurrency of AWS Lambda functions when using Amazon SQS as an event source
[5] Async circuit breaker for AWS Lambda
[6] Step Functions: how to implement semaphores for state machines
[7] Step Function callback pattern examples
[8] Production-Ready Serverless workshop
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.