

Yan Cui
I help clients go faster for less using serverless technologies.

I spent time with a client this week to solve an interesting problem. We need to dynamically adjust the number of concurrent requests to a downstream service based on response time and error rate. This is a common challenge when integrating with third parties, so we decided to share how we implemented an async circuit breaker for AWS Lambda.
The problem
My client is in the financial services sector, and they integrate with over 50 service providers. They have API access to the providers’ data, and they need to fetch data from every provider daily.
However, many of these providers place restrictions and rate limits on their APIs, for example:
- You can only access the API during off-peak hours.
- You cannot access the API during the weekly maintenance window.
- You can only make X concurrent requests to the API.
My client has implemented a scheduler service to manage the timing constraints. The scheduler knows when to kick off the ingestion process for each provider. But there’s also a secondary process in which their users (financial advisers) can schedule ad-hoc ingestions themselves.
And there are other additional contexts that we had to keep in mind:
- The APIs follow an established industry standard. Unfortunately, they can only return one record at a time.
- The API response times are highly variable – anything from 5ms to 70s.
- The amount of data the client needs to fetch varies from provider to provider. Some have just a few thousand records, while others have hundreds of thousands of records.
- We should not fetch the same record from a provider more than once per day due to usage limits.
- This ingestion process is one of the most business-critical parts of their system. The migration to this new system must be managed carefully to minimise the potential impact on their customers.
The solution
To solve the aforementioned challenge, we need a mechanism to:
- Fetch records from a provider’s API slowly and steadily. The process needs to be reliable but can take several hours if need be.
- Only fetch a maximum of X records concurrently.
- Gradually reduce the concurrency when the provider API’s response time or error rate escalates.
This is essentially an async circuit breaker.
Rather than implementing such a mechanism from scratch, we leveraged the built-in batching support with Kinesis and Lambda.
In our proposed setup:
- Every provider has a Kinesis stream.
- The scheduler service enqueues the records we must fetch into the stream.
- A ventilator Lambda function would receive records in batches and fan them out to a worker function (via direct function invocation).
- There are many different worker functions, one for every provider. This is because most providers have provider-specific business logic.
- To avoid processing the same record twice on the same day, the ventilator tracks records that have been processed today in a DynamoDB table.
- To support retrying failed records, the ventilator also tracks the number of attempts at processing each record in the same DynamoDB table. When it encounters partial failures, the ventilator will increment the attempts count for the failed records and except. Kinesis would automatically retry the same batch of records for us. On subsequent attempts, previously successful records are ignored.
From a high level, the system looks like this:
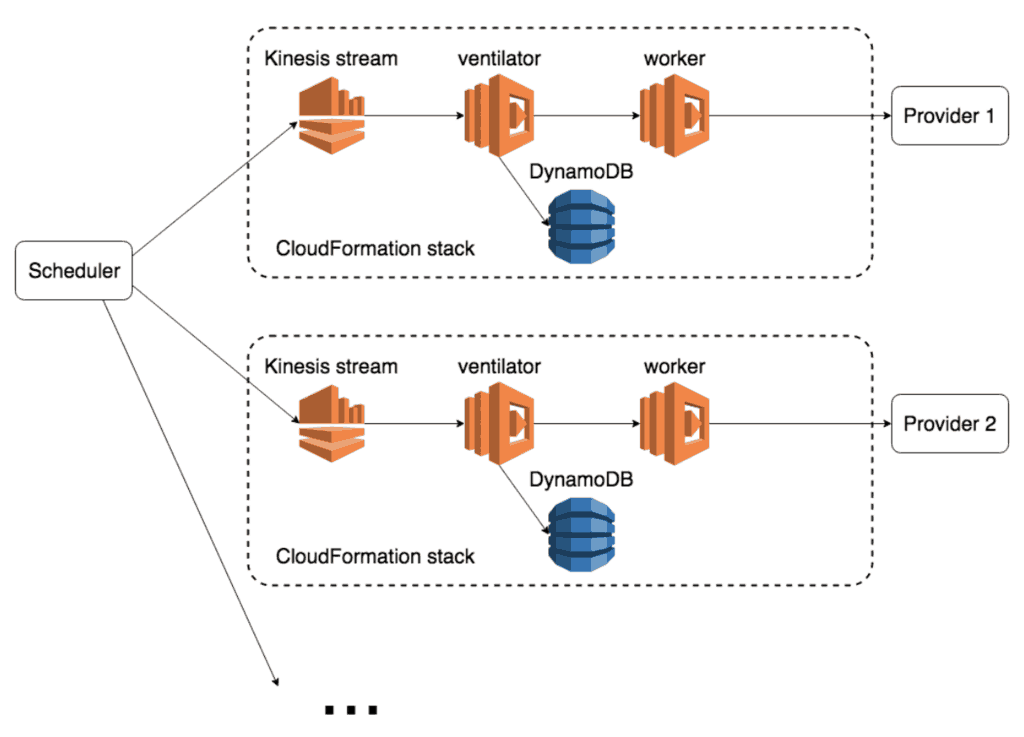
This design does not deliver maximum throughput, which is by design! As discussed earlier, this is due to the provider APIs’ daily usage limits and scalability concerns.
Every provider has its own CloudFormation stack with the Kinesis stream, the ventilator and worker Lambda functions, and the DynamoDB table. This setup makes it easy to gradually migrate to the new system, one provider at a time.
The Async Circuit Breaker
The one stream per provider configuration lets us control concurrency using the batch size of the Kinesis event source mapping. The ventilator function can, therefore, self-adjust its batch size by updating the Kinesis event source mapping [1].
This is the most important part of the async circuit breaker.
As the provider API’s response time increases, the ventilator can respond by reducing its batch size. This gives the API a chance to catch its breath and recover. When the response time returns to acceptable levels, the ventilator can gradually increase its batch size back to previous levels.
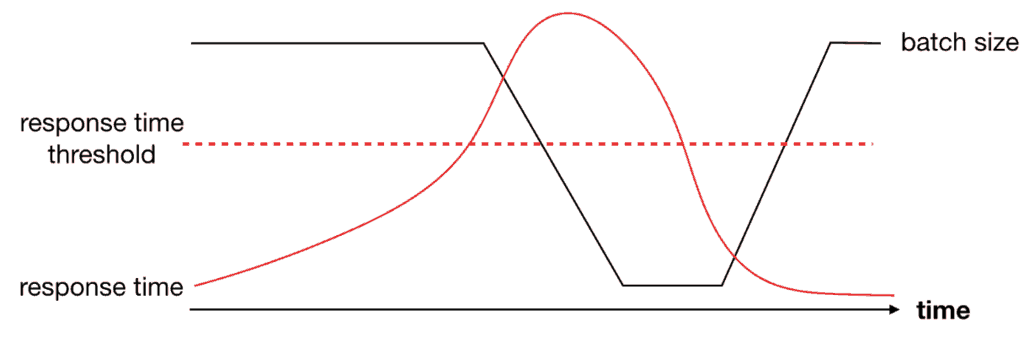
If the provider API still struggles at a batch size of 1, something is clearly wrong. This is when the async circuit breaker should be tripped, and we should stop all processing altogether.
You can’t change the batch size to 0, but you can disable the Kinesis event source mapping. When you re-enable it later, Kinesis will push events to the ventilator from where it stopped before, as if nothing’s happened.
However, if the Kinesis event source is disabled, something else must trigger the ventilator to wake up later. For this, we have a CloudWatch schedule that triggers the ventilator function every 10 minutes.
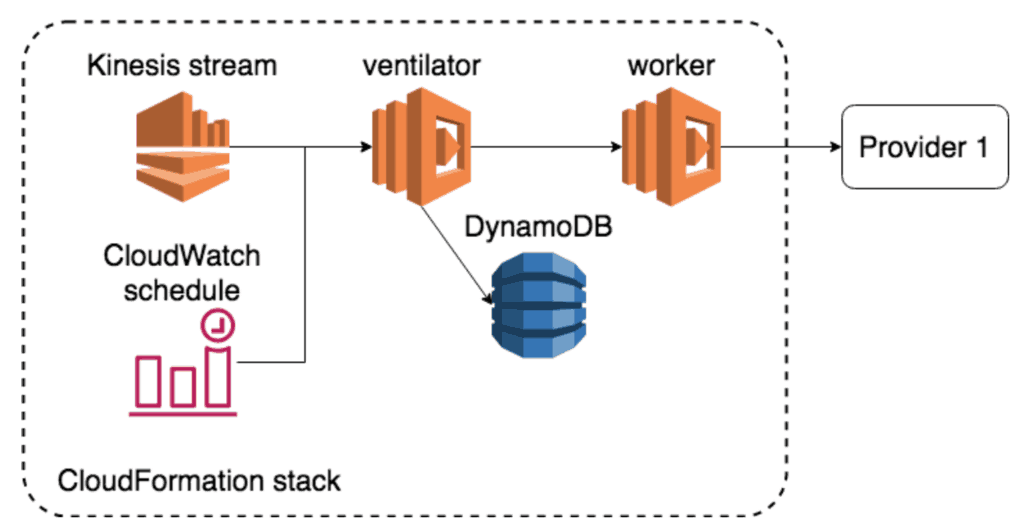
If the Kinesis event source is already enabled, these CloudWatch-triggered invocations do nothing. When Kinesis is disabled, the ventilator can re-enable it at a batch size of 1. This allows one request to the provider API on the next invocation by Kinesis. If the response time is still above the threshold, we will disable Kinesis again and the cycle repeats.
When the provider API responds to requests in a timely fashion, the Kinesis stream stays enabled, and the ventilator function will gradually restore its previous batch size.
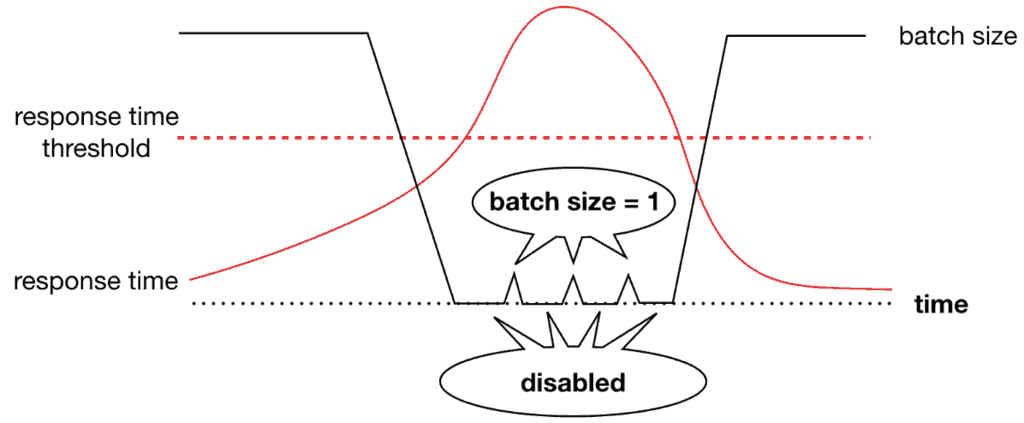
This is the classic circuit breaker pattern [2] applied to stream processing.
Show me how it works!
If you want to see how this can work in practice, I put together a demo app for illustration purposes. You can find the source code here [3]. Follow the instructions in the README to deploy the demo app and pump data using the provided feed-stream script.
With this demo app, I can adjust the ratio of slow and erroneous responses from the worker function via its environment variables.
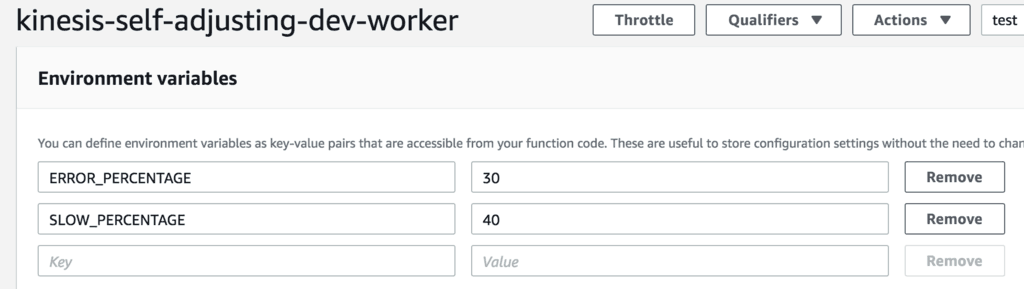
When I do, you will soon see the ventilator take action to reduce its batch size. It will adjust the batch size, incrementing and decrementing accordingly.

You can also create a metric filter to extract the batch size from the logs and turn it into a metric in CloudWatch. This lets you observe how the batch size changes over time.

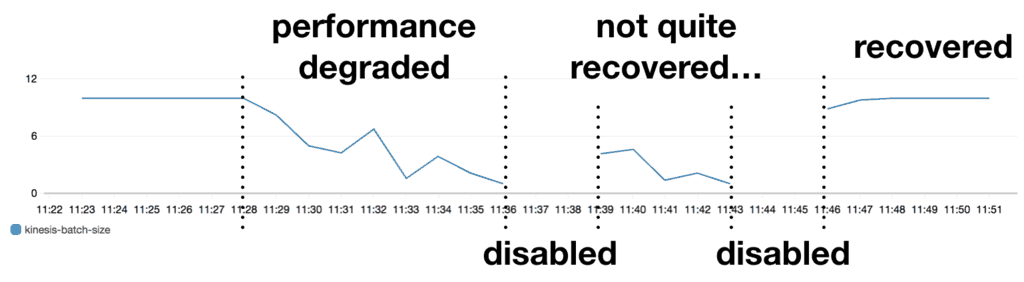
If the elevated response time and error rate continue, the ventilator function will disable its Kinesis event source.

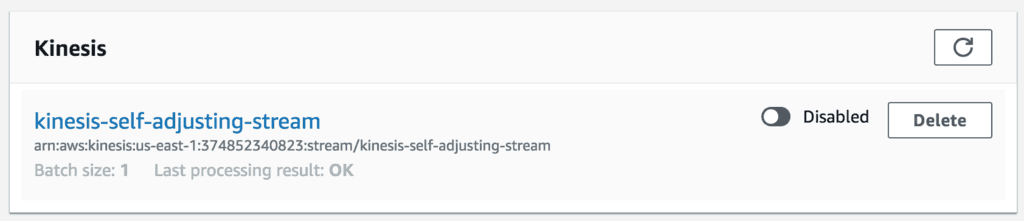
The cron job will then re-enable the stream every 10 minutes.

And if the worker function has recovered.
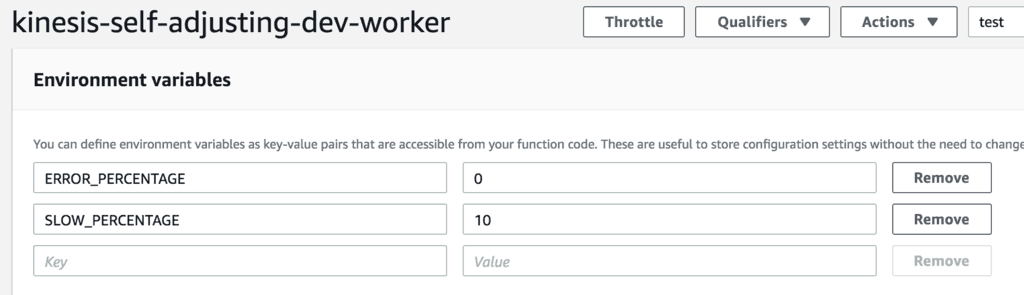
Then, the ventilator function will gradually increase its batch size.
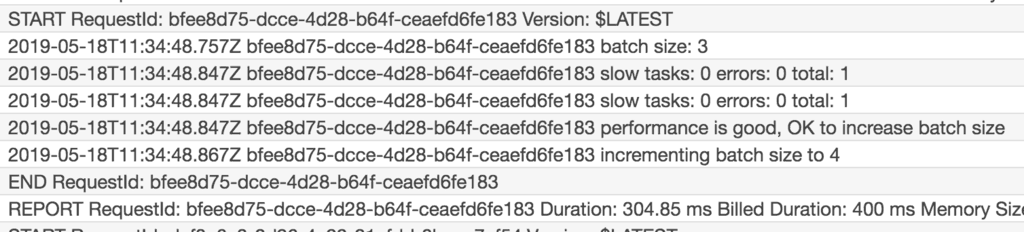
Until it eventually returns to its original batch size of 10. If you monitor how the batch size changes along the way, you will probably see something along the lines of:
Summary
In this post, we discussed a design for an async circuit breaker for Lambda functions processing Kinesis stream events. The async circuit breaker can adapt its throughput based on performance. In doing so, we can carefully tune the number of concurrent requests our system makes against third-party APIs and stay within their operational limits. We also discussed how such a design could implement the circuit breaker pattern and take the foot off the paddle entirely when the third-party API is struggling.
This post was initially written in 2019; Lambda had no SQS support at the time. If we were to do this in 2024, then a SQS FIFO queue would be a better, more cost-efficient solution instead of Kinesis.
Links
[1] Lambda’s UpdateEventSourceMapping API
[2] The circuit breaker pattern
[3] Source code for a demo app
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.