
Yan Cui
I help clients go faster for less using serverless technologies.

Here at DAZN, we are migrating from our legacy platform into a brave new world of microfrontends and microservices. Along the way, we also discovered the delights that AWS Step Function has to offer, for example…
- flexible error handling and retry
- the understated ability to wait between tasks
- the ability to mix automated steps with activities that require human intervention
In some cases, we need to control the number of concurrent state machine executions that can access a shared resource. This might be a business requirement. Or it could be due to scalability concerns for the shared resource. It might also be a result of the design of our state machine which makes it difficult to parallelise.
We came up with a few solutions that fall into two general categories:
- Control the number of executions that you can start
- Allow concurrent executions to start, but block an execution from entering the critical path until it’s able to acquire a semaphore (i.e. a signal to proceed)
Control the number of concurrent executions
You can control the MAX number of concurrent executions by introducing a SQS queue. A CloudWatch schedule will trigger a Lambda function to…
- check how many concurrent executions there are
- if there are N executions, then we can start MAX-N executions
- poll SQS for MAX-N messages, and start a new execution for each
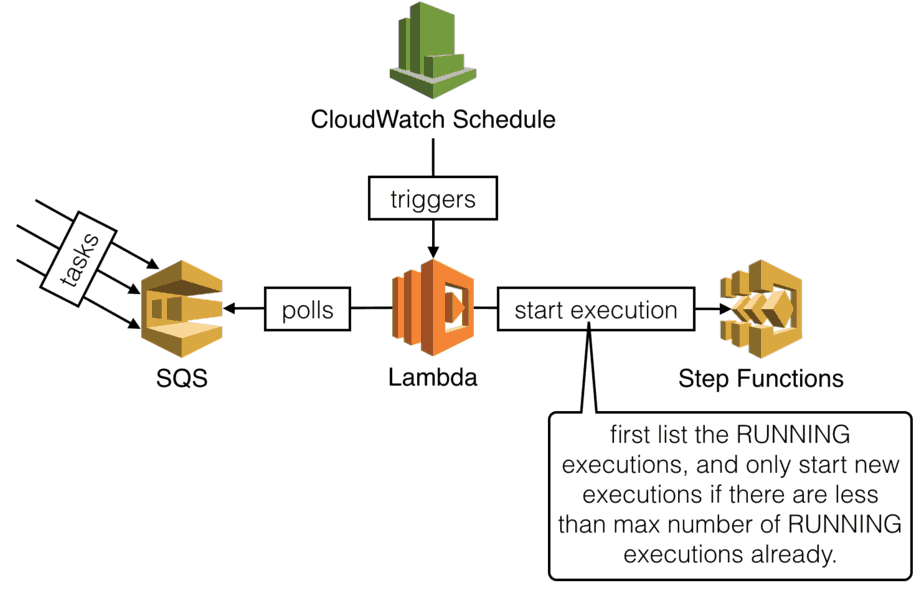
We’re not using the new SQS trigger for Lambda here because the purpose is to slow down the creation of new executions. Whereas the SQS trigger would push tasks to our Lambda function eagerly.
Also, you should use a FIFO queue so that tasks are processed in the same order they’re added to the queue.
Block execution using semaphores
You can use the ListExecutions API to find out how many executions are in the RUNNING state. You can then sort them by startDate and only allow the eldest executions to transition to states that access the shared resource.
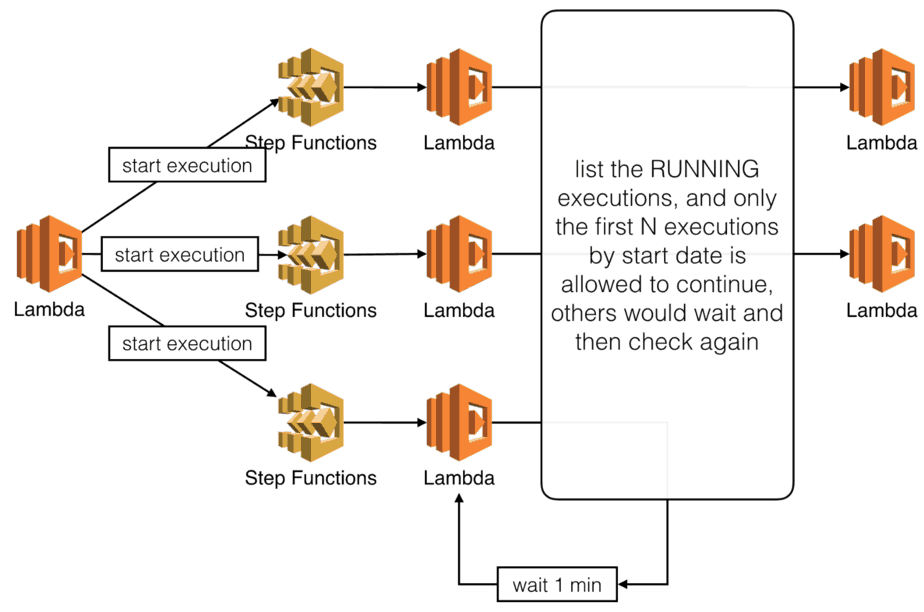
Take the following state machine for instance.
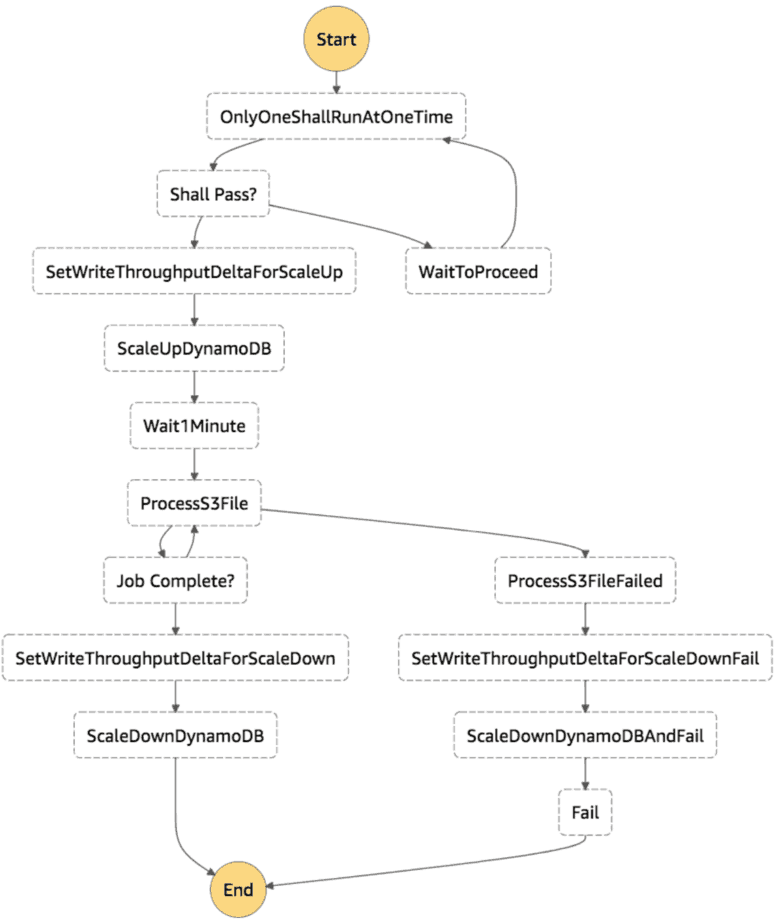
The OnlyOneShallRunAtOneTime state invokes the one-shall-pass Lambda function and returns a proceed flag. The Shall Pass? state then branches the flow of this execution based on the proceed flag.
OnlyOneShallRunAtOneTime:
Type: Task
Resource: arn:aws:lambda:us-east-1:xxx:function:one-shall-pass
Next: Shall Pass?
Shall Pass?:
Type: Choice
Choices:
- Variable: $.proceed # check if this execution should proceed
BooleanEquals: true
Next: SetWriteThroughputDeltaForScaleUp
Default: WaitToProceed # otherwise wait and try again later
WaitToProceed:
Type: Wait
Seconds: 60
Next: OnlyOneShallRunAtOneTime
The tricky thing here is how to associate the Lambda invocation with the corresponding Step Function execution. Unfortunately, Step Functions does not pass the execution ARN to the Lambda function. Instead, we have to pass the execution name as part of the input when we start the execution.
const name = uuid().replace(/-/g, '_')
const input = JSON.stringify({ name, bucketName, fileName, mode })
const req = { stateMachineArn, name, input }
const resp = await SFN.startExecution(req).promise()
When the one_shall_pass function runs, it can use the execution name from the input. It’s then able to match the invocation against the executions returned by ListExecutions.
In this particular case, only the eldest execution can proceed. All other executions would transition to the WaitToProceed state.
module.exports.handler = async (input, context) => {
const executions = await listRunningExecutions()
Log.info(`found ${executions.length} RUNNING executions`)
const oldest = _.sortBy(executions, x => x.startDate.getTime())[0]
Log.info(`the oldest execution is [${oldest.name}]`)
if (oldest.name === input.name) {
return { ...input, proceed: true }
} else {
return { ...input, proceed: false }
}
}
Compare the approaches
Let’s compare the two approaches against the following criteria:
- Scalability. How well does the approach cope as the number of concurrent executions goes up?
- Simplicity. How many moving parts does the approach add?
- Cost. How much extra cost does the approach add?
Scalability
Approach 2 (blocking executions) has two problems when you have a large number of concurrent executions.
First, you can hit the regional throttling limit on the ListExecutions API call.
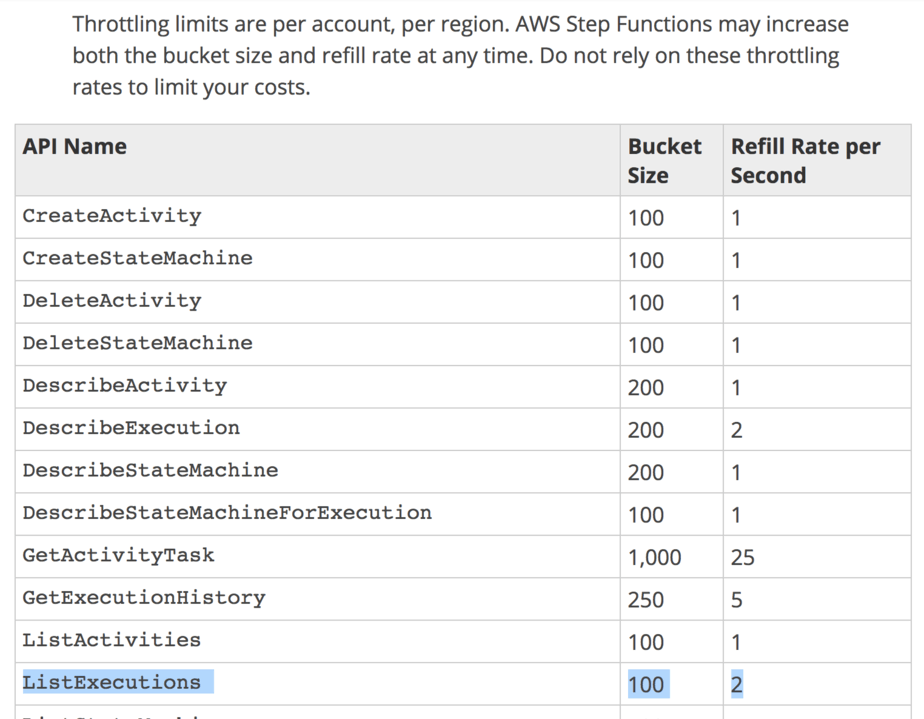
Second, if you have configured timeout on your state machine (and you should!) then they can also timeout. This creates backpressure on the system.
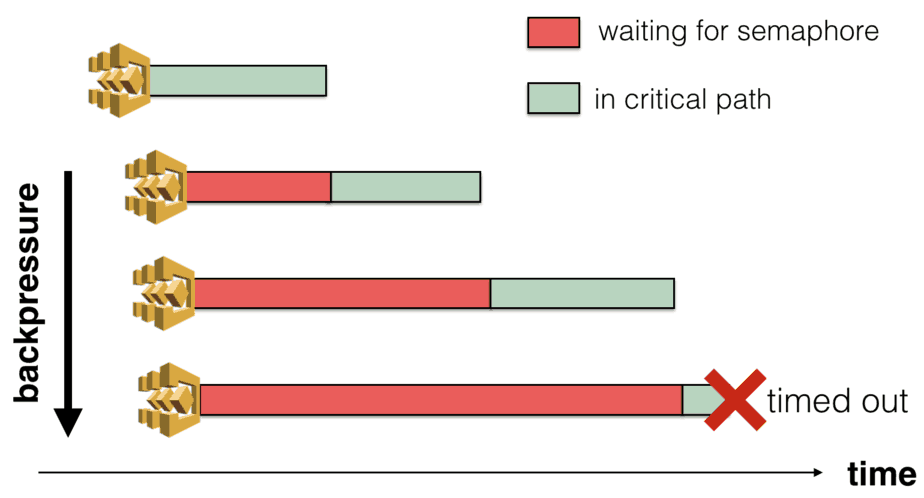
Approach 1 (with SQS) is far more scalable by comparison. Queued tasks are not started until they are allowed to start so no backpressure. Only the cron Lambda function needs to list executions, so you’re also unlikely to reach API limits.
Simplicity
Approach 1 introduces new pieces to the infrastructure – SQS, CloudWatch schedule and Lambda. Also, it forces the producers to change as well.
With approach 2, a new Lambda function is needed for the additional step, but it’s part of the state machine.
Cost
Approach 1 introduces minimal baseline cost even when there are no executions. However, we are talking about cents here…
Approach 2 introduces additional state transitions, which is around $25 per million. See the Step Functions pricing page for more details. Since each execution will incur 3 transitions per minute whilst it’s blocked, the cost of these transitions can pile up quickly.
Conclusions
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.