
Yan Cui
I help clients go faster for less using serverless technologies.

First of all, I would like to thank all of you for following and reading my content. My post on centralised logging for AWS Lambda has been viewed more than 20K times by now, so it is clearly a challenge that many of you have run into.
In the post, I outlined an approach of using a Lambda function to ship all your Lambda logs from CloudWatch Logs to a log aggregation service such as Logz.io.
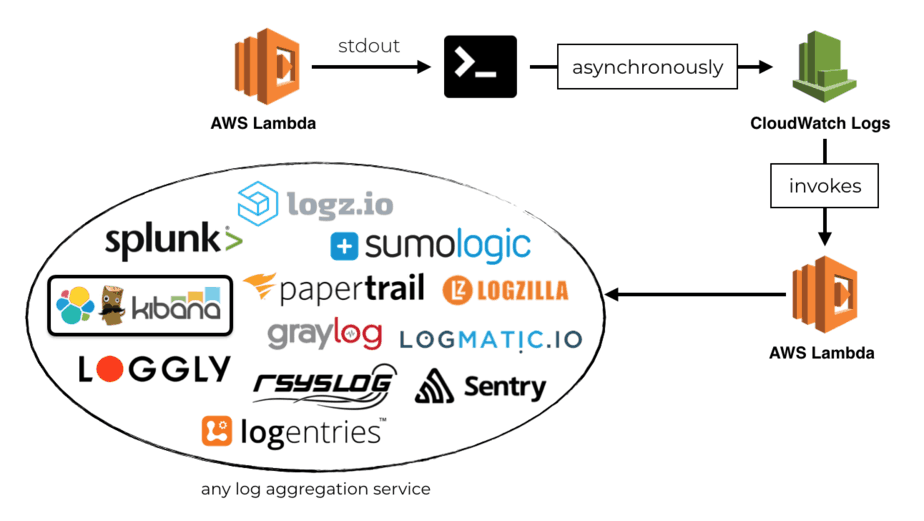
In the demo project, I also included functions to:
- auto-subscribe new log groups to the log-shipping function
- auto-update the retention policy of new log groups to X number of days (default is Never Expire which has a long term cost impact)
This approach works well when you start out. However, you can run into some serious problems at scale.
Mind the concurrency
When processing CloudWatch Logs with a Lambda function, you need to be mindful of the no. of concurrent executions it creates. Because CloudWatch Logs is an asynchronous event source for Lambda.
When you have 100 functions running concurrently, they will each push logs to CloudWatch Logs. This in turn can trigger 100 concurrent executions of the log shipping function. Which can potentially double the number of functions that are concurrently running in your region. Remember, there is a soft, regional limit of 1000 concurrent executions for all functions!
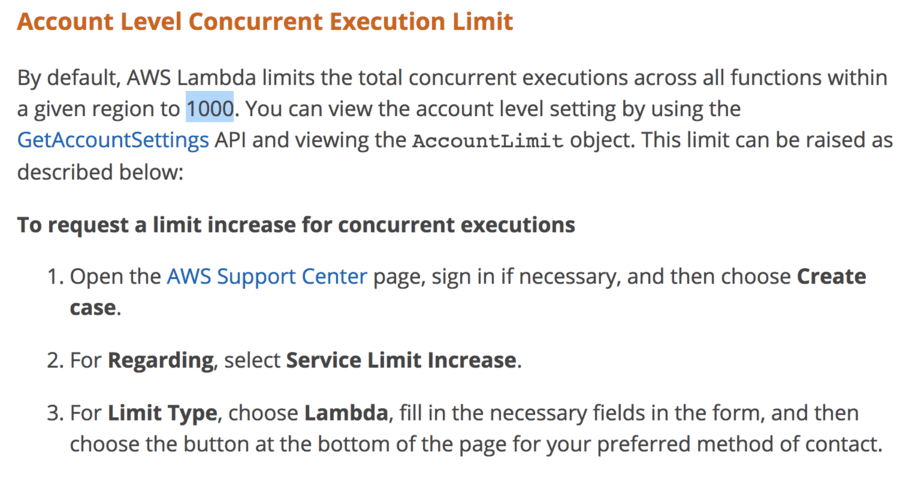
This means your log shipping function can cause cascade failures throughout your entire application. Critical functions can be throttled because too many executions are used to push logs out of CloudWatch Logs – not a good way to go down ;-)
You can set the Reserved Concurrency for the log shipping function, to limit its max number of concurrent executions. However, you risk losing logs when the log shipping function is throttled.
You can also request a raise to the regional limit and make it so high that you don’t have to worry about throttling.
A better approach at scale is to use Kinesis
However, I would suggest that a better approach is to stream the logs from CloudWatch Logs to a Kinesis stream first. From there, a Lambda function can process the logs and forward them on to a log aggregation service.
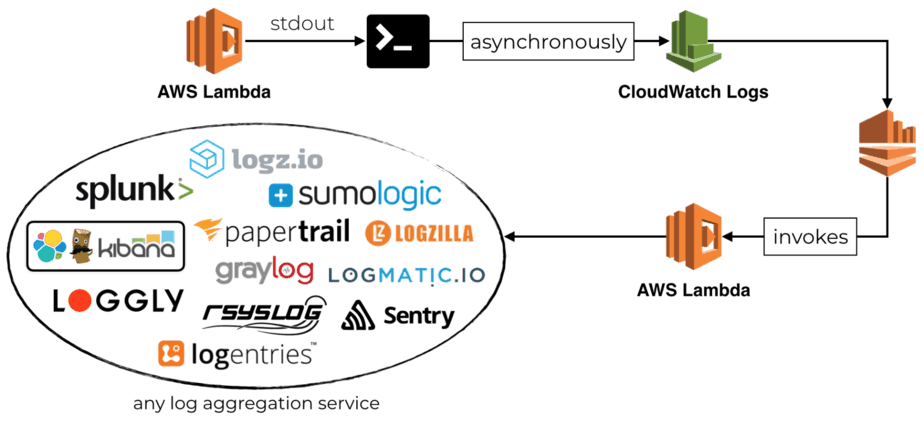
With this approach, you have control the concurrency of the log shipping function. As the number of log events increases, you can increase the number of shards in the Kinesis stream. This would also increase the number of concurrent executions of the log shipping function.

Take a look at this repo to see how it works. It has a nearly identical set up to the demo project for the previous post:
- a
set-retentionfunction that automatically updates the retention policy for new log groups to 7 days - a
subscribefunction automatically subscribes new log groups to a Kinesis stream - a
ship-logs-to-logziofunction that processes the log events from the above Kinesis stream and ships them to Logz.io - a
process_allscript to subscribe all existing log groups to the same Kinesis stream
You should also check out this post to see how you can autoscale Kinesis streams using CloudWatch and Lambda.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.