
Yan Cui
I help clients go faster for less using serverless technologies.

Following on from the last post where we discussed 3 useful tips for working effectively with Lambda and Kinesis, let’s look at how you can use Lambda to help you auto scale Kinesis streams.
Auto-scaling for DynamoDB and Kinesis are two of the most frequently requested features for AWS, as I write this post I’m sure the folks at AWS are working hard to make them happen. Until then, here’s how you can roll a cost effective solution yourself.
From a high level, we want to:
- scale up Kinesis streams quickly to meet increases in load
- scale down under-utilised Kinesis streams to save cost
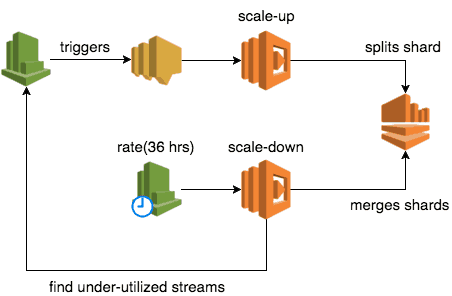
Scaling Up
Reaction time is important for scaling up, and from personal experience I find polling CloudWatch metrics to be a poor solution because:
- CloudWatch metrics are usually over a minute behind
- depending on polling frequency, your reaction time is even further behind
- high polling frequency has a small cost impact
sidebar: I briefly experimented with Kinesis scaling utility from AWS Labs before deciding to implement our own solution. I found that it doesn’t scale up fast enough because it uses this polling approach, and I had experienced similar issues around reaction time with dynamic-dynamodb too.
Instead, prefer a push-based approach using CloudWatch Alarms.
Whilst CloudWatch Alarms is not available as trigger to Lambda functions, you can use SNS as a proxy:
- add a SNS topic as notification target for CloudWatch Alarm
- add the SNS topic as trigger to a Lambda function to scale up the stream that has tripped the alarm
WHAT metrics?
You can use a number of metrics for triggering the scaling action, here are a few to consider.
WriteProvisionedThroughputExceeded (stream)
The simplest way is to scale up as soon as you’re throttled. With a stream-level metric you only need to set up the alarm once per stream and wouldn’t need to adjust the threshold value after each scaling action.
However, since you’re reusing the same CloudWatch Alarm you must remember to set its status to OK after scaling up.
IncomingBytes and/or IncomingRecords (stream)
You can scale up preemtively (before you’re actually throttled by the service) by calculating the provisioned throughput and then setting the alarm threshold to be, say 80% of the provisioned throughput. After all, this is exactly what we’d do for scaling EC2 clusters and the same principle applies here – why wait till you’re impacted by load when you can scale up just ahead of time?
However, we need to manage some additional complexities EC2 auto scaling service usually takes care of for us:
- if we alarm on both
IncomingBytesandIncomingRecordsthen it’s possible to overscale (impacts cost) if both triggers around the same time; this can be mitigated but it’s down to us to ensure only one scaling action can occur at once and that there’s a cooldown after each scaling activity - after each scaling activity, we need to recalculate the provisioned throughput and update the alarm threshold(s)
WriteProvisionedThroughputExceeded (shard)
IncomingBytes and/or IncomingRecords (shard)
With shard level metrics you get the benefit of knowing the shard ID (in the SNS message) so you can be more precise when scaling up by splitting specific shard(s). The downside is that you have to add or remove CloudWatch Alarms after each scaling action.
HOW to scale up
To actually scale up a Kinesis stream, you’ll need to increase the no. of active shards by splitting one of more of the existing shards. One thing to keep in mind is that once a shard is split into 2, it’s no longer ACTIVE but it will still be accessible for up to 7 days (depending on your retention policy setting) and you’ll still pay for it the whole time!
Broadly speaking, you have two options available to you:
- use UpdateShardCount and let Kinesis figure out how to do it
- choose one or more shards and split them yourself using SplitShard
Option 1 is far simpler but comes with some heavy baggage:
- because it only supports
UNIFORM_SCALING(at the time of writing) it means this action can result in many temporary shards being created unless you double up each time (remember, you’ll pay for all those temporary shards for up to 7 days) - doubling up can be really expensive at scale (and possibly unnecessary depending on load pattern)
- plus all the other limitations
As for Option 2, if you’re using shard level metrics then you can split only the shards that have triggered the alarm(s). Otherwise, a simple strategy would be to sort the shards by their hash range and split the biggest shards first.
Scaling Down
To scale down a Kinesis stream you merge two adjacent shards. Just as splitting a shard leaves behind an inactive shard that you’ll still pay for, merging shards will leave behind two inactive shards!
Since scaling down is primarily a cost saving exercise, I strongly recommend that you don’t scale down too often as you could easily end up increasing your cost instead if you have to scale up soon after scaling down (hence leaving behind lots inactive shards).
Since we want to scale down infrequently, it makes more sense to do so with a cron job (ie. CloudWatch Event + Lmabda) than to use CloudWatch Alarms. As an example, after some trial and error we settled on scaling down once every 36 hours, which is 1.5x our retention policy of 24 hours.
WHICH stream
When the cron job runs, our Lambda function would iterate through all the Kinesis streams and for each stream:
- calculate its provisioned throughput in terms of both
bytes/sandrecords/s - get 5 min metrics (
IncomingBytesandIncomingRecords) over the last 24 hours - if all the data points over the last 24 hours are below 50% of the provisioned throughput then scale down the stream
The reason we went with 5 min metrics is because that’s the granularity the Kinesis dashboard uses and allows me to validate my calculations (you don’t get bytes/s and records/s values from CloudWatch directly, but will need to calculate them yourself).
Also, we require all datapoints over the last 24 hours to be below the 50% threshold to be absolutely sure that utilization level is consistently below the threshold rather than a temporary blip (which could be a result of an outage for example).
HOW to scale down
We have the same trade-offs between using UpdateShardCount and doing-it-yourself with MergeShards as scaling up.
Wrapping Up
To set up the initial CloudWatch Alarms for a stream, we have a repo which hosts the configurations for all of our Kinsis streams, as well as a script for creating any missing streams and associated CloudWatch Alarms (using CloudFormation templates).
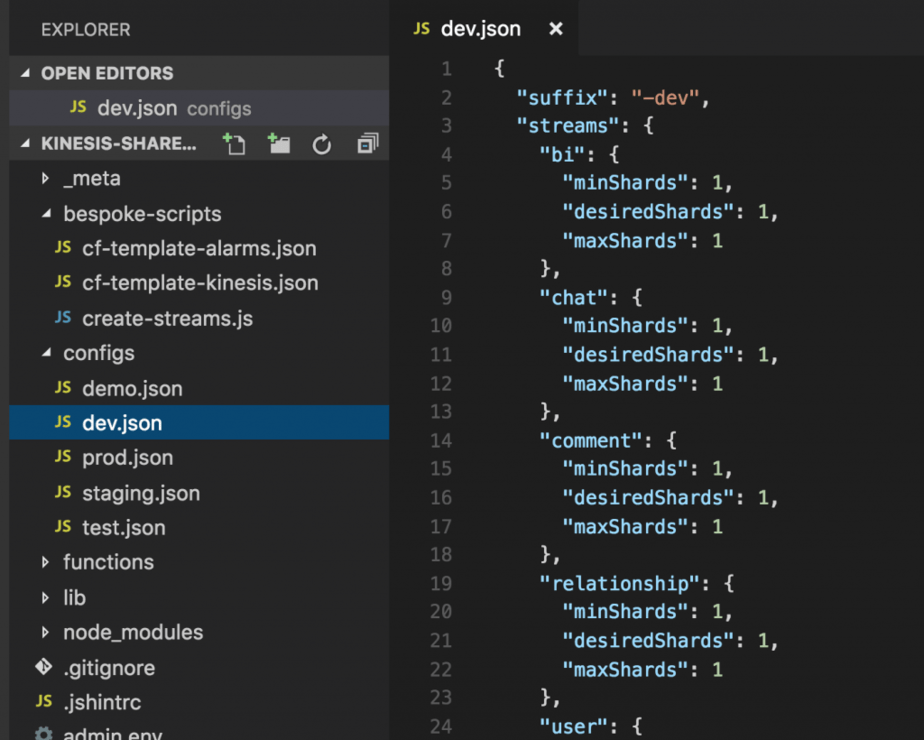
Additionally, as you can see from the screenshot above, the configuration file also specifies the min and max no. of shards for each Kinesis stream. When the create-streams script creates a new stream, it’ll be created with the specified desiredShards no. of shards.
Hope you enjoyed this post, please let me know in the comments below if you are doing something similar to auto-scale your Kinesis streams and if you have any experience you’d like to share.
Links
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Hi,
I am working on this and came across your post. Can you please share your project on github so that I can start experimenting on.
Hi Javed, unfortunately I won’t be able to share the code itself, the company where I did this work folded last year and I don’t know who to consult about the legality of sharing it publicly (someone still owns the rights to the intellectual properties, but I just don’t know who it is now).
Hi,
Thanks for sharing information with everyone.
I would like to know charging on the close shards, reference to the following link, AWS won’t charge it
https://forums.aws.amazon.com/thread.jspa?threadID=240351
Also, when we split the shards from X to 2X, Is it also spawns the lambda function 2X times?
Hi Bhushan,
Thank you for that clarification, I always thought they’re charged for another 24 hours!
When you say “is it also spawns the lambda function 2X times?” I assume you meant the function that processes the Kinesis events. Yes, according to the documentation it’s one invocation per shard, so if you split a shard into 2 then each of the new shards would get its own invocation, and I imagine the closed shard would keep invoking its own invocation of your function until it reaches the end of that shard as well.
https://docs.aws.amazon.com/lambda/latest/dg/scaling.html
Hi again,
Thanks for the reply.
I have sort of tried to implement same architecture what you have described here, but it seems not fulfilling our goal as we don’t require 24/7 streaming.
Scenario (in one line) is we need to use Kinesis on demand
So I’m looking to creating a Kinesis with X numbers of shards (number is determined by precalculated traffic) and deleting it after processing all records by mapped Lambda function
Can you please post your quick thoughts on it?
Hi Bhushan,
In that case, maybe you can consider a cron job (if that demand is predictable) using CloudWatch Schedule, and have it kick off a Lambda function to call the reshard API call on Kinesis to scale it up just before you need the extra throughput, and then have another cron job to scale it back down using the same reshard API call.
If you’re thinking of creating and deleting the stream, as opposed to increasing & decreasing the no. of shards, then it’s a slightly more complicated workflow – you need to create stream, wait for it to finish creating, then subscribe the Lambda function to it, and then do the reverse when you want to delete.
If you need to know when the Lambda function has process all the events, then you might have to also implement additional tracking (maybe have the functions store a timestamp or id for the latest record they have processed, or just a simple counter – how many events were published to Kinesis, and how many events were processed) and then have something else determine when all the records have been processed.