
Yan Cui
I help clients go faster for less using serverless technologies.

At Yubl, we arrived at a non-trivial serverless architecture where Lambda and Kinesis became a prominent feature of this architecture.
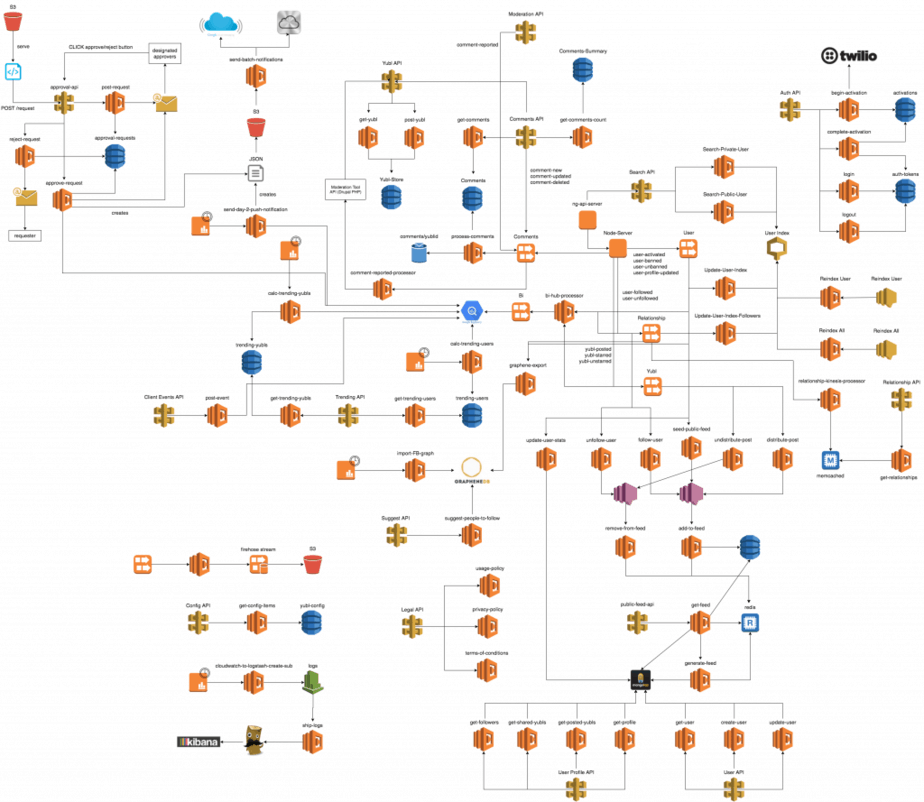
Whilst our experience using Lambda with Kinesis was great in general, there was a couple of lessons that we had to learn along the way. Here are 3 useful tips to help you avoid some of the pitfalls we fell into and accelerate your own adoption of Lambda and Kinesis.
Consider partial failures
From the Lambda documentation:
AWS Lambda polls your stream and invokes your Lambda function. Therefore, if a Lambda function fails, AWS Lambda attempts to process the erring batch of records until the time the data expires…
Because the way Lambda functions are retried, if you allow your function to err on partial failures then the default behavior is to retry the entire batch until success or the data expires from the stream.
To decide if this default behavior is right for you, you have to answer certain questions:
- can events be processed more than once?
- what if those partial failures are persistent? (perhaps due to a bug in the business logic that is not handling certain edge cases gracefully)
- is it more important to process every event till success than keeping the overall system real-time?
In the case of Yubl (which was a social networking app with a timeline feature similar to Twitter) we found that for most of our use cases it’s more important to keep the system flowing than to halt processing for any failed events, even if for a minute.
For instance, when you create a new post, we would distribute it to all of your followers by processing the yubl-posted event. The 2 basic choices we’re presented with are:
- allow errors to bubble up and fail the invocation—we give every event every opportunity to be processed; but if some events fail persistently then no one will receive new posts in their feed and the system appears unavailable
- catch and swallow partial failures—failed events are discarded, some users will miss some posts but the system appears to be running normally to users (even affected users might not realize that they had missed some posts)
(of course, it doesn’t have to be a binary choice, there’s plenty of room to add smarter handling for partial failures, which we will discuss shortly)
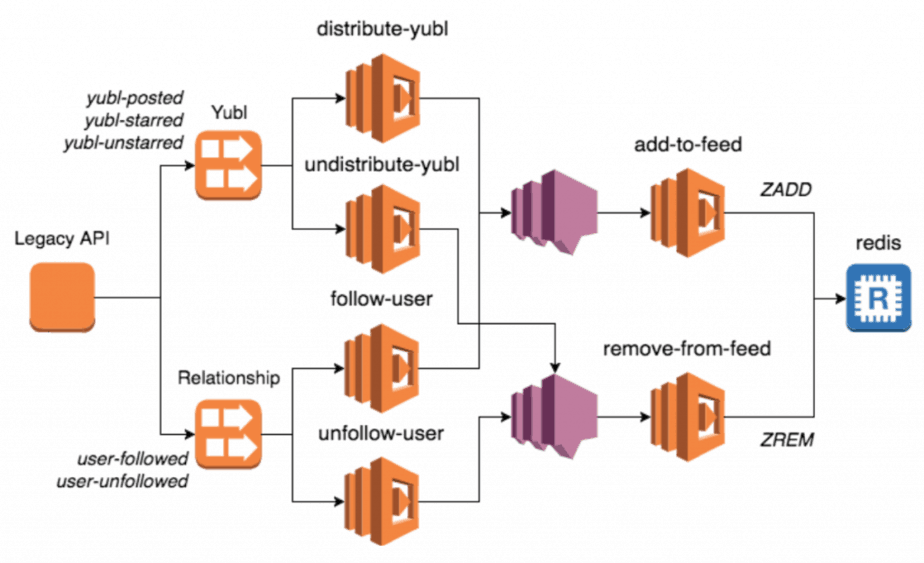
We encapsulated these 2 choices as part of our tooling so that we get the benefit of reusability and the developers can make an explicit choice (and the code makes that choice obvious to anyone reading it later on) for every Kinesis processor they create.
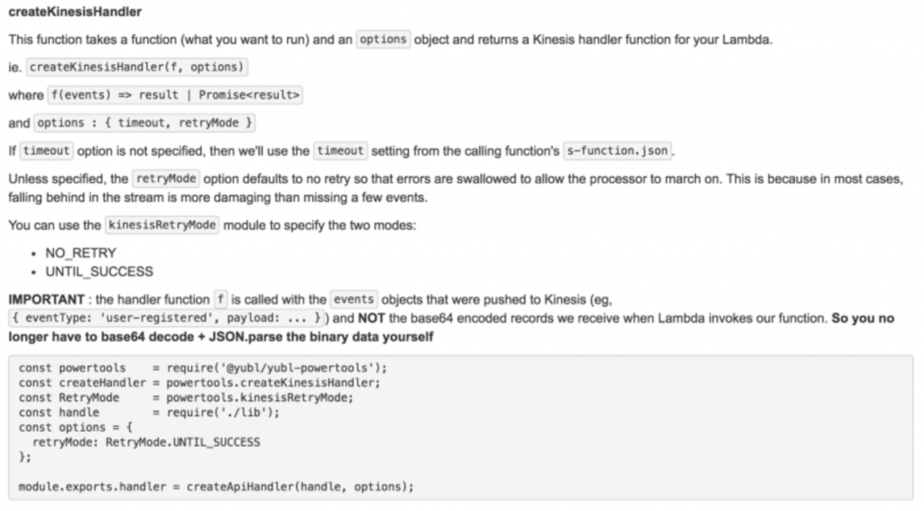
You would probably apply different choices depending on the problem you’re solving, the important thing is to always consider how partial failures would affect your system as a whole.
Use dead letter queues (DLQ)
AWS announced support for Dead Letter Queues (DLQ) at the end of 2016, however, at the time of writing this support only extends to asynchronous invocations (SNS, S3, IOT, etc.) but not poll-based invocations such as Kinesis and DynamoDB streams.
That said, there’s nothing stopping you from applying the DLQ concept yourself.
First, let’s roll back the clock to a time when we didn’t have Lambda. Back then, we’d use long running applications to poll Kinesis streams ourselves. Heck, I even wrote my own producer and consumer libraries because when AWS rolled out Kinesis they totally ignored anyone not running on the JVM!
Lambda has taken over a lot of the responsibilities—polling, tracking where you are in the stream, error handling, etc.—but as we have discussed above it doesn’t remove you from the need to think for yourself. Nor does it change what good looks like for a system that processes Kinesis events, which for me must have at least these 3 qualities:
- it should be real-time (most domains consider real-time as “within a few seconds”)
- it should retry failed events, but retries should not violate the realtime constraint on the system
- it should be possible to retrieve events that could not be processed so someone can investigate root cause or provide manual intervention
Back then, my long running application would:
- poll Kinesis for events
- process the events by passing them to a delegate function (your code)
- failed events are retried 2 additional times
- after the 2 retries are exhausted, they are saved into a SQS queue
- record the last sequence number of the batch so that we don’t lose the current progress if the host VM dies or the application crashes
- another long running application (perhaps on another VM) would poll the SQS queue for events that couldn’t be process realtime
- process the failed events by passing them to the same delegate function as above (your code)
- after the max no. of retrievals the events are passed off to a DLQ
- this triggers CloudWatch alarms and someone can manually retrieve the event from the DLQ to investigate
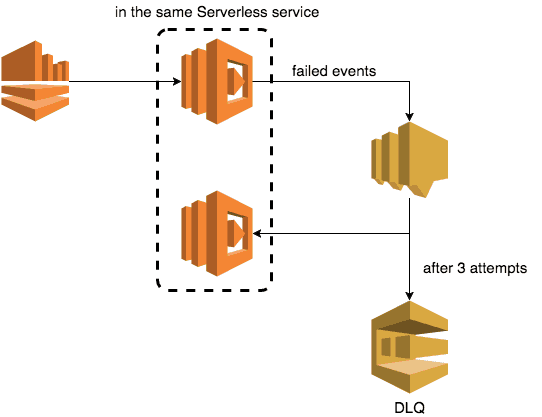
A Lambda function that processes Kinesis events should also:
- retry failed events X times depending on processing time
- send failed events to a DLQ after exhausting X retries
Since SNS already comes with DLQ support, you can simplify your setup by sending the failed events to a SNS topic instead—Lambda would then process it a further 3 times before passing it off to the designated DLQ.
Avoid “hot” streams
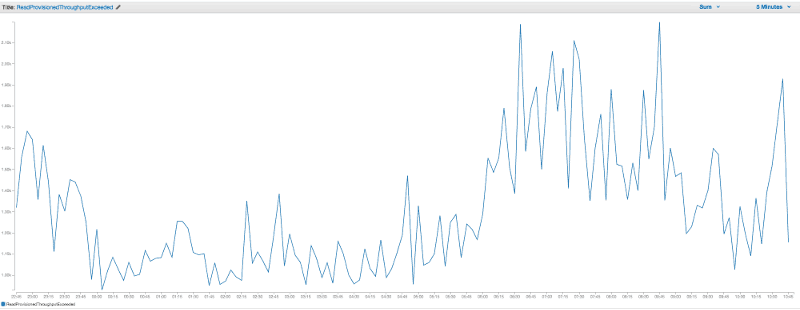
We found that when a Kinesis stream has 5 or more Lambda function subscribers we would start to see lots ReadProvisionedThroughputExceeded errors in CloudWatch. Fortunately these errors are silent to us as they happen to (and are handled by) the Lambda service polling the stream.
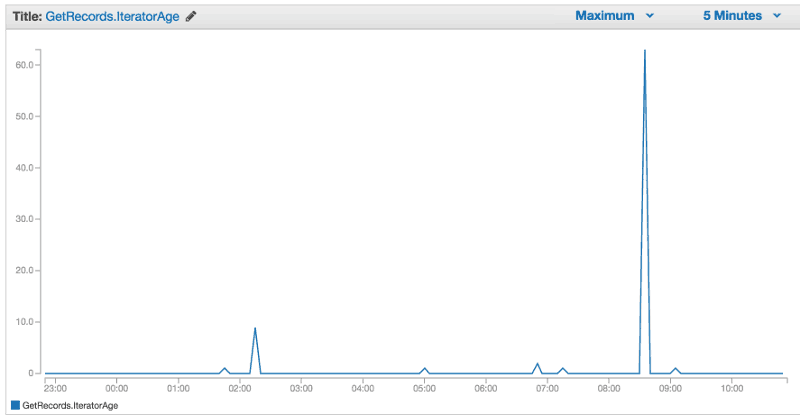
However, we occasionally see spikes in the GetRecords.IteratorAge metric, which tells us that a Lambda function will sometimes lag behind. This did not happen frequently enough to present a problem but the spikes were unpredictable and did not correlate to spikes in traffic or number of incoming Kinesis events.
Increasing the no. of shards in the stream made matters worse and the no. of ReadProvisionedThroughputExceeded increased proportionally.
According to the Kinesis documentation
Each shard can support up to 5 transactions per second for reads, up to a maximum total data reads of 2 MB per second.
and Lambda documentation
If your stream has 100 active shards, there will be 100 Lambda functions running concurrently. Then, each Lambda function processes events on a shard in the order that they arrive.
One would assume that each of the aforementioned Lambda functions would be polling its shard independently. Since the problem is having too many Lambda functions poll the same shard, it makes sense that adding new shards will only escalate the problem further.
“All problems in computer science can be solved by another level of indirection.”
—David Wheeler
After speaking to the AWS support team about this, the only advice we received (and one that we had already considered) was to apply the fan out pattern by adding another layer of Lambda function who would distribute the Kinesis events to others.
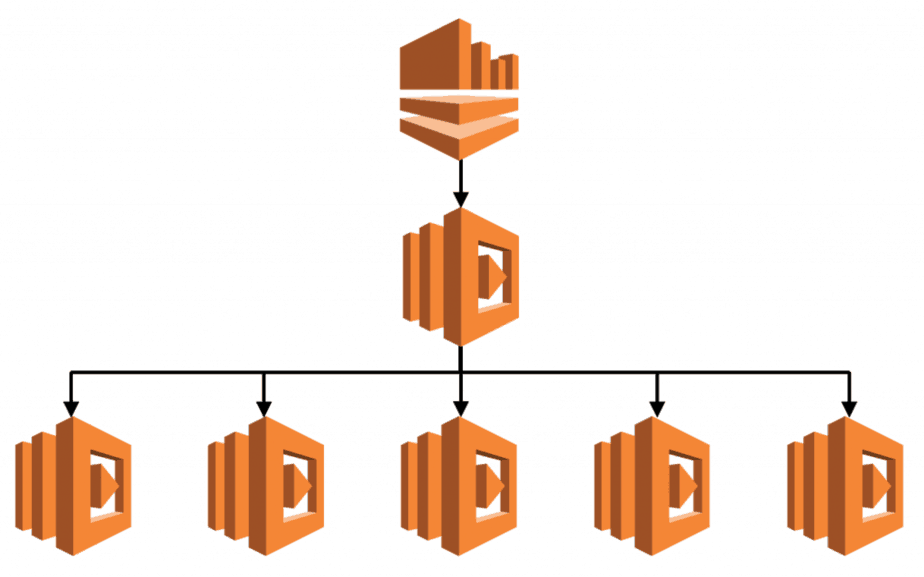
Whilst this is simple to implement, it has some downsides:
- it vastly complicates the logic for handling partial failures (see above)
- all functions now process events at the rate of the slowest function, potentially damaging the realtime-ness of the system
We also considered and discounted several other alternatives, including:
- have one stream per subscriber—this has a significant cost implication, and more importantly it means publishers would need to publish the same event to multiple Kinesis streams in a “transaction” with no easy way to rollback (since you can’t unpublish an event in Kinesis) on partial failures
- roll multiple subscriber logic into one—this corrodes our service boundary as different subsystems are bundled together to artificially reduce the no. of subscribers
In the end, we didn’t find a truly satisfying solution and decided to reconsider if Kinesis was the right choice for our Lambda functions on a case by case basis.
- for subsystems that do not have to be realtime, use S3 as source instead—all our Kinesis events are persisted to S3 via Kinesis Firehose, the resulting S3 files can then be processed by these subsystems, eg. Lambda functions that stream events to Google BigQuery for BI
- for work that are task-based (ie, order is not important), use SNS/SQS as source instead—SNS is natively supported by Lambda, and we implemented a proof-of-concept architecture for processing SQS events with recursive Lambda functions, with elastic scaling; now that SNS has DLQ support (it was not available at the time) it would definitely be the preferred option provided that its degree of parallelism would not flood and overwhelm downstream systems such as databases, etc.
- for everything else, continue to use Kinesis and apply the fan out pattern as an absolute last resort
Wrapping up…
So there you have it, 3 pro tips from a group of developers who have had the pleasure of working extensively with Lambda and Kinesis.
I hope you find this post useful, if you have any interesting observations or learning from your own experience working with Lambda and Kinesis, please share them in the comments section below.
Links
Yubl’s road to serverless — Part 1, Overview
Yubl’s road to serverless — Part 2, Testing and CI/CD
Yubl’s road to serverless — Part 3, Ops
AWS Lambda — use recursive functions to process SQS messages, Part 1
AWS Lambda — use recursive functions to process SQS messages, Part 2
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Great writeup.