
Yan Cui
I help clients go faster for less using serverless technologies.

part 1: overview <- you’re here
part 2: testing and CI/CD
part 3: ops
part 4: building a scalable notification system
part 5: building a better recommendation system
Since Yubl’s closure quite a few people have asked about the serverless architecture we ended up with and some of the things we have learnt along the way.
As such, this is the first of a series of posts where I’d share some of the lessons we learnt. However, bear in mind the pace of change in this particular space so some of the challenges/problems we encountered might have been solved by the time you read this.
ps. many aspects of this series is already covered in a talk I gave on Amazon Lambda at Leetspeak this year, you can find the slides and recording of the talk here.
From A Monolithic Beginning
Back when I joined Yubl in April I inherited a monolithic Node.js backend running on EC2 instances, with MongoLab (hosted MongoDB) and CloudAMQP (hosted RabbitMQ) thrown into the mix.
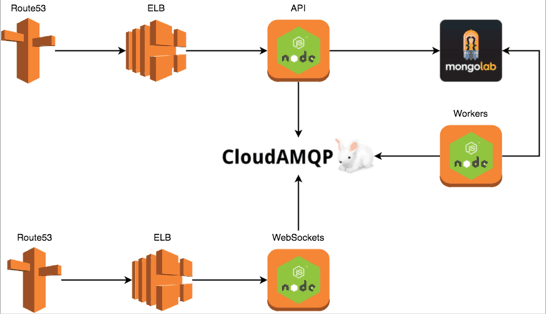
There were numerous problems with the legacy system, some could be rectified with incremental changes (eg. blue-green deployment) but others required a rethink at an architectural level. Although things look really simple on paper (at the architecture diagram level), all the complexities are hidden inside each of these 3 services and boy, there were complexities!
My first tasks were to work with the ops team to improve the existing deployment pipeline and to draw up a list of characteristics we’d want from our architecture:
- able to do small, incremental deployments
- deployments should be fast, and requires no downtime
- no lock-step deployments
- features can be deployed independently
- features are loosely coupled through messages
- minimise cost for unused resources
- minimise ops effort
From here we decided on a service-oriented architecture, and Amazon Lambda seemed the perfect tool for the job given the workloads we had:
- lots of APIs, all HTTPS, no ultra-low latency requirement
- lots of background tasks, many of which has soft-realtime requirement (eg. distributing post to follower’s timeline)
To a Serverless End
It’s suffice to say that we knew the migration was going to be a long road with many challenges along the way, and we wanted to do it incrementally and gradually increase the speed of delivery as we go.
“The lead time to someone saying thank you is the only reputation metric that matters”
– Dan North
The first step of the migration was to make the legacy systems publish state changes in the system (eg. user joined, user A followed user B, etc.) so that we can start building new features on top of the legacy systems.
To do this, we updated the legacy systems to publish events to Kinesis streams.
Our general strategy is:
- build new features on top of these events, which usually have their own data stores (eg. DynamoDB, CloudSearch, S3, BigQuery, etc.) together with background processing pipelines and APIs
- extract existing features/concepts from the legacy system into services that will run side-by-side
- these new services will initially be backed by the same shared MongoLab database
- other services (including the legacy ones) are updated to use hand-crafted API clients to access the encapsulated resources via the new APIs rather than hitting the shared MongoLab database directly
- once all access to these resources are done via the new APIs, data migration (usually to DynamoDB tables) will commence behind the scenes
- wherever possible, requests to existing API endpoints are forwarded to the new APIs so that we don’t have to wait for the iOS and Android apps to be updated (which can take weeks) and can start reaping the benefits earlier
After 6 months of hard work, my team of 6 backend engineers (including myself) have drastically transformed our backend infrastructure. Amazon was very impressed by the work we were doing with Lambda and in the process of writing up a case study of our work when Yubl was shut down at the whim of our major shareholder.
Here’s an almost complete picture of the architecture we ended up with (some details are omitted for brevity and clarity).
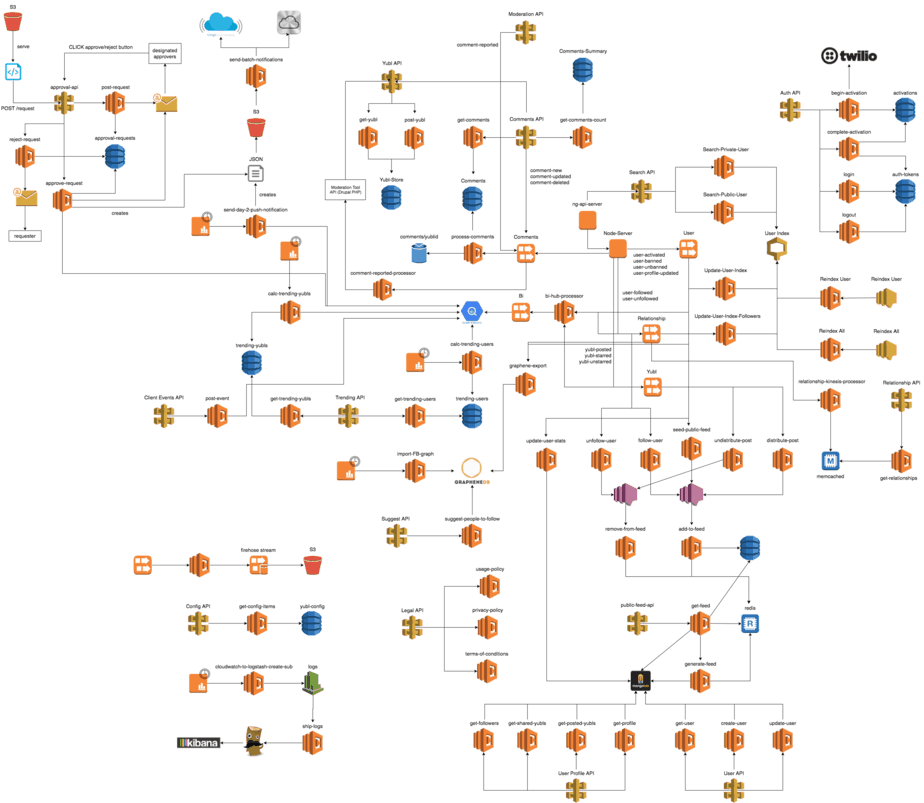
Some interesting stats:
- 170 Lambda functions running in production
- roughly 1GB of total deployment package size (after Janitor Lambda cleans up unreferenced versions)
- Lambda cost was around 5% of what we pay for EC2 for a comparable amount of compute
- the no. of production deployments increased from 9/month in April to 155 in September
For the rest of the series I’ll drill down into specific features, how we utilised various AWS services, and how we tackled the challenges of:
- centralised logging
- centralised configuration management
- distributed tracing with correlation IDs for Lambda functions
- keeping Lambda functions warm to avoid coldstart penalty
- auto-scaling AWS resources that do not scale dynamically
- automatically clean up old Lambda function versions
- securing sensitive data (eg. mongodb connection string, service credentials, etc.)
I can also explain our strategy for testing, and running/debugging functions locally, and so on. If there’s anything you’d like me to cover in particular, please leave a comment and let me know.
Links
- Slides and Recording of my Amazon Lambda talk at Leetspeak
- Janitor-Lambda function to clean up old deployment packages
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
So, when would you say it would be time to drop a regular RESTful back end for a Lamda-style backend? When does it make sense to do what you did? Would it be possible to do something like this with Azure Functions? It seems nice to not have to think about worrying about scaling and a server. But leaving F# for Node just doesn’t seem like a wonderful thing. I’ve done some node.js programming but anytime you hit some complex code without the type system to help out it was really hard for me to refactor and reason about.
I read a comment once that with JavaScript everything becomes a configuration or JSON file. I would have to agree. I created a abstraction on top of Express that auto generated the endpoints. It was nice. But it seemed like a lot of work creating JSON Schema when I could have just had a type system to begin with and the schema wasn’t as nice as having a type system.
http://jnyman.com/2016/06/07/building_convention_based_routes_in_nodejs/
Pingback: F# Weekly #50, 2016 – Sergey Tihon's Blog
Hi, I’m curious about what strategy did you adopted for monitoring your environment? What metrics have you adopted? And what was your main challenges in moving from a PaaS/IaaS perspective to a FaaS, mainly about the tooling?
Hi Lucas,
We used CloudWatch, all the standard metrics you get for Lambda + custom application-level metrics that we emit from our application code. Logs are aggregated and moved into an ELK stack for centralised logging, alerts are set up around emergent properties such as latency (we were missing this but CloudWatch has added percentile metrics, so yay!), error rate, etc. but no CPU/networking metrics since there’re no servers!
The main challenge we had was how to migrate the system bit by bit so that we avoid a big bang migration (reducing risk) and accelerate as we go (get more done, faster). So, a lot of planning, working with the product owners to understand their vision and coordinating with other teams (QA, client devs, PMs). The actual technical challenges were pretty thin, since you’re actually taking load off your shoulders (don’t need to think about VMs, scaling, and how to glue the system together through queues/streams, etc.). There was minimal amount of tooling you need, what we got from the serverless framework was sufficient for everything we needed. There was some initial tinkering to work out how to run/debug functions locally, what branching strategy to use, how to do ci (which we just ended up with simple .sh scripts that can be run from local as well as ci box), approach to testing (we favour integration & acceptance testing over unit testing), etc.
I hope to find time to write more about these, but there’s just too much to catch up on work-wise (and I’m still trying to convince my new co-workers to go big on Lambda, opinions are so far divided, which I see as half-way there as I’m a bottle half full kinda guy ;-))
Pingback: AWS Lambda —3 pro tips for working with Kinesis streams | theburningmonk.com
Pingback: Serverless observability brings new challenges to current practices | theburningmonk.com