
Yan Cui
I help clients go faster for less using serverless technologies.

part 1: overview
part 2: testing and CI/CD
part 3: ops
part 4: building a scalable notification system
part 5: building a better recommendation system <- you’re here
When I joined Yubl in April 2016, it had launched just 2 months earlier, after a long and chaotic development cycle that lasted more than 2 years – all the while there was a fully armed sales team before there was even a product!
Some seriously bad decisions happened at Yubl.. and judging by Silicon Valley this kind of decision making is far more common than we realised.
That said, many good things also happened at Yubl, and I had the pleasure to work with some of the best people I have met in my career. This post is about one of the ailing features we were able to quickly turn around with the power of AWS Lambda and using the right tool for the job.
https://giphy.com/gifs/xUOrw9bQdkC1Du4Pp6
Fans of Silicon Valley probably remember that scene from Season 3 when Richard and co walked into their shiny new Pipe Piper office to find “Action” Jack Barker had hired an army of sales people before they even had a product.
A Broken Feature
Upon joining the company, I found out the app already had a Find People feature although it didn’t do what I expected. The likes of Twitter and Facebook would employ sophisticated algorithms to find people with shared interest to you. Our feature on the other hand would return the first 30 users in MongoDB that you aren’t already following, by the order of account creation time. For most users this list would equate to the first 30 Yubl employees that installed the app… talk about rigging the game!
One of the devs made a valiant attempt to improve the feature by returning only users who have shared connections with you – either you both follow X or you are both followed by X.
However, the implementation was a series of expensive (and complicated) MongoDB queries per user request. Ultimately it was an approach that would not scale with throughput nor complexity as it’s using the wrong tool for the job.
Lambda + GrapheneDB = Efficient Graph Queries
I had previously worked with Neo4j at Gamesys and used it to analyze and model the complex in-game economy of a MMORPG.
A graph database like Neo4j is the perfect place to store our social graph, and allows us to efficiently perform the kind of graph queries we need in order to find users you should follow, eg. 2nd/3rd degree connections.
GrapheneDB offers hosted Neo4j database as a service, with built-in monitoring, dashboards, automated backup and scaling up. It was the perfect choice to get us going and start delivering value to our users quickly.
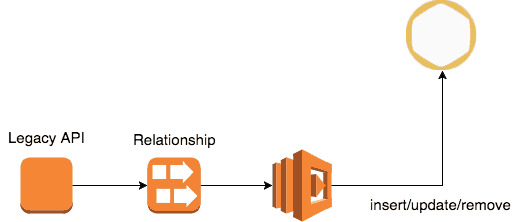
At this point in time we were already streaming all state changes in the system into Kinesis. To export all of our social graph into GrapheneDB and to keep it in sync with MongoDB we:
- ran a one-off task to export all the relationship data into GrapheneDB
- subscribed a Lambda function to the
RelationshipKinesis stream to process any subsequent relationship changes and update the social graph (in GrapheneDB) in real time
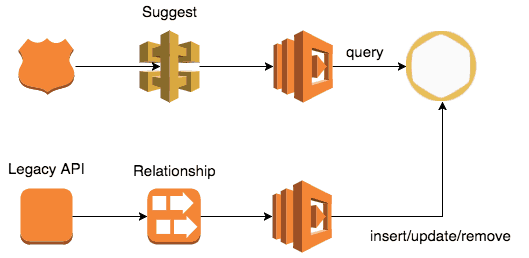
We then exposed the data via API Gateway and Lambda so that the client app and other internal services can use it to easily find suggested users for a user to follow.
Future Plans
Given the limitation that Neo4j requires all of your graph to be stored on one machine (and it has pretty taxing hardware requirement too) it was not the long term solution for us.
Based on my estimates, the biggest instance available on GrapheneDB would suffice until we have more than 10M users. It was calculated based on the average no. of connections per user in our platform and using Twitter’s user stats as a guideline for where we might be at 10M users.
We can push that ceiling much further by moving to a batch model and preprocess recommendations for each user to reduce the no. of live queries against a large graph. The recommendations can be restricted to active (eg. users that have logged in in the last X days) users only, and only when:
- the recommendations are stale, ie. not acted upon by the user for more than X days so they might not be what the user wants; or
- when the user’s extended social graph has changed, ie. followers/followees have new connections
From what I was able to gather, all the big social networks use a batch model for scalability and cost reasons.
As for a long term solutions, we hadn’t settled on anything. I looked at Facebook’s Giraph briefly but it’s far more sophisticated than we were ready for. There are other “fantasy” ideas like the Mosaic system described in this paper. It would have been a fantastic challenge had we got that far.
Finding Trending Users
Because we were still a small social network – with just over 800K installs, it’s not sufficient to make recommendations based on a user’s social graph alone as most users have a pretty small social graph.
To bridge the gap we decided to also include trending users on the platform in your recommendations.
Thankfully, all of our events (eg. X followed Y, X liked Y’s post, etc.) are streamed into Google BigQuery. We chose BigQuery because AWS Athena hadn’t been announced yet and RedShift is not the right model for making ad-hoc, live queries that need to respond quickly. Also, I had many years of experience using BigQuery at Gamesys so it was a no-brainer at the time.
ps. if you’re curious about the difference between Athena and BigQuery, Lynn Langit gave a comprehensive comparison at Serverless Austin this year.
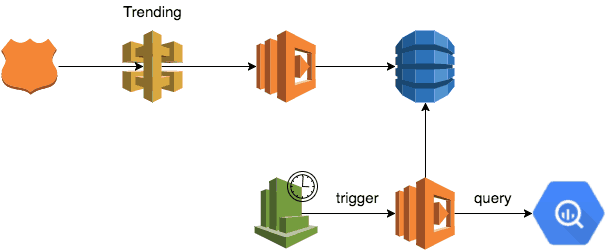
To find trending users, we worked with the product team to create a formula to calculate a user’s “trendiness” based on no. of new followers in the last 24 hours. The follower count is weighted exponentially by how recently the user was followed. For instance, a follower that followed you in the past hour gives you a score of 1, but a follower that followed you 3 hours ago would only earn you a score of 0.1.
We created a cron job with CloudWatch Events and Lambda to perform the aforementioned query against BigQuery every 3 hours. To save on cost, our query would only process events that were inserted in the last 24 hours.
The result are then saved into a DynamoDB table, which is overwritten at the end of each run.
Once again, we exposed the data via API Gateway and Lambda.
Migration to new APIs
Now, we have 2 new APIs to provide live suggestions based on a user’s social graph, and to find users who are currently trending on our platform.
However, the client apps would need to be updated to take advantage of these new APIs. Instead of waiting for the client teams to catch up, we updated the legacy API’s suggestion endpoint to use results from both so we can provide value to our users earlier.
“The lead time to someone saying thank you is the only reputation metric that matters.”
– Dan North
This is how it looks when we put everything together:
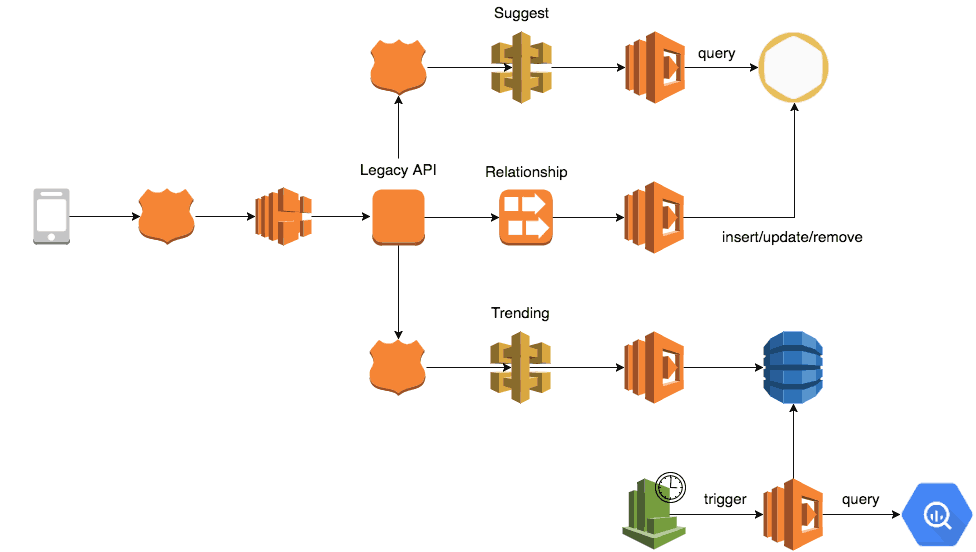
One of the most satisfying aspect of this work was how quickly we were able to turn this feature around and deploy the new system into production. Everything came together in less than 2 weeks, which is largely because we were able to focus on our business needs and let services such as Lambda, BigQuery and GrapheneDB deal with the undifferentiated efforts.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.