
Yan Cui
I help clients go faster for less using serverless technologies.

The Saga pattern is a pattern for managing failures, where each action has a compensating action for rollback.
In Hector Garcia-Molina’s 1987 paper, it is described as an approach to handling system failures in a long-running transactions.
It has become increasingly relevant in the world of microservices as application logic often needs to transact across multiple bounded contexts – each encapsulated by its own microservice with independent databases. Caitie McCaffrey gave a good talk on using the Saga pattern in distributed systems, which you can watch here.
Using Caitie’s example from her talk, suppose we have a transaction that goes something like this:
Begin transaction
Start book hotel request
End book hotel request
Start book flight request
End book flight request
Start book car rental request
End book car rental request
End transaction
We can model each of the actions (and their compensating actions) with a Lambda function, and use a state machine in Step Function as the coordinator for the saga.
Because the compensating actions can also fail so we need to be able to retry them until success, which means they have to be idempotent.
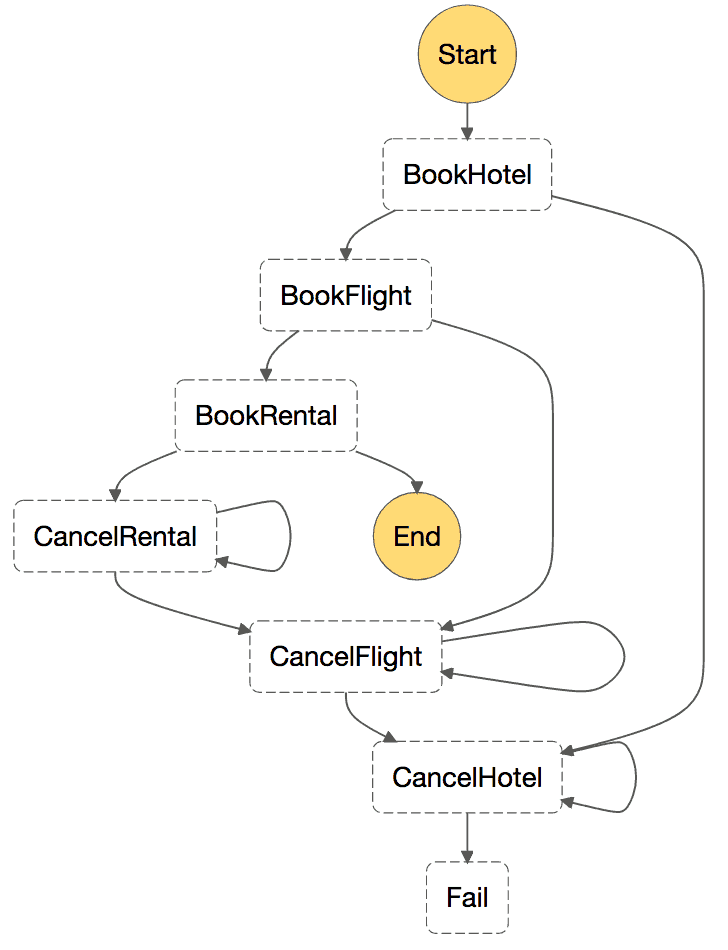
In the example below, we’ll implement backward recovery in the event of a failure.
Each Lambda function expects the input to be in the following shape.
{
"trip_id": "5c12d94a-ee6a-40d9-889b-1d49142248b7",
"depart": "London",
"depart_at": "2017-07-10T06:00:00.000Z",
"arrive": "Dublin",
"arrive_at": "2017-07-12T08:00:00.000Z",
"hotel": "holiday inn",
"check_in": "2017-07-10T12:00:00.000Z",
"check_out": "2017-07-12T14:00:00.000Z",
"rental": "Volvo",
"rental_from": "2017-07-10T00:00:00.000Z",
"rental_to": "2017-07-12T00:00:00.000Z"
}
Inside each of the functions is a simple PutItem request against a different DynamoDB table. The corresponding compensating function will perform a DeleteItem against the corresponding table to rollback the PutItem action.
The state machine pass the same input to each action in turn:
- BookHotel
- BookFlight
- BookRental
and record their results at a specific path (so to avoid overriding the input $ that will be passed to the next function).
In this naive implementation, we’ll apply the compensating action for any failure – hence the State.ALL below. In practice, you should consider giving certain error types a retry – eg. temporal errors such as DynamoDB’s provision throughput exceeded exceptions.
{
"Comment": "Applying the Saga pattern with AWS Lambda and Step Functions",
"StartAt": "BookHotel",
"States": {
"BookHotel": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{AccountID}:function:lambda-saga-dev-book-hotel",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"ResultPath": "$.BookHotelError",
"Next": "CancelHotel"
}
],
"ResultPath": "$.BookHotelResult",
"Next":"BookFlight"
},
"BookFlight": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{AccountID}:function:lambda-saga-dev-book-flight",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"ResultPath": "$.BookFlightError",
"Next": "CancelFlight"
}
],
"ResultPath": "$.BookFlightResult",
"Next":"BookRental"
},
"BookRental": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{AccountID}:function:lambda-saga-dev-book-rental",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"ResultPath": "$.BookRentalError",
"Next": "CancelRental"
}
],
"ResultPath": "$.BookRentalResult",
"End": true
},
"CancelHotel": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{AccountID}:function:lambda-saga-dev-cancel-hotel",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"ResultPath": "$.CancelHotelError",
"Next": "CancelHotel"
}
],
"ResultPath": "$.CancelHotelResult",
"Next":"Fail"
},
"CancelFlight": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{AccountID}:function:lambda-saga-dev-cancel-flight",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"ResultPath": "$.CancelFlightError",
"Next": "CancelFlight"
}
],
"ResultPath": "$.CancelFlightResult",
"Next":"CancelHotel"
},
"CancelRental": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{AccountID}:function:lambda-saga-dev-cancel-rental",
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"ResultPath": "$.CancelRentalError",
"Next": "CancelRental"
}
],
"ResultPath": "$.CancelRentalResult",
"Next":"CancelFlight"
},
"Fail": {
"Type": "Fail"
}
}
}

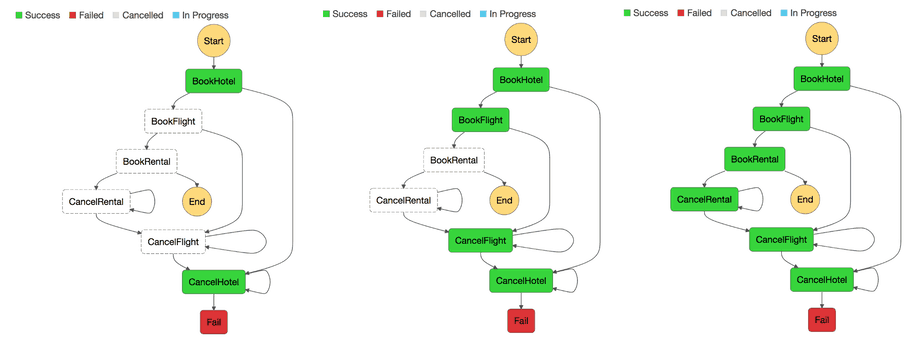
Success Case
Following the happy path, each of the actions are performed in turn and the state machine will end successfully.

Failure Cases
When failures strike, depending on where the failure occurs we need to apply the corresponding compensating actions in turn.
In the examples below, if the failure happened at BookFlight, then both CancelFlight and CancelHotel will be executed to rollback any changes performed thus far.
Similar, if the failure happened at BookRental, then all three compensating actions – CancelRental, CancelFlight and CancelHotel – will be executed in that order to rollback all the state changes from the transaction.
Each compensating action also have an infinite retry loop! In practice, there should be a reasonable upper limit on the no. of retries before you alert for human intervention.
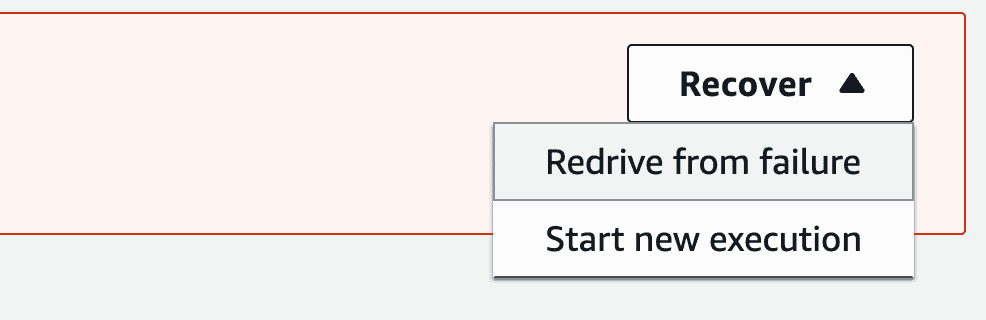
With Step Functions’ new “Redrive from failure” [3] capability, the human operator can investigate the persistent failure to roll back the transaction and continue the rollback process manually.
You can find the source code for this demo here [4].
Links
[1] ?Hector Garcia-Molina’s 1987 paper?
[2] ?Applying the Saga pattern?
[3] ?Step Functions can now recover from failures more easily?
[4] ?Github source code for the demo project?
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Theoretically that is really nice, but in practice it causes a number of different issues. It also fails to sufficiently deal with the problem mentioned in the linked paper:
However, unlike other transactions, the transactions m a saga are related to each other and should be executed as a (non-atomic) unit any partial executions of the saga are undesirable, and if they occur, must be compensated for
The following problems occur:
* Complex state management having to understand and organize all the possible states. What if we wanted to add two flight reservations or at the point of placing the car rental change the dates for the flight. Using a flow diagram is suboptimal.
* Tasks for (Success, Rollback) for each type of transaction are separated, which mean in practice duplicating the management of the resources available or managed in the Happy Path.
* Scaling in next to impossible to do the fixed flow. Take adding the ability to cancel an already successful path. What if the original step function didn’t include flight logic. Now you’ll have to handle that.
* Repeatable idempotent transactions, while it is true that all the individual transactions look successful, it is impossible to know if the whole chain was successful without re-executing the flow. This causes consistency issues, for instance let’s say you have 2 tasks to perform:
1. Order Widget
2. Send Email to Customer
What happens if email sending succeeds but the state machine traversal fails. That means you’ll think the process was unsuccessful, but really both the order and the email worked. That’s because there is a third hidden 3. Set state to success.
What works better is a decentralized parallel transactions that self contain the successful and failure paths
* API => Task Manager
* Task Manager => FlightManager.Reserve Flight => onFailure => Cancel Filght
* Task Manager => HotelManager.Reserve Hotel => onFailure => Cancel Hotel
* Task Manager => CarManager.Reserve Car => onFailure => Cancel Car
* Done
Rather than the forced synchronous approach, this also provides a successful async approach. At any point you can observe the current state of the system via
* API => Get State
* Get State => FlightManager.GetState, HotelManager.GetState, CarManager.GetState
and jump any where into the process when you want to:
* API => Cancel Flight => FlightManager.CancelFlight
Without worrying about the other parts of the flow. Since everything is self contained, you never to ask the question, hmmm, I’ve handled the Flight in the FlightManager, does the FlightManager need to do something else. The answer is you are always good because each Manager was designed to handle the full state machine with idempotency of its own resources.