
Yan Cui
I help clients go faster for less using serverless technologies.

part 1: overview
part 2: testing and CI/CD
part 3: ops
part 4: building a scalable notification system <- you’re here
part 5: building a better recommendation system
Just before Yubl’s untimely demise we did an interesting piece of work to redesign the system for sending targeted push notifications to our users to improve retention.
The old system relied on MixPanel for both selecting users as well as sending out the push notifications. Whilst MixPanel was great for getting us basic analytics quickly, we soon found our use cases outgrew MixPanel. The most pressing limitation was that we were not able to query users based on their social graph to create target push notifications – eg. notify an influencer’s followers when he/she publishes a new post or runs a new social media campaign.
Since all of our analytics events are streamed to Google BigQuery (using a combination of Kinesis Firehose, S3 and Lambda) we have all the data we need to support the complex use cases the product team has.
What we needed, was a push notification system that can integrate with BigQuery results and is capable of sending millions of push notifications in a batch.
Design Goals
From a high level, we need to support 2 types of notifications.
Ad-hoc notifications are driven by the marketing team, working closely with influencers and the BI team to match users with influencers or contents that they might be interested in. Example notifications include:
- users who follow Accessorize and other fashion brands might be interested to know when another notable fashion brand joins the platform
- users who follow an influencer might be interested to know when the influencer publishes a new post or is running a social media campaign (usually with give-away prizes, etc.)
- users who have shared/liked music related contents might be interested to know that Tinie Tempah has joined the platform
Scheduled notifications are driven by the product team, these notifications are designed to nudge users to finish the sign up process or to come back to the platform after they have lapsed. Example notifications include:
- day-1 unfinished sign up : notify users who didn’t finish the sign up process to come back to complete the process
- day-2 engagement : notify users to come back and follow more people or invite friends on day 2
- day-21 inactive : notify users who have not logged into the app for 21 days to come back and check out what’s new
A/B testing
For the scheduled notifications, we want to test out different messages/layouts to optimise their effectiveness over time. To do that, we wanted to support A/B testing as part of the new system (which MixPanel already supports).
We should be able to create multiple variants (each with a percentage), along with a control group who will not receive any push notifications.

Oversight vs Frictionless
For the ad-hoc notifications, we don’t want to get in the way of the marketing team doing their job, so the process for creating ad-hoc push notifications should be as frictionless as possible. However, we also don’t want the marketing team to operate completely without oversight and run the risk of long term damage by spamming users with unwanted push notifications (which might cause users to disable notifications or even rage quit the app).
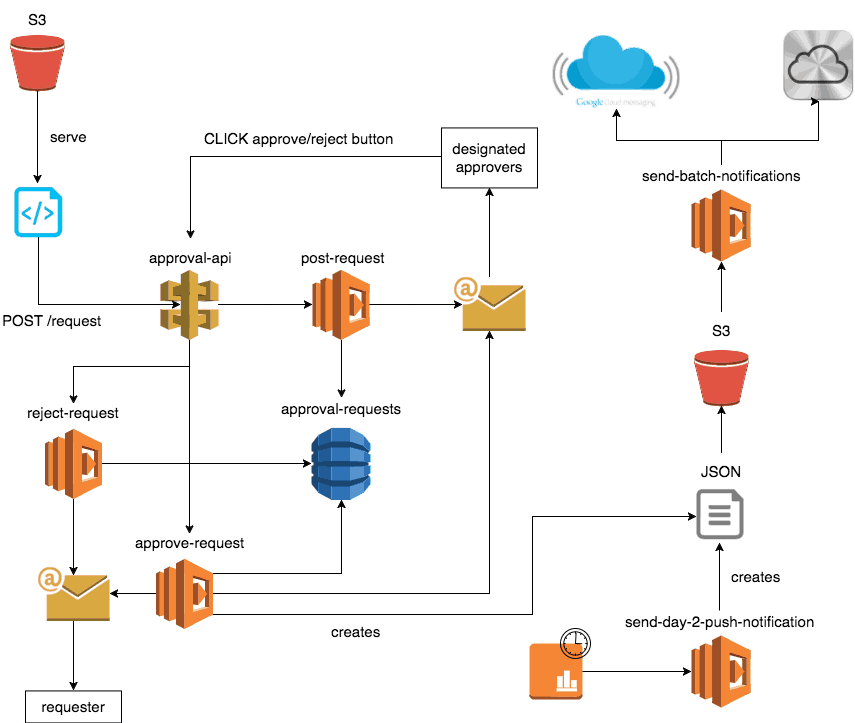
The compromise we reached was an automated approval process whereby:
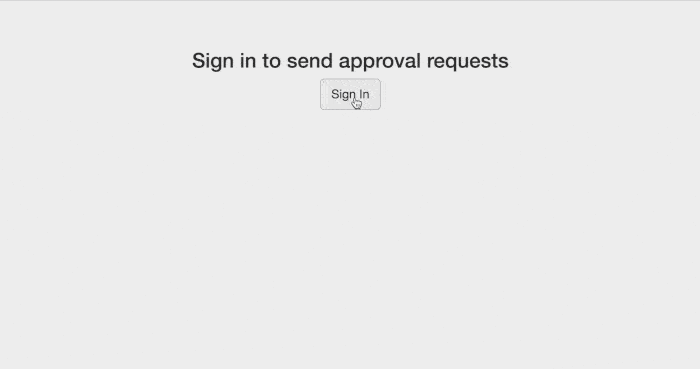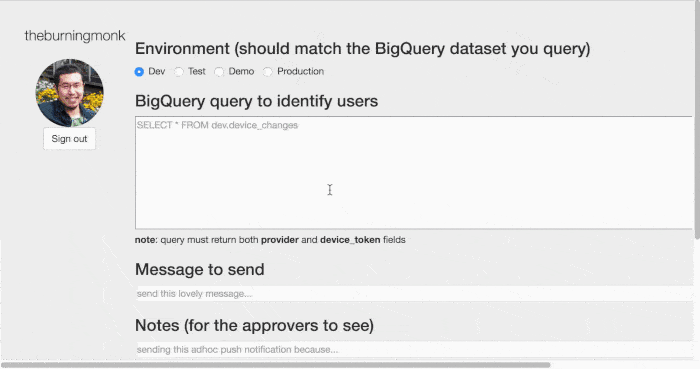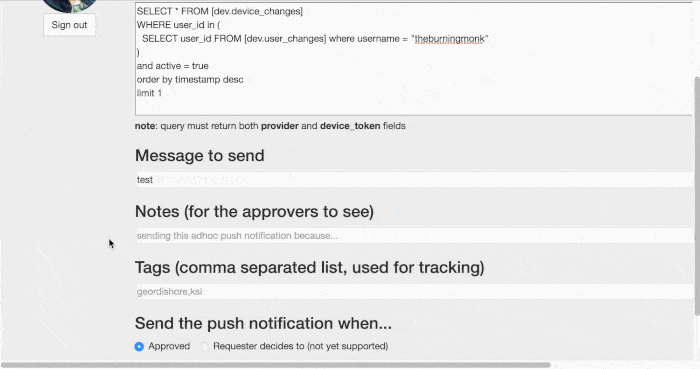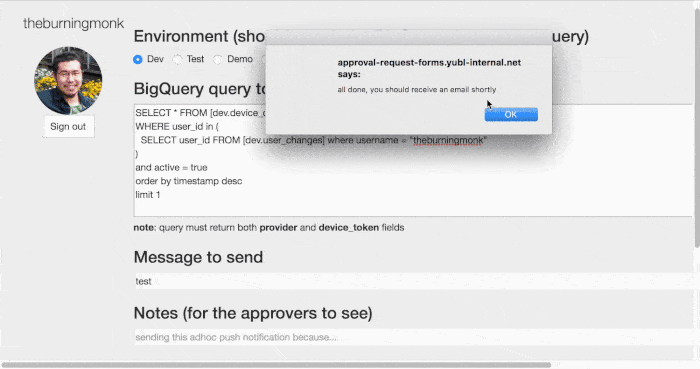
- the marketing team will work with BI on a query to identify users (eg. followers of Tinie Tempah)
- fill in a request form, which informs designated approvers via email
- approvers can send themselves a test push notification to see how it will be formatted on both Android and iOS
- approvers can approve or reject the request
- once approved, the request will be executed

Implementation
We decided to use S3 as the source for a send-batch-notifications function because it allows us to pass large list of users (remember, the goal is to support sending push notifications to millions of users in a batch) without having to worry about pagination or limits on payload size.
The function will work with any JSON file in the right format, and that JSON file can be generated in many ways:
- by the cron jobs that generate scheduled notifications
- by the approval system after an ad-hoc push notification is approved
- by the approval system to send a test push notification to the approvers (to visually inspect how the message will appear on both Android and iOS devices)
- by members of the engineering team when manual interventions are required
We also considered moving to SNS but decided against it in the end because it doesn’t provide useful enough an abstraction to justify the effort to migrate (involves client work) and the additional cost for sending push notifications. Instead, we used node-gcm and apn to communicate with GCM and APN directly.
Recursive Functions FTW
Lambda has a hard limit of 5 mins execution time (it might be softened in the near future), and that might not be enough time to send millions of push notifications.
Our approach to long-running tasks like this is to run the Lambda function as a recursive function.
A naive recursive function would process the payload in fixed size batches and recurse at the end of each batch whilst passing along a token/position to allow the next invocation to continue from where it left off. In this particular case, we have additional considerations because the total number of work items can be very large:
- minimising the no. of recursions required, which equates to no. of Invoke requests to Lambda and carries a cost implication at scale
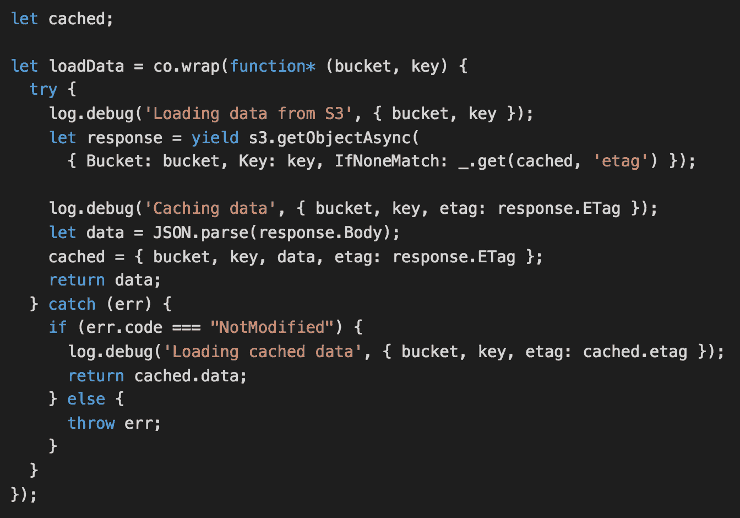
- caching the content of the JSON file to improve performance (by avoiding loading and parsing a large JSON file more than once) and reduce S3 cost
To minimise the no. of recursions, our function would:
- process the list of users in small batches of 500
- at the end of each batch, call
context.getRemainingTimeInMillis()to check how much time is left in this invocation - if there is more than 1 min left in the invocation then process another batch; otherwise recurse
When caching the content of the JSON file from S3, we also need to compare the ETAG to ensure that the content of the file hasn’t changed.
With this set up the system was able to easily handle JSON files with more than 1 million users during our load test (sorry Apple and Google for sending all those fake device tokens :-P).
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.