
Yan Cui
I help clients go faster for less using serverless technologies.

part 1: overview
part 2: testing and CI/CD <- you’re here
part 3: ops
part 4: building a scalable notification system
part 5: building a better recommendation system
Having spoken to quite a few people about using AWS Lambda in production, testing and CI/CD are always high up the list of questions, so I’d like to use this post to discuss the approaches that we took at Yubl.
Please keep in mind that this is a recollection of what we did, and why we chose to do things that way. I have heard others advocate very different approaches, and I’m sure they too have their reasons and their approaches no doubt work well for them. I hope to give you as much context (or, the “why”) as I can so you can judge whether or not our approach would likely work for you, and feel free to ask questions in the comments section.
Testing
In Growing Object-Oriented Software, Guided by Tests, Nat Pryce and Steve Freeman talked about the 3 levels of testing [Chapter 1]:
- Acceptance – does the whole system work?
- Integration – does our code work against code we can’t change?
- Unit – do our objects do the right thing, are they easy to work with?
As you move up the level (acceptance -> unit) the speed of the feedback loop becomes faster, but you also have less confidence that your system will work correctly when deployed.
Favour Acceptance and Integration Tests
With the FAAS paradigm, there are more “code we can’t change” than ever (AWS even describes Lambda as the “glue for your cloud infrastructure”) so the value of integration and acceptance tests are also higher than ever. Also, as the “code we can’t change” are easily accessible as service, it also makes these tests far easier to orchestrate and write than before.
The functions we tend to write were fairly simple and didn’t have complicated logic (most of the time), but there were a lot of them, and they were loosely connected through messaging systems (Kinesis, SNS, etc.) and APIs. The ROI for acceptance and integration tests are therefore far greater than unit tests.
It’s for these reason that we decided (early on in our journey) to focus our efforts on writing acceptance and integration tests, and only write unit tests where the internal workings of a Lambda function is sufficiently complex.
No Mocks
In Growing Object-Oriented Software, Guided by Tests, Nat Pryce and Steve Freeman also talked about why you shouldn’t mock types that you can’t change [Chapter 8], because…
…We find that tests that mock external libraries often need to be complex to get the code into the right state for the functionality we need to exercise.
The mess in such tests is telling us that the design isn’t right but, instead of fixing the problem by improving the code, we have to carry the extra complexity in both code and test…
…The second risk is that we have to be sure that the behaviour we stub or mock matches what the external library will actually do…
Even if we get it right once, we have to make sure that the tests remain valid when we upgrade the libraries…
I believe the same principles apply here, and that you shouldn’t mock services that you can’t change.
Integration Tests
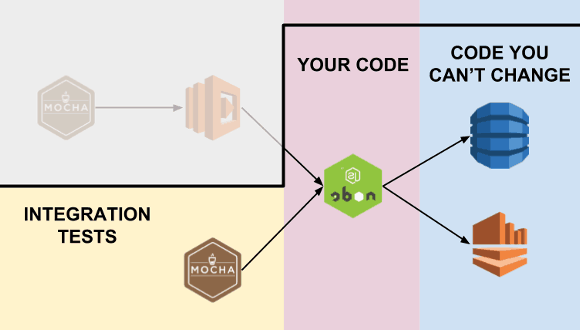
A Lambda function is ultimately a piece of code that AWS invokes on your behalf when some input event occurs. To test that it integrates correctly with downstream systems you can invoke the function from your chosen test framework (we used Mocha).
Since the purpose is to test the integration points, so it’s important to configure the function to use the same downstream systems as the real, deployed code. If your function needs to read from/write to a DynamoDB table then your integration test should be using the real table as opposed to something like dynamodb-local.
It does mean that your tests can leave artefacts in your integration environment and can cause problems when running multiple tests in parallel (eg. the artefacts from one test affect results of other tests). Which is why, as a rule-of-thumb, I advocate:
- avoid hard-coded IDs, they often cause unintentional coupling between tests
- always clean up artefacts at the end of each test
The same applies to acceptance tests.
Acceptance Tests
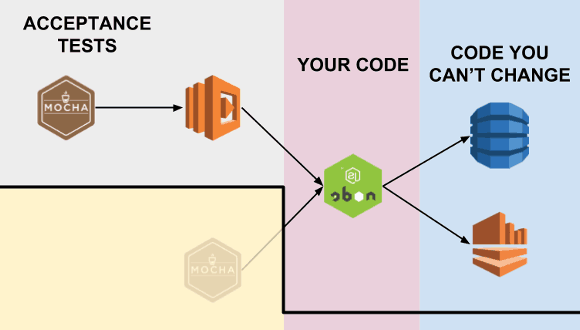
(this picture is slightly misleading in that the Mocha tests are not invoking the Lambda function programmatically, but rather invoking it indirectly via whatever input event the Lambda function is configured with – API Gateway, SNS, Kinesis, etc. More on this later.)
…Wherever possible, an acceptance test should exercise the system end-to-end without directly calling its internal code.
An end-to-end test interacts with the system only from the outside: through its interface…
…We prefer to have the end-to-end tests exercise both the system and the process by which it’s built and deployed…
This sounds like a lot of effort (it is), but has to be done anyway repeatedly during the software’s lifetime…
– Growing Object-Oriented Software, Guided by Tests [Chapter 1]
Once the integration tests complete successfully, we have good confidence that our code will work correctly when it’s deployed. The code is deployed, and the acceptance tests are run against the deployed system end-to-end.
Take our Search API for instance, one of the acceptance criteria is “when a new user joins, he should be searchable by first name/last name/username”.
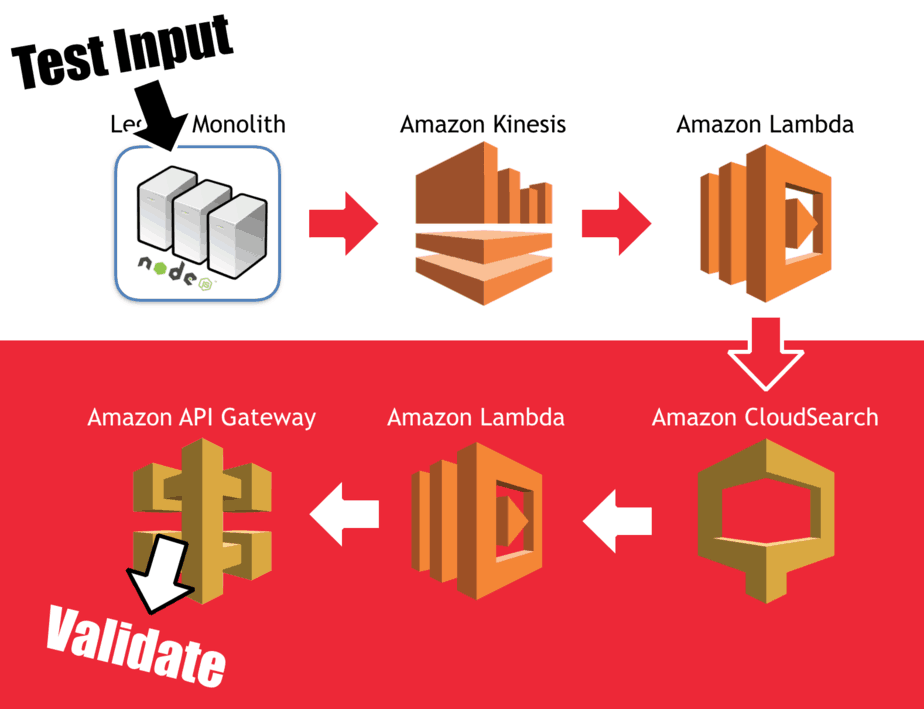
The acceptance test first sets up the test condition – a new user joins – by interacting with the system from the outside and calling the legacy API like the client app would. From here, a new-user-joined event will be fired into Kinesis; a Lambda function would process the event and add a new document in the User index in CloudSearch; the test would validate that the user is searchable via the Search API.
Avoid Brittle Tests
Because a new user is added to CloudSearch asynchronously via a background process, it introduces eventual consistency to the system. This is a common challenge when you decouple features through events/messages. When testing these eventually consistent systems, you should avoid waiting fixed time periods (see protip 5 below) as it makes your tests brittle.

In the “new user joins” test case, this means you shouldn’t write tests that:
- create new user
- wait 3 seconds
- validate user is searchable
and instead, write something along the lines of:
- create new user
- validate user is searchable with retries
- if expectation fails, then wait X seconds before retrying
- repeat
- allow Y retries before failing the test case
Sharing test cases for Integration and Acceptance Testing
We also found that, most of the time the only difference between our integration and acceptance tests is how our function code is invoked. Instead of duplicating a lot of code and effort, we used a simple technique to allow us to share the test cases.
Suppose you have a test case such as the one below.
The interesting bit is on line 22:
let res = yield when.we_invoke_get_all_keys(region);
In the when module, the function we_invoke_get_all_keys will either
- invoke the function code directly with a stubbed context object, or
- perform a HTTP GET request against the deployed API
depending on the value of process.env.TEST_MODE, which is an environment variable that is passed into the test via package.json (see below) or the bash script we use for deployment (more on this shortly).
Continuous Integration + Continuous Delivery
Whilst we had around 170 Lambda functions running production, many of them work together to provide different features to the app. Our approach was to group these functions such that:
- functions that form the endpoints of an API are grouped in a project
- background processing functions for a feature are grouped in a project
- each project has its own repo
- functions in a project are tested and deployed together
The rationale for this grouping strategy is to:
- achieve high cohesion for related functions
- improve code sharing where it makes sense (endpoints of an API are likely to share some logic since they operate within the same domain)
Although functions are grouped into projects, they can still be deployed individually. We chose to deploy them as a unit because:
- it’s simple, and all related functions (in a project) have the same version no.
- it’s difficult to detect if a change to shared code will impact which functions
- deployment is fast, it makes little difference speed-wise whether we’re deploy one function or five functions
For example, in the Yubl app, you have a feed of posts from people you follow (similar to your Twitter timeline).
To implement this feature there was an API (with multiple endpoints) as well as a bunch of background processing functions (connected to Kinesis streams and SNS topics).
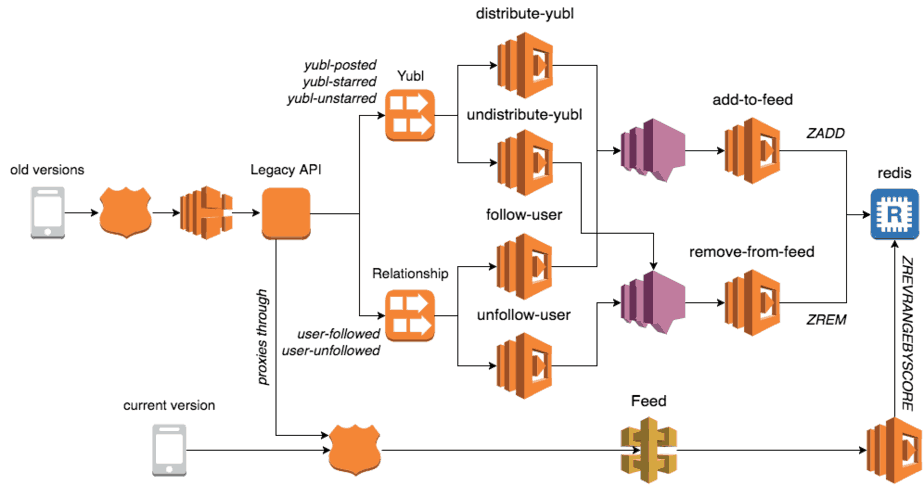
The API has two endpoints, but they also share a common custom auth function, which is included as part of this project (and deployed together with the get and get-yubl functions).
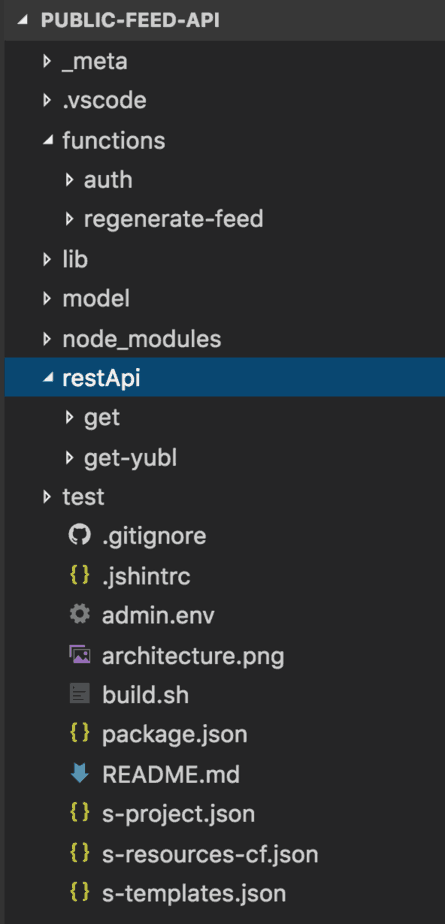
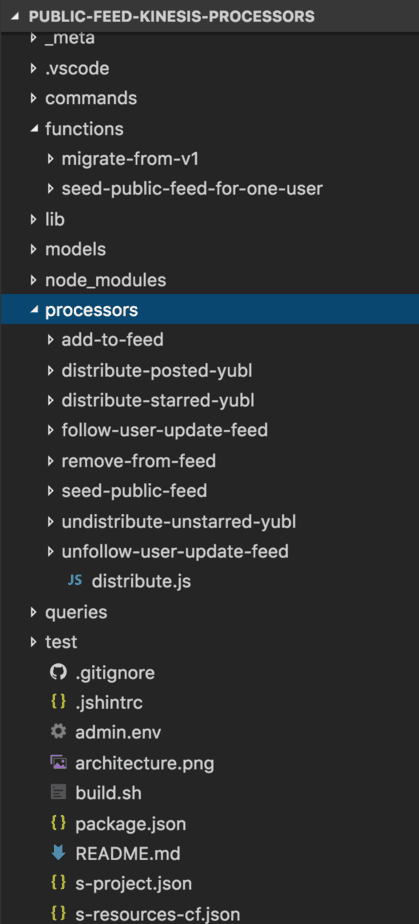
The background processing (initially only Kinesis but later expanded to include SNS as well, though the repo wasn’t renamed) functions have many shared code, such as the distribute module you see below, as well as a number of modules in the lib folder.
All of these functions are deployed together as a unit.
Deployment Automation
We used the Serverless framework to do all of our deployments, and it took care of packaging, uploading and versioning our Lambda functions and APIs. It’s super useful and took care of most of the problem for us, but we still needed a thin layer around it to allow AWS profile to be passed in and to include testing as part of the deployment process.
We could have scripted these steps on the CI server, but I have been burnt a few times by magic scripts that only exist on the CI server (and not in source control). To that end, every project has a simple build.sh script (like the one below) which gives you a common vocabulary to:
- run unit/integration/acceptance tests
- deploy your code
Our Jenkins build configs do very little and just invoke this script with different params.
Continuous Delivery
To this day I’m still confused by Continuous “Delivery” vs Continuous “Deployment”. There seems to be several interpretations, but this is the one that I have heard the most often:
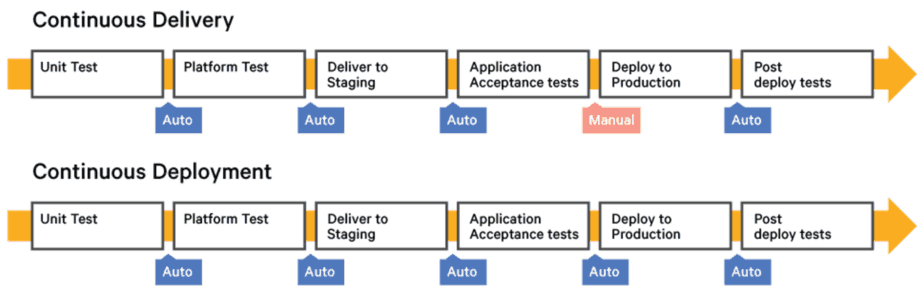
Regardless of which definition is correct, what was most important to us was the ability to deploy our changes to production quickly and frequently.
Whilst there were no technical reasons why we couldn’t deploy to production automatically, we didn’t do that because:
- it gives QA team opportunity to do thorough tests using actual client apps
- it gives the management team a sense of control over what is being released and when (I’m not saying if this is a good or bad thing, but merely what we wanted)
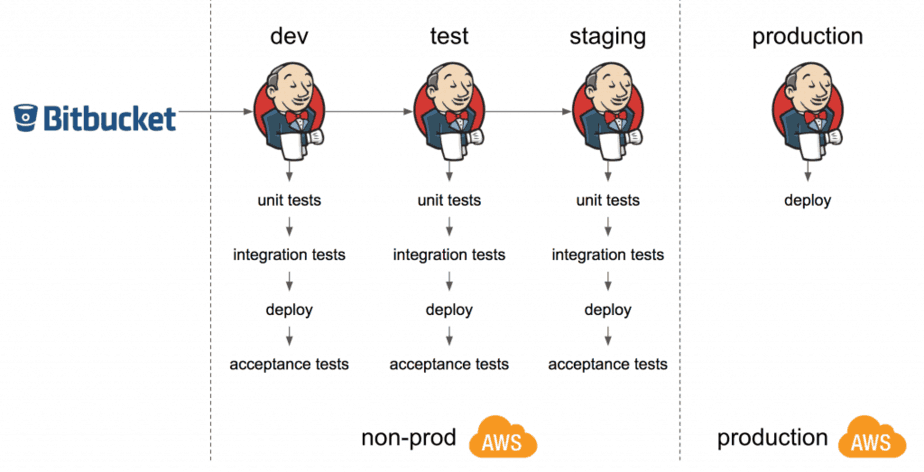
In our setup, there were two AWS accounts:
- production
- non-prod, which has 4 environments – dev, test, staging, demo
(dev for development, test for QA team, staging is a production-like, and demo for private beta builds for investors, etc.)
In most cases, when a change is pushed to Bitbucket, all the Lambda functions in that project are automatically tested, deployed and promoted all the way through to the staging environment. The deployment to production is a manual process that can happen at our convenience and we generally avoid deploying to production on Friday afternoon (for obvious reasons ![]() ).
).
Conclusions
The approaches we have talked about worked pretty well for our team, but it was not without drawbacks.
In terms of development flow, the focus on integration and acceptance tests meant slower feedback loops and the tests take longer to execute. Also, because we don’t mock downstream services it means we couldn’t run tests without internet connection, which is an occasional annoyance when you want to work during commute.
These were explicit tradeoffs we made, and I stand by them even now and AFAIK everyone in the team feels the same way.
In terms of deployment, I really missed the ability to do canary releases. Although this is offset by the fact that our user base was still relatively small and the speed with which one can deploy and rollback changes with Lambda functions was sufficient to limit the impact of a bad change.
Whilst AWS Lambda and API Gateway doesn’t support canary releases out-of-the-box it is possible to do a DIY solution for APIs using weighted routing in Route53. Essentially you’ll have:
- a canary stage for API Gateway and associated Lambda function
- deploy production builds to the canary stage first
- use weighted routing in Route53 to direct X% traffic to the canary stage
- monitor metrics, and when you’re happy with the canary build, promote it to production
Again, this would only work for APIs and not for background processing (SNS, Kinesis, S3, etc.).
So that’s it folks, hope you’ve enjoyed this post, feel free to leave a comment if you have any follow up questions or tell me what else you’d like to hear about in part 3.
Ciao!
Links
- Part 1 – overview of our architecture
- Growing Object-Oriented Software, Guided by Tests
- [slides] AWS Lambda from the Trenches
- [InfoQ] Complexity is outside the Code
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: AWS Lambda – build yourself a URL shortener in 2 hours | theburningmonk.com
Really fantastic blog post Yan. Thanks for sharing everything you’ve learned working with Serverless architectures. I’m curious to know if your new ventures are leveraging similar (serverless) architectures now that Yubl is no more?
Also wondering if you’ve had a chance to do any work with Azure Functions and how you feel it compares in terms of maturity/feature parity to an AWS stack.
We have started to do small pieces of work with Lambda at my new job (eg. this), hopefully there’ll be much more to come there.
I haven’t worked with Azure Functions myself, but a friend of mine have done plenty with his own startup and I have heard good things about it. It works differently in that the output of an Azure function typically go straight into another service unlike Lambda. In terms of maturity it’s no doubt behind AWS but the important things are all there – rich set of input + output services that you can hook up to, logging, monitoring, alerting, etc. Oh, and you have a much wider range of programming languages that are supported by Azure Functions at the moment.
Pingback: Serverless CI/CD Tutorial, part 1: Build – 1Strategy