
Yan Cui
I help clients go faster for less using serverless technologies.

First of all, apologies for taking months to write this up since part 1, I have been extremely busy since joining Yubl. We have done a lot of work with AWS Lambda and I hope to share more of the lessons we have learnt soon, but for now take a look at this slidedeck to get a flavour.
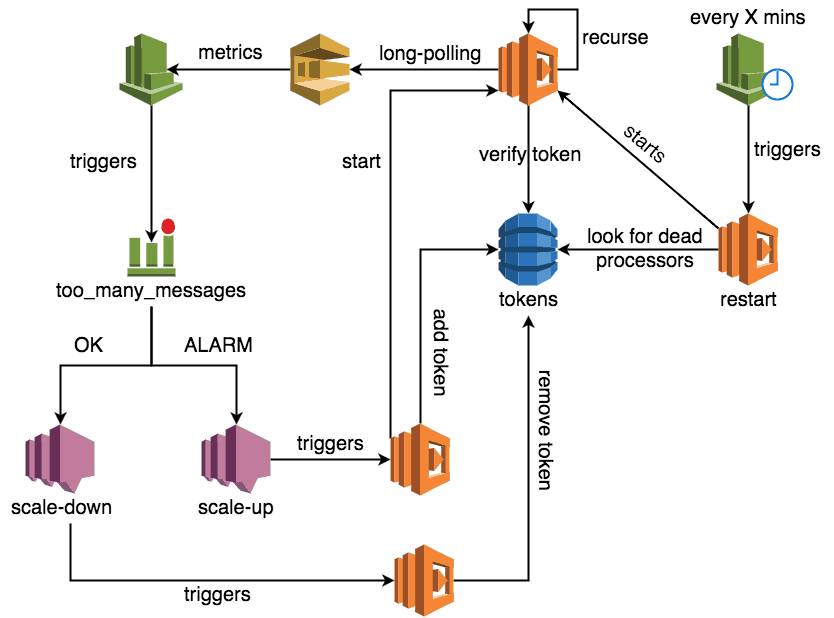
At the end of part 1 we have a recursive Lambda function that will:
- fetch messages from SQS using long-polling
- process any received messages
- recurse by invoking itself asynchronously
however, on its own there are a number of problems:
- any unhandled exceptions will kill the loop
- there’s no way to scale the no. of processing loops elastically
We can address these concerns with a simple mechanism where:
- a DynamoDB table stores a row for each loop that should be running
- when scaling up, a new row is added to the table, and a new loop is started with the Hash Key (let’s call it a token) as input;
- on each recursion, the looping function will check if its token is still valid
- if yes, then the function will upsert a last_used timestamp against its token
- if not (ie, the token is deleted) then terminates the loop
- when scaling down, one of the tokens is chosen at random and deleted from the table, which causes the corresponding loop to terminate at the end of its current recursion (see above)
- another Lambda function is triggered every X mins to look for tokens whose last_used timestamp is older than some threshold, and starts a new loop in its place
Depending on how long it takes the processing function to process all its SQS messages – limited by the max 5 min execution time – you can either adjust the threshold accordingly. Alternatively, you can provide another GUID when starting each loop (say, a loop_id?) and extend the loop’s token check to make sure the loop_id associated with its token matches its own.
High Level Overview
To implement this mechanism, we will need a few things:
- a DynamoDB table to store the tokens
- a function to look for dead loops restart them
- a CloudWatch event to trigger the restart function every X mins
- a function to scale_up the no. of processing loops
- a function to scale_down the no. of processing loops
- CloudWatch alarm(s) to trigger scaling activity based on no. of messages in the queue
- SNS topics for the alarms to publish to, which in turn triggers the scale_up and scale_down functions accordingly*
* the SNS topics are required purely because there’s no support for CloudWatch alarms to trigger Lambda functions directly yet.
A working code sample is available on github which includes:
- handler code for each of the aforementioned functions
- s-resources-cf.json that will create the DynamoDB table when deployed
- _meta/variables/s-variables-*.json files which also specifies the name of the DynamoDB table (and referenced by s-resources-cf.json above)
I’ll leave you to explore the code sample at your own leisure, and instead touch on a few of the intricacies.
Setting up Alarms
Assuming that your queue is mostly empty as your processing is keeping pace with the rate of new items, then a simple staggered set up should suffice here, for instance:
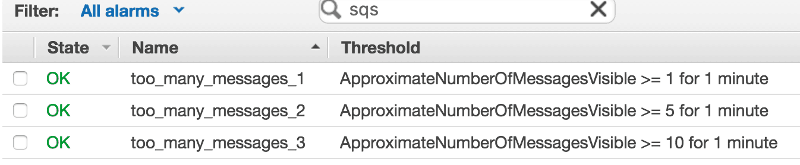
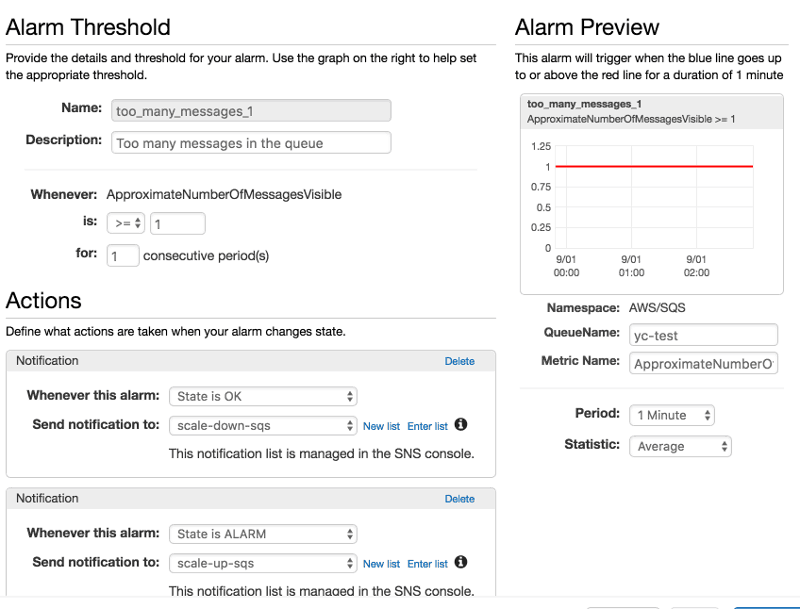
Each of the alarms would send notification to the relevant SNS topic on ALARM and OK.
Verifying Tokens
Since there’s no way to message a running Lambda function directly, we need a way to signal it to stop recursing somehow, and this is where the DynamoDB table comes in.
At the start of each recursion, the processing-msg function will check against the table to see if its token still exists. And since the table is also used to record a heartbeat from the function (for the restart function to identify failed recursions), it also needs to upsert the last_used timestamp against the token.
We can combine the two ops in one conditional write, which will fail if the token doesn’t exist, and that error will terminate the loop.
ps. I made the assumption in the sample code that processing the SQS messages is quick, hence why the timeout setting for the process-msg function is 30s (20s long polling + 10s processing) and the restart function’s threshold is a very conservative 2 mins (it can be much shorter even after you take into account the effect of eventual consistency).
If your processing logic can take some time to execute – bear in mind that the max timeout allowed for a Lambda function is 5 mins – then here’s a few options that spring to mind:
- adjust the restart function’s threshold to be more than 5 mins : which might not be great as it lengthens your time to recovery when things do go wrong;
- periodically update the last_used timestamp during processing : which also needs to be conditional writes, whilst swallowing any errors;
- add an loop_id in to the DynamoDB table and include it in the ConditionExpression : that way, you keep the restart function’s threshold low and allow the process-msg function to occasionally overrun; when it does, a new loop is started in its place and takes over its token with a new loop_id so that when the overrunning instance finishes it’ll be stopped when it recurses (and fails to verify its token because the loop_id no longer match)
Both option 2 & 3 strike me as reasonable approaches, depending on whether your processing logic are expected to always run for some time (eg, involves some batch processing) or only in unlikely scenarios (occasionally slow third-party API calls).
Scanning for Failed Loops
The restart function performs a table scan against the DynamoDB table to look for tokens whose last_used timestamp is either:
- not set : the process-msg function never managed to set it during the first recursion, perhaps DynamoDB throttling issue or temporary network issue?
- older than threshold : the process-msg function has stopped for whatever reason
By default, a Scan operation in DynamoDB uses eventually consistent read, which can fetch data that are a few seconds old. You can set the ConsistentRead parameter to true; or, be more conservative with your thresholds.
Also, there’s a size limit of 1mb of scanned data per Scan request. So you’ll need to perform the Scan operation recursively, see here.
Find out QueueURL from SNS Message
In the s-resources-cf.json file, you might have noticed that the DynamoDB table has the queue URL of the SQS queue as hash key. This is so that we could use the same mechanism to scale up/down & restart processing functions for many queues (see the section below).
But this brings up a new question: “when the scale-up/scale-down functions are called (by CloudWatch Alarms, via SNS), how do we work out which queue we’re dealing with?”
When SNS calls our function, the payload looks something like this:
which contains all the information we need to workout the queue URL for the SQS queue in question.
We’re making an assumption here that the triggered CloudWatch Alarm exist in the same account & region as the scale-up and scale-down functions (which is a pretty safe bet I’d say).
Knowing when NOT to Scale Down
Finally – and these only apply to the scale-down function – there are two things to keep in mind when scaling down:
- leave at least 1 processing loop per queue
- ignore OK messages whose old state is not ALARM
The first point is easy, just check if the query result contains more than 1 token.
The second point is necessary because CloudWatch Alarms have 3 states – OK, INSUFFICIENT_DATA and ALARM – and we only want to scale down when transitioned from ALARM => OK.
Taking It Further
As you can see, there is a fair bit of set up involved. It’d be a waste if we have to do the same for every SQS queue we want to process.
Fortunately, given the current set up there’s nothing stopping you from using the same infrastructure to manage multiple queues:
- the DynamoDB table is keyed to the queue URL already, and
- the scale-up and scale-down functions can already work with CloudWatch Alarms for any SQS queues
Firstly, you’d need to implement additional configuration so that given a queue URL you can work out which Lambda function to invoke to process messages from that queue.
Secondly, you need to decide between:
- use the same recursive function to poll SQS, but forward received messages to relevant Lambda functions based on the queue URL, or
- duplicate the recursive polling logic in each Lambda function (maybe put them in a npm package so to avoid code duplication)
Depending on the volume of messages you’re dealing with, option 1 has a cost consideration given there’s a Lambda invocation per message (in addition to the polling function which is running non-stop).
So that’s it folks, it’s a pretty long post and I hope you find the ideas here useful. If you’ve got any feedbacks or suggestions do feel free to leave them in the comments section below.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Hi, I am playing with SNS, SQS, and lambda. I have an EC2 instance that send messages to SNS and that is listening SQS queue “A”. SNS send received messages to lambda that send an answer to SQS queue “A”.
To test, I send 1, 10, or even 50 notifications to SNS. it works great but there is a big latency issue each time a new lambda has to be started. I am afraid that each time a new user arrives on my website he has low latency.
I was planning to develop my microservices (user creation, research by keywords, …) with lambda but when I see results I think it’s a terrible idea.
Am I right to think your solution resolves this issue ?
I don’t fully understand your setup, but if the issue is to do with new lambda functions taking more time to load (the cold start problem is common in this space) then one thing you could try is to have another function triggered by CloudWatch event (say, every minute) and ping other functions and keep them warm.
Typically we see cold starts after a function is idle for a few mins and if it stays active we still see cold starts after a few hours – the IOPipe guys have more details on this https://www.iopipe.com/2016/09/understanding-aws-lambda-coldstarts/
Hey Yan,
How do we see this simplify with the DeadLetterQueue support announcement from AWS – http://docs.aws.amazon.com/lambda/latest/dg/dlq.html?
Please advice. Thank you.
Hey Yan,
How do we see this simplify with the DeadLetterQueue support announcement from AWS – http://docs.aws.amazon.com/lambda/latest/dg/dlq.html?
Please advice. Thank you.
Hey Yan,
How do we see this simplify with the DeadLetterQueue support in Lambda now based latest announcement from AWS – http://docs.aws.amazon.com/lambda/latest/dg/dlq.html?
Please advice. Thank you.
Good question, I haven’t had a chance to try out the SQS support for Lambda yet. I’ll update once I’ve had a chance to play around with it and formulate some ideas.
Pingback: Year in Review, 2016 | theburningmonk.com
hey Yan,
I’m an AWS beginner, but would this work as an alternative with lower latency (as compared with polling)?
Whatever mechanism writes to SQS, can follow up by modifying a row corresponding to that queue, e.g. with Key=${queue_url}, in a DynamoDB table.
The event source to your Lambda can then be a DynamoDB stream from this table. On each put/modify it can poll the corresponding SQS queue, where an item is guaranteed to be queued.
Thanks,
-Mark
you can disregard my previous comment about the DynamoDB-based kludge to minimize latency. I misread the bit about long-polling, and though it was just regular polling. Thanks!