
Yan Cui
I help clients go faster for less using serverless technologies.

UPDATE 07/09/2016 : read part 2 on how to elastically scale Lambda function based on no. of messages available in the queue.
It’s been a year since the release of AWS Lambda service and here at Yubl we’re at the start of an exciting journey to move our stack to Lambda (using the awesome Serverless framework).
One feature that’s sadly missing though, is support for SQS. Every AWS evangelist I have spoken to tells me that it’s one of the most requested features from their customers and that it’s coming. It’s not the first time I have heard this kind of non-committal response from those involved with Amazon and experience tells me not to expect it to happen anytime soon.
But, if you’re itching to use AWS Lambda with SQS and don’t wanna wait an unspecified amount of time to get there, you have some options right now:
- use SNS or Kinesis instead
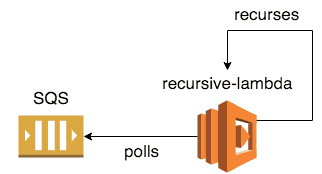
- do-it-yourself with recursive Lambda function that polls and processes SQS messages
TL;DR
Whilst you can use SNS and Kinesis with Lambda already, SQS‘s support for dead letter queues still makes it a better choice in situations where eventual consistency can be tolerated but outright data losses should be mitigated.
Whilst you can process SQS using EC2-hosted applications already, Lambda delivers a potential cost saving for low-traffic environments and more granular cost control as you scale out. It also provides an easy and fast deployment pipeline, with support for versioning and rollbacks.
Finally, we’ll walk through a simple example and write a recursive Lambda function in Node.js using the Serverless framework.
Lambda + SNS/Kinesis vs. Lambda + SQS
As a compromise, both SNS and Kinesis can be used with Lambda to allow you to delay the execution of some work till later. But semantically there are some important differences to consider.
Retries
SQS has built-in support for dead letter queues – i.e. if a message is received N times and still not processed successfully then it is moved to a specified dead letter queue. Messages in the dead letter queue likely require some manual intervention and you typically would set up CloudWatch alarms to alert you when messages start to pour into the dead letter queue.
If the cause is temporal, for example, there are outages to downstream systems – DB is unavailable, or other services are down/timing out – then the dead letter queue helps:
- prevent the build up of messages in the primary queue; and
- gives you a chance to retry failed messages after the downstream systems have recovered.
With SNS, messages are retried 3 times and then lost forever. Whether or not this behaviour is a showstopper for using SNS needs to be judged against your requirements.
With Kinesis, the question becomes slightly more complicated. When using Kinesis with Lambda, your degree of parallelism (discussed in more details below) is equal to the no. of shards in the stream. When your Lambda function fails to process a batch of events, it’ll be called again with the same batch of events because AWS is keeping track of the position of your function in that shard.
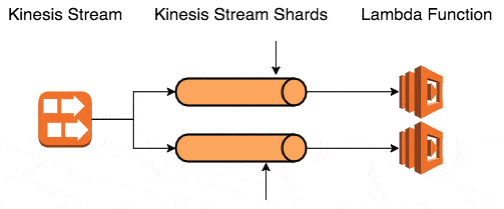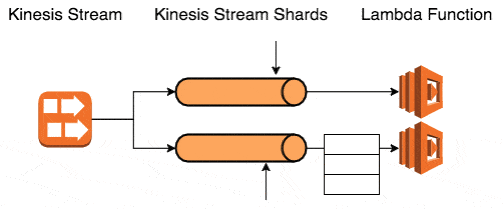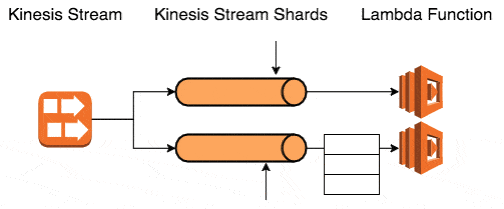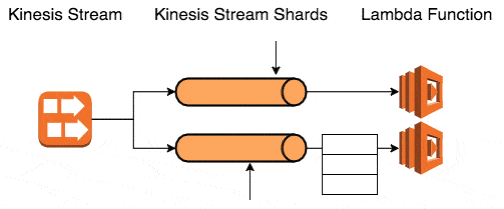
In essence, this means the retry strategy is up to you, but your choices are limited to:
- fail and always retry the whole batch (even if some messages were processed successfully) until either the fault heals itself or the messages in the batch are no longer available (Kinesis only keeps messages for up to 24 hours)
- never retry a failed batch
If you choose option 1 (which is the default behaviour), then you also have to ensure that messages are processed in a way that’s idempotent. If you choose option 2, then there’s a significant chance for data loss.
Neither option is very appealing, which is why I would normally use Kinesis in conjunction with SQS:
- process a batch of messages, and queue failed messages into SQS
- allow the processing of the shard to move on in spite of the failed messages
- SQS messages are processed by the same logic, which required me to decouple the processing logic from the delivery of payloads (SNS, SQS, Kinesis, tests, etc.)
Parallelism
SNS executes your function for every notification, and as such has the highest degree of parallelism possible.
There’s a soft limit of 100 concurrent Lambda executions per region (which you can increase by raising a support ticket), though according to the documentation, AWS might increase the concurrent execution limit on your behalf in order to execute your function at least once per notification. However, as a safety precaution you should still set up CloudWatch alarms on the Throttled metric for your Lambda functions.
With Kinesis (and DynamoDB Streams for that matter), the degree of parallelism is the same as the no. of shards.
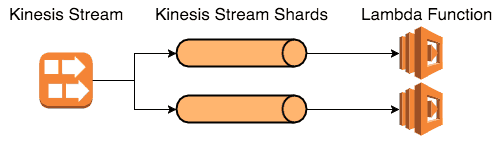
If you’re working with SQS today, the degree of parallelism would equal to the no. of poll loops you’re running in your cluster.
For example, if you’re running a tight poll loop for each core, and you have 3 quad-core EC2 instances in a cluster, then the degree of parallelism would be 3 instances * 4 cores = 12.
Moving forward, if you choose to use recursive Lambda functions to process SQS messages then you can choose the degree of parallelism you want to use.
Lambda + SQS vs. EC2 + SQS
Which brings us to the next question : if you can use EC2 instances to process SQS messages already, why bother moving to Lambda? I think the cost saving potentials, and the ease and speed of deployment are the main benefits.
Cost
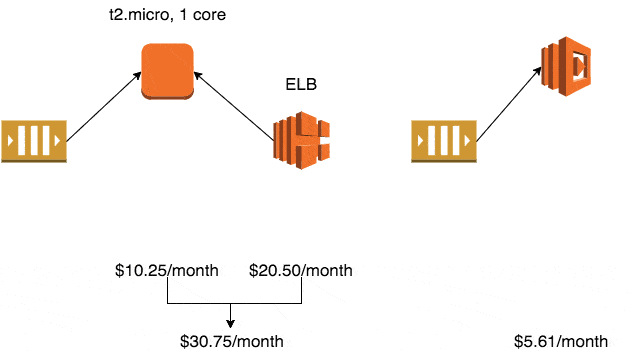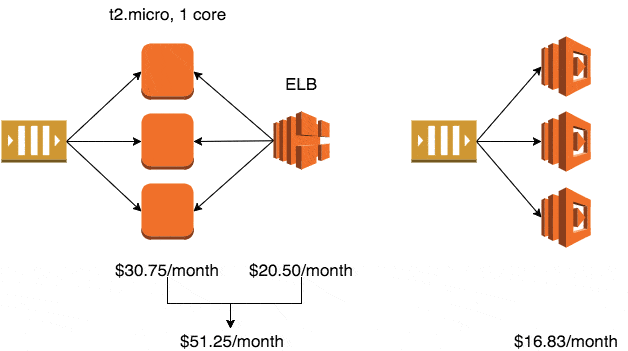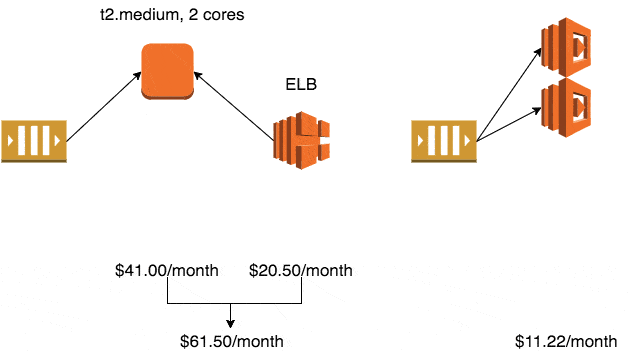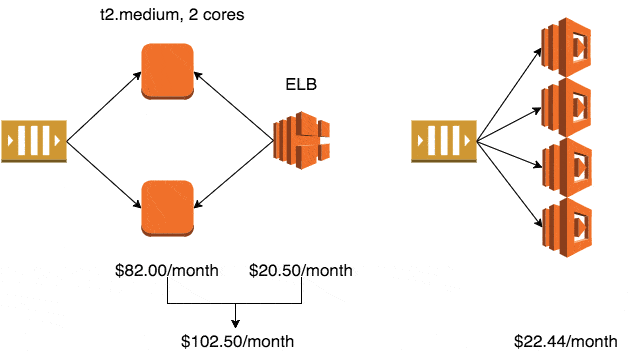
If you use the smallest production-ready EC2 class – Linux t2.micro – it will cost you $10.25/month in the eu-west-1 region (Ireland).
Whilst the auto-scaling service is free to use, the default EC2 health checks cannot be relied upon to detect when your application has stopped working. To solve this problem, you’ll typically setup an ELB and use ELB health checks to trigger application level checks to ensure it is still running and processing messages.
The ELB health checks also enables the auto-scaling service to automatically replace unhealthy instances.
A minimum production deployment would therefore cost you $30.75 a month.
A recursive Lambda function running non-stop 24/7 would run for 2678400 seconds a month.
60 s * 60 m * 24 hr * 31 days = 2678400 s
If you assign 128MB to your function, then your monthly cost for Lambda would be $5.61 a month.
Monthly Compute Charge
= Total Compute (GB-seconds) * ($0.00001667 /GB-second)
= (2678400 s * 128 MB / 1024 MB) * $0.00001667
= 334800 GB-seconds * $0.00001667
= $5.581116
Monthly Request Charge
= Total Requests * ($ 0.20/Million Reqs)
= (2678400 s / 20 s) / 1000000 * $ 0.20
= 133920 Req / 1000000 * $0.20
= $0.026784
Monthly Charge (Total)
= Monthly Compute Charge + Monthly Request Charge
= $5.581116 + $0.026784
= $5.6079
Since Lambda’s free tier does not expire 12 months after sign up, this would fall within the free tier of 400000 GB-seconds per month too.
However, there are other aspects to consider:
- you can process several SQS queues in one EC2 instance
- the cost of ELB is amortised as the size of cluster increases
- EC2 instance class jumps in cost but also offers more compute and networking capability
- in order to auto-scale your SQS-processing Lambda functions, you’ll need to provision other resources
The exact cost saving from using Lambda for SQS is not as clear cut as I first thought. But at the very least, you have a more granular control of your cost as you scale out.
A recursively executed, 128MB Lambda function would cost $5.61/month, whereas an autoscaled cluster of t2.micro instances would go up in monthly cost $10.25 at a time.
Deployment
In the IAAS world, the emergence of container technologies has vastly improved the deployment story.
But, as a developer, I now have another set of technologies which I need to come to grips with. The challenge of navigating this fast-changing space and making sensible decisions on a set of overlapping technologies (Kubernetes, Mesos, Nomad, Docker, Rocket, just to name a few) is not an easy one, and the consequence of these decisions will have long lasting impact on your organization.
Don’t get me wrong, I think container technologies are amazing and am excited to see the pace of innovation in that space. But it’s a solution, not the goal, the goal is and has always been to deliver values to users quickly and safely.
Keeping up with all that is happening in the container space is overwhelming, and at times I can’t help but feel that I am trading one set of problems with another.
As a developer, I want to deliver value to my users first and foremost. I want all the benefits container technologies bring, but make their complexities someone else’s problem!
One the best things about AWS Lambda – besides all the reactive programming goodness – is that deployment and scaling becomes Amazon‘s problem.
I don’t have to think about provisioning VMs and clustering applications together; I don’t have to think about scaling the cluster and deploying my code onto them. I don’t have to rely on an ops team to monitor and manage my cluster and streamline our deployment. All of them, Amazon‘s problem! ![]()
All I have to do to deploy a new version of my code to AWS Lambda is upload a zip file and hook up my Lambda function to the relevant event sources and it’s job done!
Life becomes so much simpler ![]()
With the Serverless framework, things get even easier!
Lambda supports the concept of versions and aliases, where an alias is a named version of your code that has its own ARN. Serverless uses aliases to implement the concept of stages – ie. dev, staging, prod – to mirror the concept of stages in Amazon API Gateway.
To deploy a new version of your code to staging:
- you publish a new version with your new code
- update the staging alias to point to that new version
- and that’s it! Instant deployment with no downtime!
Similarly, to rollback staging to a previous version:
- update the staging alias to point to the previous version
- sit back and admire the instant rollback, again with no downtime!
What’s more? Serverless streamlines these processes into a single command!
Writing a recursive Lambda function to process SQS messages with Serverless
(p.s. you can find the source code for the experiment here.)
First, let’s create a queue in SQS called HelloWorld.
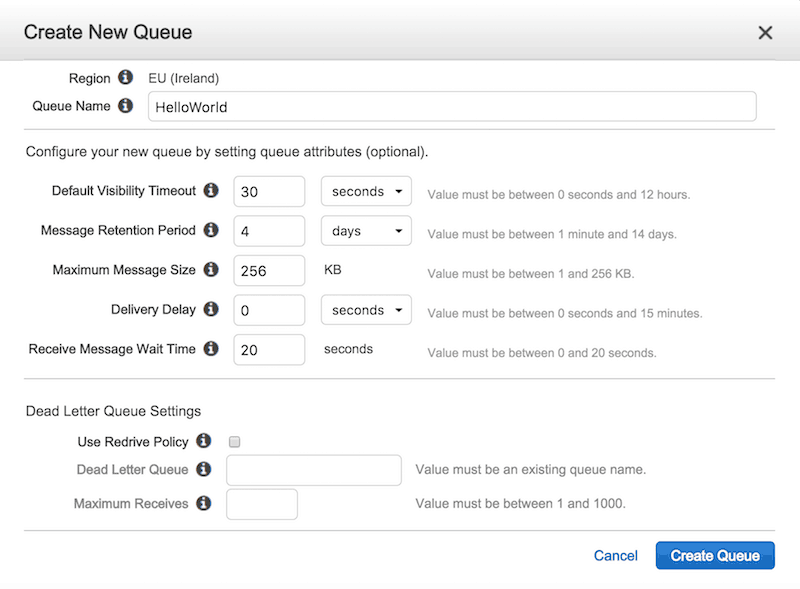
Notice that although we have specified the default visibility timeout and receive message wait time (for long polling) values here, we’ll override them in the ReceiveMessage request later.
Then we’ll create a new Serverless project, and add a function called say-hello.
Our project structure looks roughly like this:

In the handler.js module, let’s add the following.
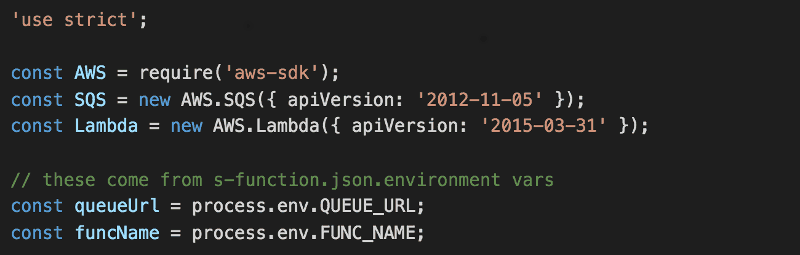
Notice we’re relying on two environment variables here – QUEUE_URL and FUNC_NAME. Both will be populated by Serverless using values that we specify in s-function.json (to understand how this works, check out Serverless’s documentation).
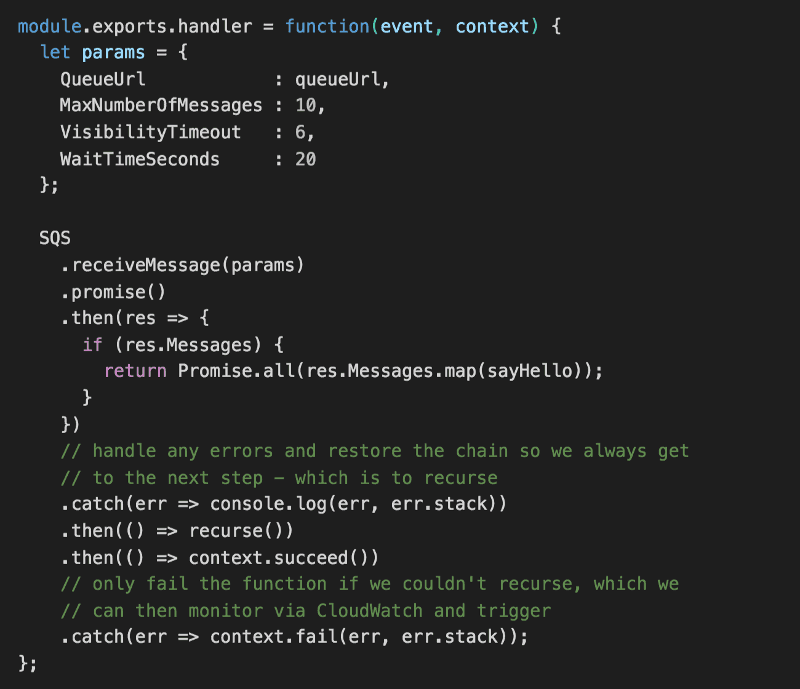
Next, we’ll write the handler code for our Lambda function.
Here, we will:
- make a ReceiveMessage request to SQS using long polling (20s)
- for every message we receive, we’ll process it with a sayHello function (which we’ll write next)
- the sayHello function will return a Promise
- when all the messages have been processed, we’ll recurse by invoking this Lambda function again
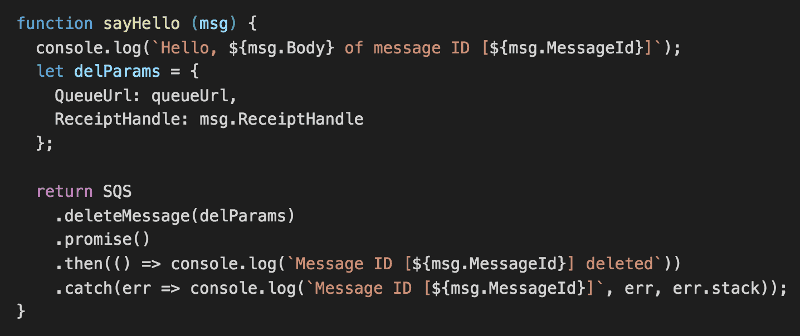
In the sayHello function, we’ll log a message and delete the message in SQS.
One caveat to remember is that, Promise.all will reject immediately if any of the Promises rejects. Which is why I’m handling any error related to deleting the message in SQS here with .catch – it’ll restore the chain rather than allowing the reject to bubble up.
This implementation, however, doesn’t handle errors arising from processing of the message (i.e. logging a message in this case). To do that, you’ll have to wrap the processing logic in a Promise, eg.
return new Promise((resolve, reject) => {
// processing logic goes here
resolve();
})
.then(() => SQS.deleteMessage(delParams).promise())
.then(…)
.catch(…);
Finally, let’s add a recurse function to invoke this function again.
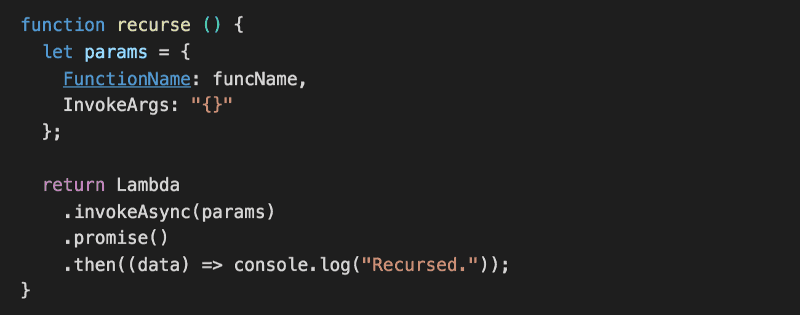
Couple of things to note about this function:
- unlike sayHello, it doesn’t catch its own errors, this allows the reject to bubble up to the main handler function which will then fail the current execution
- by failing the current execution this way we can use the Errors metric in CloudWatch to re-trigger this Lambda function (more on this in Part 2)
- we’re calling invokeAsync instead of invoke so we don’t have to (in this case we can’t!) wait for the function to return
Deploying the Lambda function
You’ll notice that we haven’t provided any values for the two environment variables – QUEUE_URL and FUNC_NAME – we mentioned earlier. That’s because we don’t have the ARN for the Lambda function yet!
So, let’s deploy the function using Serverless. Run serverless dash deploy and follow the prompt.
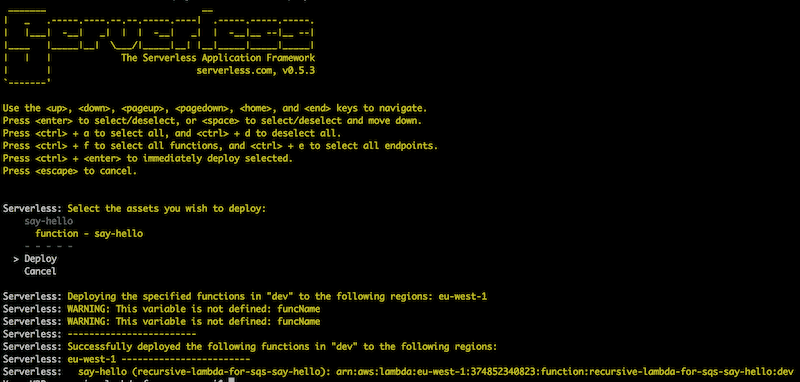
Aha, there’s the ARN for our Lambda function!
Go back to the project, open _meta/variables/s-variables-dev-euwest1.json and add the variables queueUrl and funcName.

However, there’s another layer of abstraction we need to address to ensure our environment variables are populated correctly.
Open processors/say-hello/s-function.json.
In the environment section, add QUEUE_URL and FUNC_NAME like below:
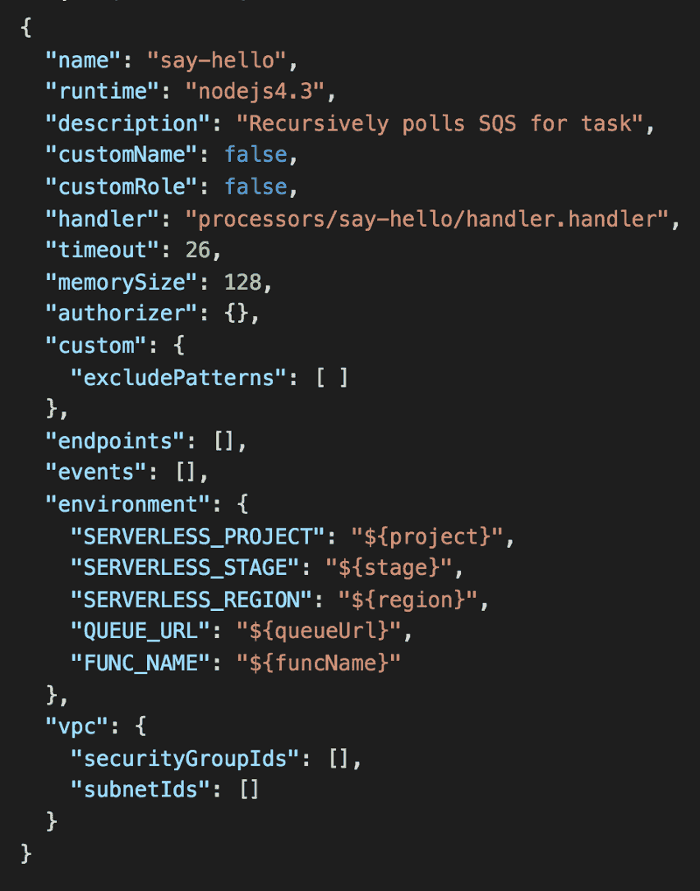
Now do you see how things fit together?

Since we’ve made changes to environment variables, we’ll need to redeploy our Lambda function.
Testing the deployed Lambda function
Once your Lambda function is deployed, you can test it from the management console.
See that blue Test button on the top left? Click that.
Since our function doesn’t make use of the incoming payload, you can send it anything.
Oops.
If you run the function as it stands right now, you’ll get a permission denied error because the IAM role the Lambda service uses to call our function with doesn’t have permissions to use the SQS queue or to invoke a Lambda function.
That’s great, because it tells me I have granular control over what my Lambda functions can do and I can control it using IAM roles.
But we do need to go back to the project and give our function the necessary permissions.
Configuring execution role permissions
Back in the Serverless project, take a look at s-resources-cf.json in the root directory. This is a templated CloudFormation file that’s used to create the AWS resources for your function, including the execution role for your functions.
Wherever you see ${stage} or ${region}, these will be substituted by variables of the same name under _meta/variables/xxx.json files. Have a read of the Serverless documentation if you wanna dig deeper into how the templating system works.
By default, Serverless creates an execution role that can log to CloudWatch Logs.
{
“Effect”: “Allow”,
“Action”: [
“logs:CreateLogGroup”,
“logs:CreateLogStream”,
“logs:PutLogEvents”
],
“Resource”: “arn:aws:logs:${region}:*:*”
}
You can edit s-resources-cf.json to grant the execution role permissions to use our queue and invoke the function to recurse. Add the following statements:
{
“Effect”: “Allow”,
“Action”: [
“sqs:ReceiveMessage”,
“sqs:DeleteMessage”
],
“Resource”: “arn:aws:sqs:${region}:*:HelloWorld”
},
{
“Effect”: “Allow”,
“Action”: “lambda:InvokeFunction”,
“Resource”: “arn:aws:lambda:${region}:*:function:recursive-lambda-for-sqs-say-hello:${stage}”
}
We can update the existing execution role by deploying the CloudFormation change. To do that with Serverless, run serverless resources deploy (you can also use sls shorthand to save yourself some typing).

If you test the function again, you’ll see in the logs (which you can find in the CloudWatch Logs management console) that the function is running and recursing.
Now, pop over to the SQS management console and select the HelloWorld queue we created earlier. Under the Queue Actions drop down, select Send Message.
In the following popup, you can send a message into the queue.
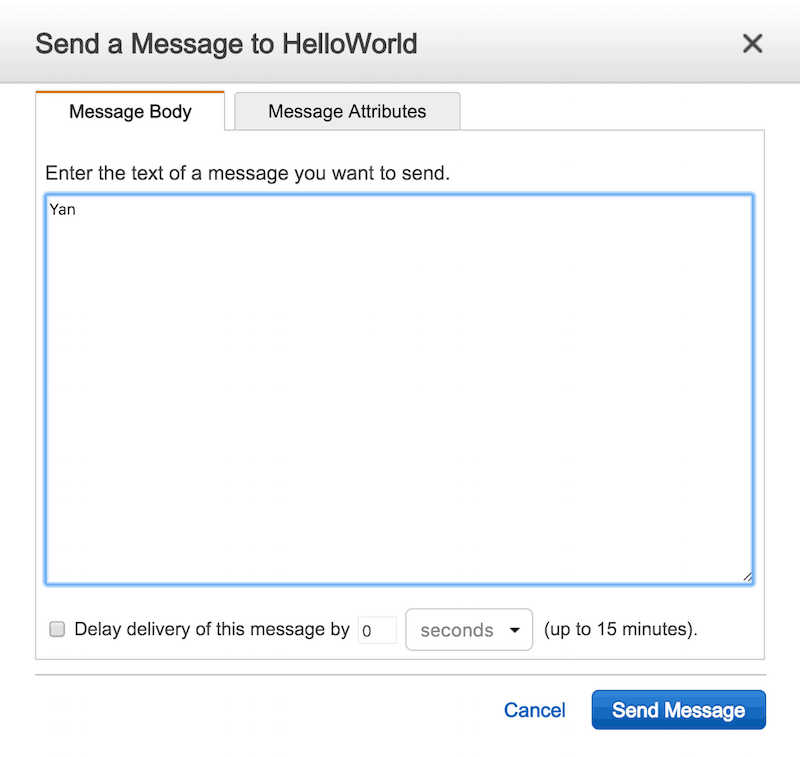
Once the message is sent, you can check the CloudWatch Logs again, and see that message is received and a “Hello, Yan of message ID […]” message was logged.
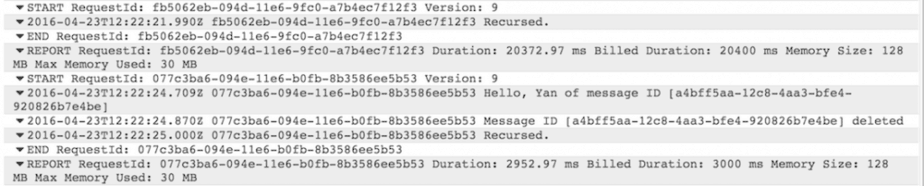
and voila, our recursive Lambda function is processing SQS messages! ![]()
In Part 2, we’ll look at a simple approach to autoscale the no. of concurrent executions of our function, and restart failed functions.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Great article! Any timeline as to when the Part II will come out?
Thank you, part 2 should be out the next day or so, finally got around to writing it!
Is the trigger to start the recursion/polling the test message?
You can kick off the recursion with a test message, yes, but in a real running environment you’ll have something else (probably another Lambda function like the ‘restart’ function mentioned in part 2) do it
Hello Yan,
How do we update this Architecture to incorporate the DeadLetterQueue support announcement from AWS – http://docs.aws.amazon.com/lambda/latest/dg/dlq.html?
For those needing a more generic recursive plugin check this out: https://www.npmjs.com/package/recursive-lambda.
Hope it helps.
nice artlicle, but shouldnt the lambda also be configured as a Cloudwatch scheduled event e.g.
sqlConsumerLambda:
handler: handler.bla
events:
– schedule: rate(1 minute)
?
Hi Emmet,
The idea here is to not rely on a scheduled event to poll SQS because it sets in stone how often you poll SQS and doesn’t scale dynamically based on load and how fast you’re processing incoming messages. The limitation here is that you can’t recover from a failed invokation and would need some way to restart the recursive loop, and you need a mechanism for scaling up & down the no. of parallel loops you’re running based on load (the same way you’ll do for EC2), which is where part 2 comes in.
so what is triggering you lambda that reads the queue ?
from what I have read , one can use dead letter queues with SNS too
“With SNS, messages are retried 3 times and then lost forever. Whether or not this behaviour is a showstopper for using SNS needs to be judged against your requirements.”
Hi Emmet,
Since I wrote the post AWS has introduced dead lettering queues for Lambda, so the concern of dropping SNS messages due to temporal issue (eg. downstream systems having problems) has been eased.
Cheers,
Hi Emmet,
For the simple setup in this part, you can kick it off the recursive loop by invoking the function in any way you wish – aws cli, from the AWS console, programmatically from your code/script, etc.
The setup in part 2 does use CW events (for scaling & restarting dead recursive loops) which doubles up as initially kicking off polling the queue (ie. scaling from 0 loops to 1).