
Yan Cui
I help clients go faster for less using serverless technologies.

Hello! Sorry for the lack of posts recently, it’s been a pretty hectic time here at Yubl, with plenty of exciting work happening and even more on the way. Hopefully I will be able to share with you some of the cool things we have done and valuable lessons we have learnt from working with AWS Lambda and Serverless in production.
Today’s post is one such lesson, a slightly baffling and painful one at that.
The Symptoms
We noticed that the Lambda function behind one of our APIs in Amazon API Gateway was timing out consistently (the function is configured with a 6s timeout, which is what you see in the diagram below).
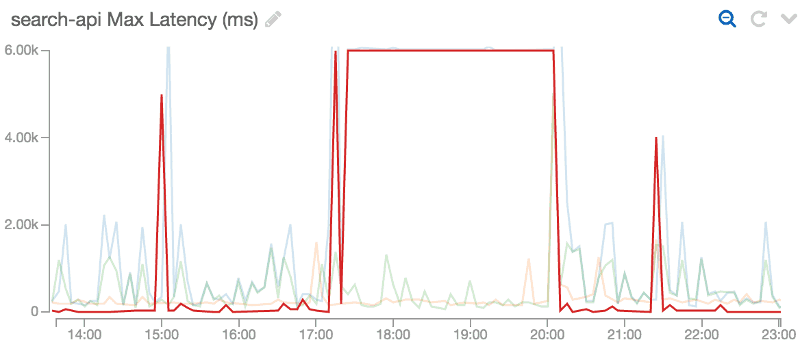
Looking in the logs it appears that one instance of our function (based on the frequency of the timeouts I could deduce that AWS Lambda had 3 instances of my function running at the same time) was constantly timing out.
What’s even more baffling is that, after the first timeout, the subsequent Lambda invocations never even enters the body of my handler function!
Considering that this is a Node.js function (running on the Node.js 4.3 runtime), this symptom is similar to what one’d expect if a synchronous operation is blocking the event queue so that nothing else gets a chance to run. (oh, how I miss Erlang VM’s pre-emptive scheduling at this point!)
So, as a summary, here’s the symptoms that we observed:
- function times out the first time
- all subsequent invocations times out without executing the handler function
- continues to timeout until Lambda recycles the underlying resource that runs your function
which, as you can imagine, is pretty scary – one strike, and you’re out! ![]()
Oh, and I managed to reproduce the symptoms with Lambda functions with other event source types too, so it’s not specific to API Gateway endpoints.
Bluebird – the likely Culprit
After investigating the issue some more, I was able to isolate the problem to the use of bluebird Promises.
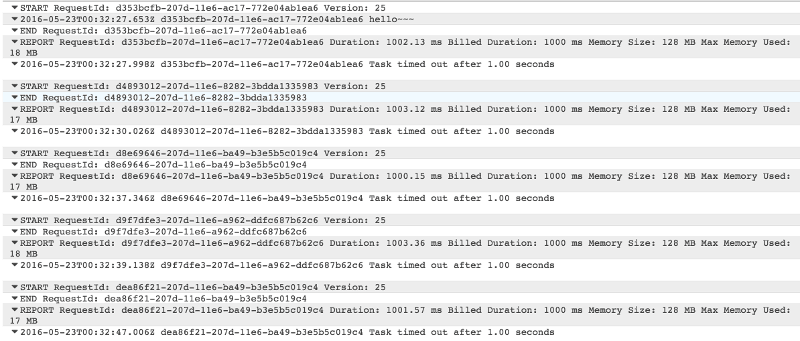
I was able to replicate the issue with a simple example below, where the function itself is configured to timeout after 1s.

As you can see from the log messages below, as I repeatedly hit the API Gateway endpoint, the invocations continue to timeout without printing the hello~~~ message.
At this point, your options are:
a) wait it out, or
b) do a dummy update with no code change
On the other hand, a hand-rolled delay function using vanilla Promise works as expected with regards to timeouts.

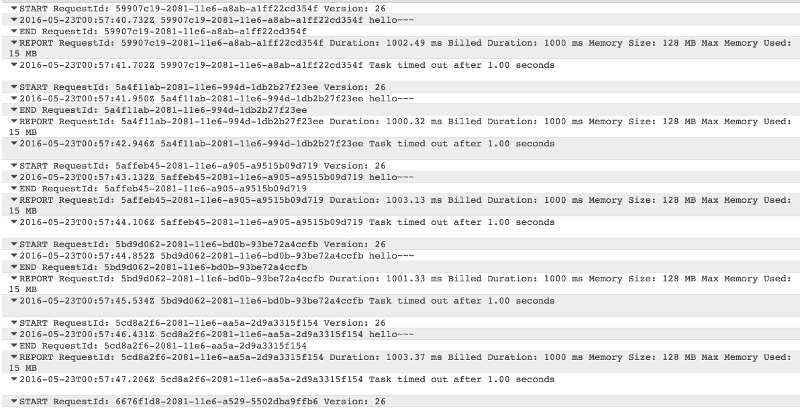
Workarounds
The obvious workaround is not to use bluebird, and any library that uses bluebird under the hood – e.g. promised-mongo.
Which sucks, because:
- bluebird is actually quite useful, and we use both bluebird and co quite heavily in our codebase
- having to check every dependency to make sure it’s not using bluebird under the hood
- can’t use other useful libraries that use bluebird internally
However, I did find that, if you specify an explicit timeout using bluebird‘s Promise.timeout function then it’s able to recover correctly. Presumably using bluebird’s own timeout function gives it a clean timeout whereas being forcibly timed out by the Lambda runtime screws with the internal state of its Promises.
The following example works as expected:

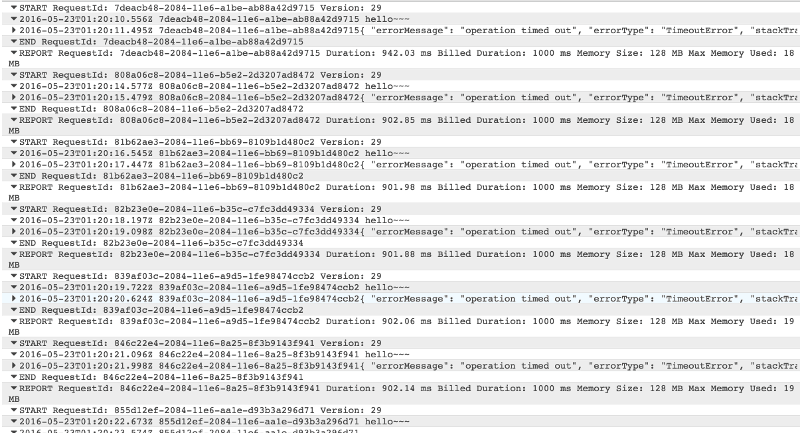
But, it wouldn’t be a workaround if it doesn’t have its own caveats.
It means you now have one more error that you need to handle in a graceful way (e.g. mapping the response in API Gateway to a 5XX HTTP status code), otherwise you’ll end up sending this kinda unhelpful responses back to your callers.

So there, a painful lesson we learnt whilst running Node.js Lambda functions in production. Hopefully you have found this post in time before running into the issue yourself!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
The first thing I noticed is that you are not calling the call back function. You might do it later in code you aren’t currently showing. But if you aren’t then it might not be making a clean closing of the function. Many times people will call the callback function `done` to emphasize that calling it will indicate that the function is done.
function (x, context, done) {
Promise
.delay(3e3)
.then(doSomething)
.then(done)
.catch(R.compose(done, catchSomething))
}
Hi, calling `context.succeed()` and `context.fail()` is the same as calling done without error and with error respectively. Granted, it’s the convention from the Node.js 0.10 days but it still works with Node.js 4.3 (though they might decide to deprecate it at some point in the future).
Nonetheless, `context.succeed()` and `context.fail()` still works today.
Just confirmed the same problem happens with the following:
module.exports.handler = function(event, context, cb) {
console.log(‘hello~~~’);
Promise
.delay(3000)
.then(() => cb(null, {}))
.catch(err => cb(err, err.stack));
};
How do you like programming w/ node.js vs F#? I much prefer F# but JS has some definite advantages. My biggest thing that I like about F# is static typing and the clean syntax. JS makes it really easy to mix and match objects which is super nice.
I still don’t see the value of Bluebird. You’re writing the same amount of code to achieve what?
This works just as well:
function testTimeout(duration, cb) {
setTimeout(function() {
cb(null);
}, 1000)
}
testTimeout(3000, function(err, result) {
if (err) {
console.log(err);
context.fail(err);
} else {
console.log(‘DONE’);
context.succeed(result);
}
});
we use Bluebird to promisify bunch a bunch of other libs that don’t offer Promise yet, this code snippet is just the minimal set to illustrate the problem..
We have seen this exact issue a lot whilst working with Lambda. From my own experiments and from conversations with AWS support I think the issue is actually the time it takes to load your function.
In short, for some reason after a timeout or error the next invocation takes a lot of time (like seconds) to “require” in any bundled dependencies. It was a particular issue for us as we had a very large shared library that we used heavily.
So mitigating the issue for us was two things:
1. Bump the memory of our functions, this also increases the CPU and really speeds up the load time
2. Decrease the amount of dependencies – we massively reduced the size of our shared library.
So if it is the same issue, in your example I would maybe guess you are not pulling in the bluebird library at all in your second test and it is this that is actually causing the subsequent timeouts.
In our case the deployment packages aren’t big, < 2mb (one of the reasons why we prefer to use bluebird to promisify the aws-sdk that comes with the runtime rather than bundle in the latest version of aws-sdk that supports Promise).
That said, we only saw the issue with 128mb memory setting, and since then we too have stayed away with that setting.
Yan,
I had the same kind of issue but not as you. I was trying to store data in redshift for every lambda call, so after one of my call failed, the next ones kept failing.
I thought it was something related to event loop freezing in lambda(as you explained), but it was not. The problem with my issue was that I put redshiftClient as a global variable and since the lambda runtime uses the old processes for new calls, the global variable is not re-initialized. It kept using the old variable for which the database connection failed. So moving the client initialization inside the function fixed the issue. (Solution: Don’t put variables in global scope, you can keep constants).
I know it is not related to your post, but it can be useful for someone.
Thanks
It’s not clear from your blog post, nor from the github issues of bluebird, if you have ever reported this. Did you?
Just a quick note to say that increasing my Lambda memory from 128 MB to 256 MB resolved my delayed start / timeout issues, too. Thanks to Yan Cui for the original post and James Skinner for pointing me in that direction.
Thanks for a) showing someone else had this problem, as I was going crazy. I don’t use bluebird, but firebase-node uses request which uses hal-validator which uses pinkie. Presume it has the same issue..
b) the completely counterintuitive suggestion of a higher mem lambda. will try 192 (about 170 more than the instance needs)
Nicely done, good detective work. We were seeing the exact same behavior. Using bluebird, not even seeing the handler invoked. Totally mystifying. Thanks for blogging!
Thanks for sharing your findings. Thanks God i did not have to look for answers to long. This is a pretty frustrating issue.
The issue is with the loading of external libraries.
try to bundle things using webpack or something. it solved the problem for me.
I also had to bundle “babel-runtime” as I am using es2015.
It was not straight forward and it took me time to get all of these together.
thanks @joekiller and the other pals for giving me some hints.
Oh my god. For anyone else who ends up here like I did – first make sure you haven’t accidentally deployed `AWS.config.update(…)` using a localhost endpoint instead of an actual production endpoint. Because this will present with very similar symptoms.
I submitted a bug to AWS and they got back to me saying they made a change and deployed it to all regions. We’re evaluating whether it fixes our bugs now.
If anyone else can reload their function by changing and ENV variable etc. it would be great to hear from someone else that they observe a difference in how bluebird-backed node modules work.
Hi John, that’s great news! Thanks for letting me know.
Hi, I pinned down this problem a while back. The TLDR; is if the non-handler based code takes up more than 13% of the function’s maximum memory and during the execution a Lambda timeout is triggered the function will cease to handle anything until after 30 minutes (when the function is recycled by AWS).
Short fix: bump your memory to ensure the reported maximum usage is less than 13% of the maximum memory available.
Longer explaination: It seems to have to do with the amount of code loaded into the lambda function’s memory space that persists between invocations. Note that this only applies to NodeJS. The unresponsive lambda problem is a combination of states, first the non-handler memory consumption must be at least > 13% (it varies depending on the size of the function but 13+ always works) and then a global timeout must be triggered. So if the Lambda memory is loaded in this way, it appears that AWS has a bug that doesn’t freeze the memory snapshot correctly and hoses the handler. This especially can happen if you got some big libraries attached to your code. We were using funcool/promesa and pg-pool in compiled clojurescript so the code was heavy. Long story short, I worked out a pure JS example for AWS support so they could examine the problem. They acknowledged the problem and told me (per usual) to watch for it being fixed in a “whats new” post. Oh well.
This bug will bite hard and it is confusing. I haven’t tested it on other languages but I don’t think they have the problem.
Pure JS example: https://github.com/Type-Zero/promise-timeout-hang-js
Original Clojurescript Example (uses bluebird): https://github.com/Type-Zero/promise-timeout-hang
Hope this helps!
-Joe
Well it appears fixed now, so that is pretty great! Thanks for the article again, it was the beginning of nailing it down.
This is some impressive detective work!! John mentioned in the comments above that AWS reported the bug is fixed so hopefully it’s all good now!