

Yan Cui
I help clients go faster for less using serverless technologies.

A month ago, I shared how I built an affiliate tracking system in a weekend [1]. Since then, I’ve enhanced the system by integrating analytics reporting, enabling affiliates to gauge the performance of their URLs. This post will describe how the system works and why I chose Amazon Timestream over DynamoDB.
How it works
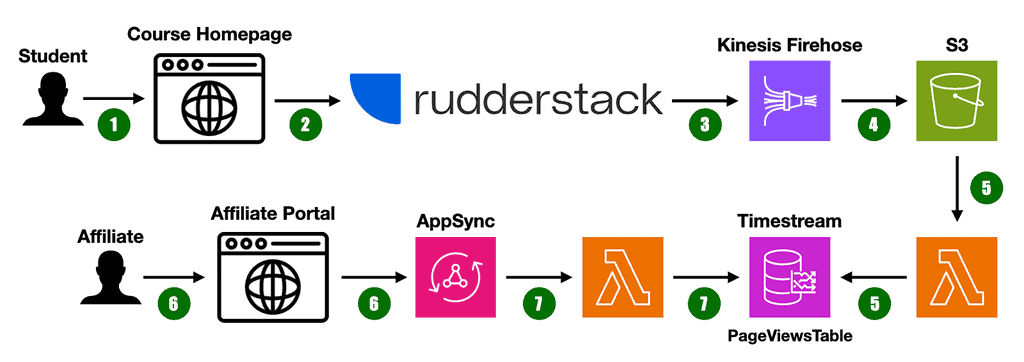
1. A student clicks on an affiliate’s URL and lands on a course homepage.
2. The page sends an anonymous page view event to RudderStack [2].
3. Rudderstack funnels the data to a Kinesis Firehose Stream in my AWS account.
4. The Kinesis Firehose Stream buffers 5 minutes’ worth of data into an S3 bucket.
5. Triggering a Lambda function to load and batch-write the events into a PageViewsTable in Timestream.
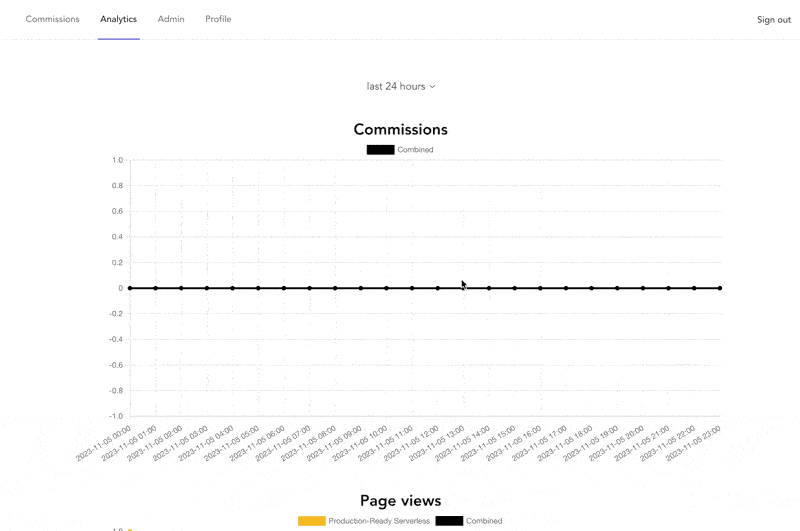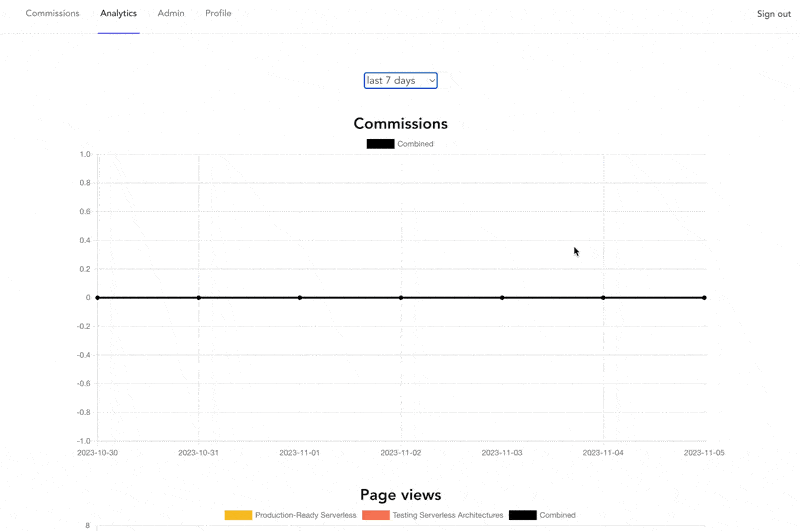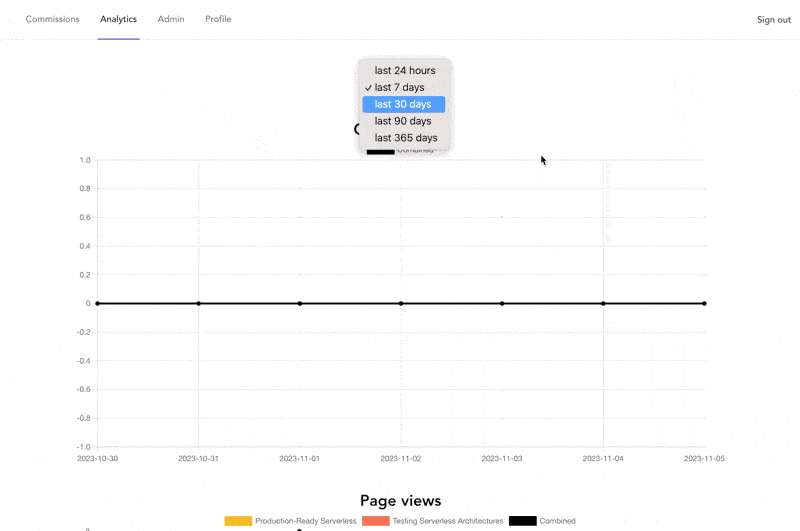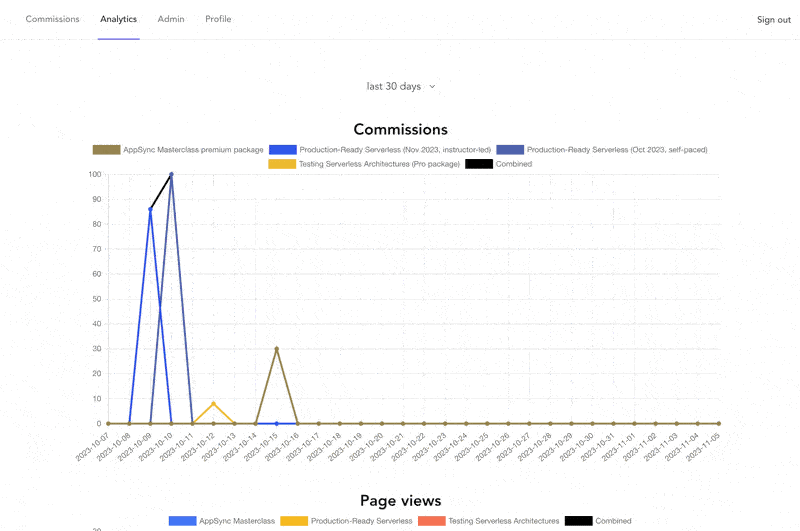
6. When an affiliate visits the affiliate portal, the front end retrieves the analytics data from the AppSync API. Using the following GraphQL operation:
type Query {
getAnalyticsData(
metricType: MetricType!
timeWindow: TimeWindow!
): AnalyticsData
}
enum MetricType {
PageViews
Visitors
Commissions
}
enum TimeWindow {
Last24Hours
Last7Days
Last30Days
Last90Days
Last365Days
}
type DataPoint {
series: String!
timestamp: String!
value: Float!
}
type AnalyticsData {
dataset: [DataPoint]!
}
7. A Lambda resolver fetches the data from the PageViewsTable with a query like this:
SELECT website, sum(measure_value::bigint) AS value, date_trunc('day', time) AS timestamp
FROM "WebAnalyticsDb"."PageViewsTable"
WHERE "affiliate_id" = '${affiliateId}'
AND time between ago(7day) and now()
GROUP BY website, date_trunc('day', time)
As you can see, Timestream supports a SQL-like query syntax. And it supports some handy Date/Time functions [3] (such as date_trunc) that are very useful for analysing time series data.
Why RudderStack instead of Segment?
I chose RudderStack because of its generous free tier.
Segment’s free tier only allows up to 1000 monthly users and 2 data sources. I need to track page views for 3 courses [4], so I already exceeded the 2 data sources limit.
RudderStack’s free tier lets me send up to 1000 events per minute across 15 sources. Given the current traffic to my courses, I can comfortably stay within RudderStack’s free tier for the foreseeable future.
Why Amazon Timestream instead of DynamoDB?
As a time-series database, it’s a better fit for purpose for my use case.
With Timestream, I can query my data using an SQL-like syntax, which offers a lot more flexibility than DynamoDB.
I can perform inline aggregation [5] (e.g. sum, count, avg and approx_percentile). I can filter data by any of the recorded dimensions (e.g. affiliate_id) without having to first create dedicated indices.
DynamoDB is great, but I do miss the expressive power and flexibility that SQL can offer!
Timestream is a fully managed, serverless database. There’s no need to manage any infrastructure and I only pay for what I use.
Speaking of pricing [6], Timestream’s ingestion cost of $0.5 per million writes is also cheaper than DynamoDB ($1.25 per million). For queries, Timestream charges $0.01 per GB of data scanned. So on the cost front, it also compares well against DynamoDB.
On the other hand, the query latency from Timestream is pretty slow compared to DynamoDB. As you can see from the p95 and p99 latencies below (from my Lumigo [7] dashboard).
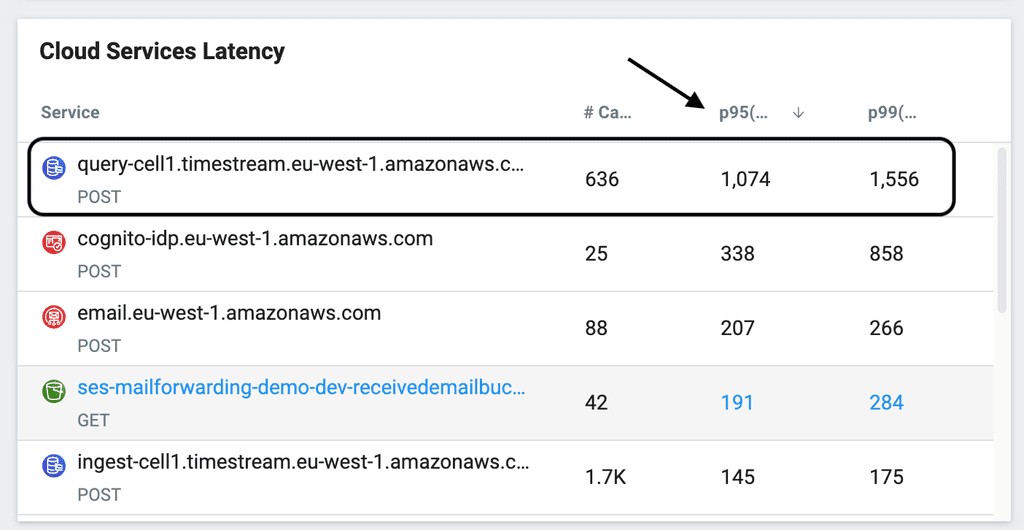
This kind of latency would not be acceptable in an OLTP (online transaction processing) workload. But I think it’s tolerable for OLAP (online analytics processing) workloads.
Overall, I’m happy with the choice of choosing Amazon Timestream over DynamoDB here.
Links
[1] How I built an affiliate tracking system in a weekend with serverless
[2] RudderStack, a warehouse-first data solution
[3] Amazon Timestream’s Date/Time functions
[4] My courses
[5] Amazon Timestream’s Aggregate functions
[6] Amazon Timestream’s pricing page
[7] Lumigo, the best observability tool for serverless applications
Related Posts


Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.