

Yan Cui
I help clients go faster for less using serverless technologies.

One under-appreciated aspect of designing an Event-Driven Architecture (EDA) is how much information you should include in your events. Do you send light events or rich events? Or perhaps you would send both, but in different circumstances?
In this post, let’s talk about the pros & cons of each and how they fit into my mental model of DDD and EDA.
Light events
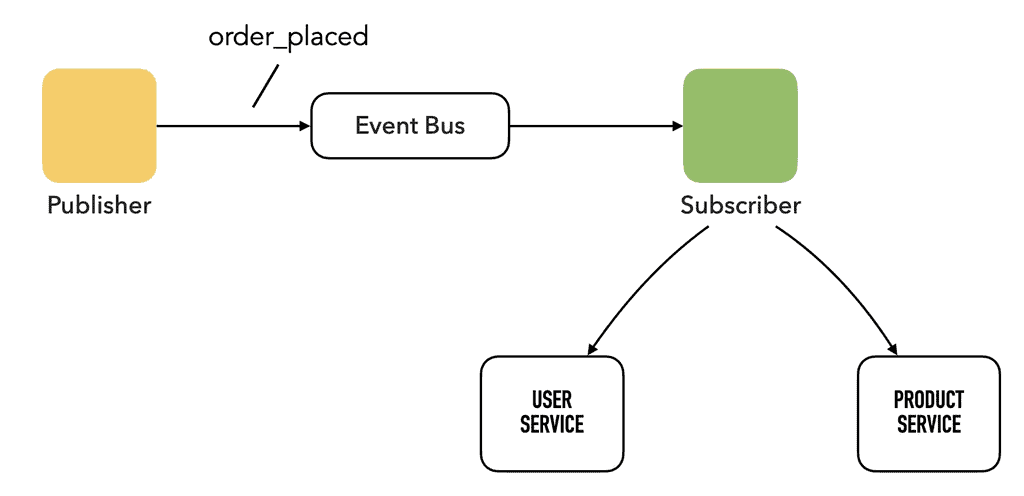
A light event (aka a “slim event”) typically contains information directly related to the event but only IDs to other related entities.
For example, an “order_placed” event might look like this:

It’s like looking at a row in a normalised relational table (2NF or 3NF).
Pros
These events are simple, and they don’t use much bandwidth and storage. And they might be more cost-efficient, too, because services such as EventBridge, SNS and SQS charge for requests based on the size of their payloads.

Cons
However, as they don’t contain all the relevant information, the event subscriber must fetch them from the relevant services and hydrate the entity IDs.
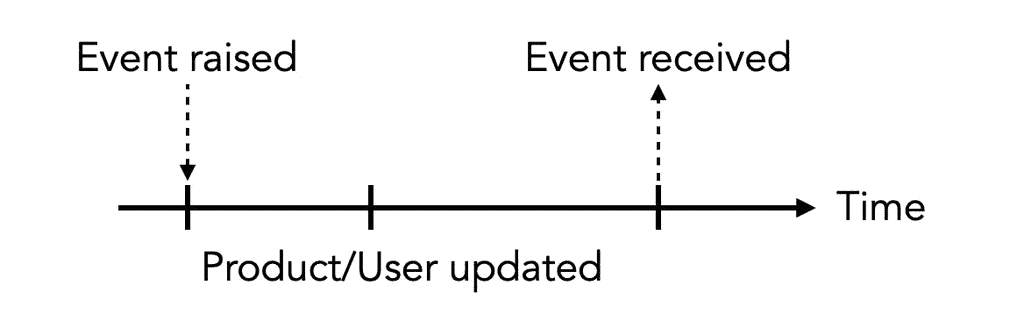
This allows race conditions to creep in where the user or product might be updated between when the event was raised and when the subscriber hydrates their IDs.
It also creates an additional load on those services, which will likely increase the cost of the system.
Furthermore, these inter-service calls require authentication and authorization. You also need to keep the API spec in sync so that when the services are updated, you need to update the subscriber accordingly.
You might also need circuit breakers to protect against problems such as thundering herd and retry storms.
In short, if event subscribers need additional information to proceed, they can bring in a whole load of extra complexities.

If multiple subscribers consume your events, these issues might be multiplied. For example, if you have ten subscribers for the “order_placed” event, and they all need to call the “user service” to hydrate the “user_id”. That’d be 10x the extra load on the “user service”!
Rich events
A rich event (aka “fat” events), on the other hand, will include as much information as possible.
Instead of including just the “user_id” and “product_id”, a rich event will include the expanded objects. The aforementioned “order_placed” event might look like this instead:

Pros
This reduces the need for subscribers to make extra calls. They likely have everything they need to process the event.
By reducing the need for those extra queries, we also reduce the amount of integration points between different services. Therefore, we reduce their coupling and make the system more efficient and less error-prone.
As we discussed before, the efficiency savings here will be multiplied by the number of subscribers and can be significant.
Because the subscribers have more data, we might allow more complex business logic and decision-making processes as well.
Cons
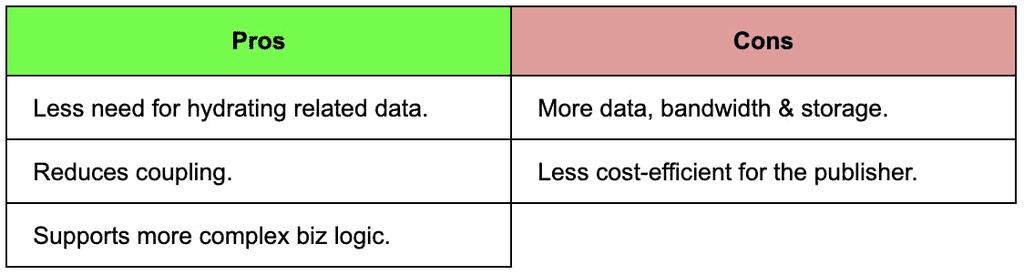
The obvious downside is that we need to send more data, which consumes more bandwidth and storage.
This has a cost impact as well. Especially if there are many related entities and/or they have a verbose set of data attributes.
Light vs. Rich events
Light events reduce the cost for the publisher but run the risk of increasing the cost and complexity for subscribers.
Rich events increase the cost for the publisher in the hope that it will reduce the cost for subscribers and result in a net saving. But many variables are at play – how many (if any) subscribers, what data the subscriber needs, and so on.
The choice ultimately boils down to “Does the event contain enough information for most subscribers to proceed?“
As much as possible, we want to give our subscribers exactly what they need. But that can be very difficult.
We don’t always know who the subscribers are and what they need.
And things change over time.
Domain vs. Integration events
In the context of DDD, there’s a difference between domain and integration events. I discussed their difference in this video [1], so I won’t go into details here.
The TL;DR is that domain events are significant events within a business domain and are used to drive domain-specific logic.
Integration events are used to communicate changes across different bounded contexts and maintain system-wide data consistency.
There is a natural affinity between domain events and light events and, likewise, between integration events and rich events.
Use Light events for Domain events
Within a domain, you might have several services working together to achieve some business capability. The services are likely owned and operated by one team.
Even though the services are decoupled through events and, they don’t (and shouldn’t!) know who’s listening for their events. You, as the engineer, should know which of your services are listening to which domain events within your domain.
As such, you can “right size” the payload to give the subscribers exactly what they need. You don’t have to adhere to the strict distinction between light vs. rich events either.
For example, if you know a subscriber needs the user information, then you can selectively expand it in the payload.

This is possible because you, as an engineer, own both the event publisher and subscriber. They are both within your domain, and the domain events are shared only within the domain.
Use Rich events for Integration events
On the other hand, integration events are shared across domains, and you likely do not know who is listening on the other side.
So it’s prudent to include as much information as you can because you don’t know what they’d need. This reduces the chance that they will need to call your services to fetch more data later.
(we talked about all the complications that come from these calls)
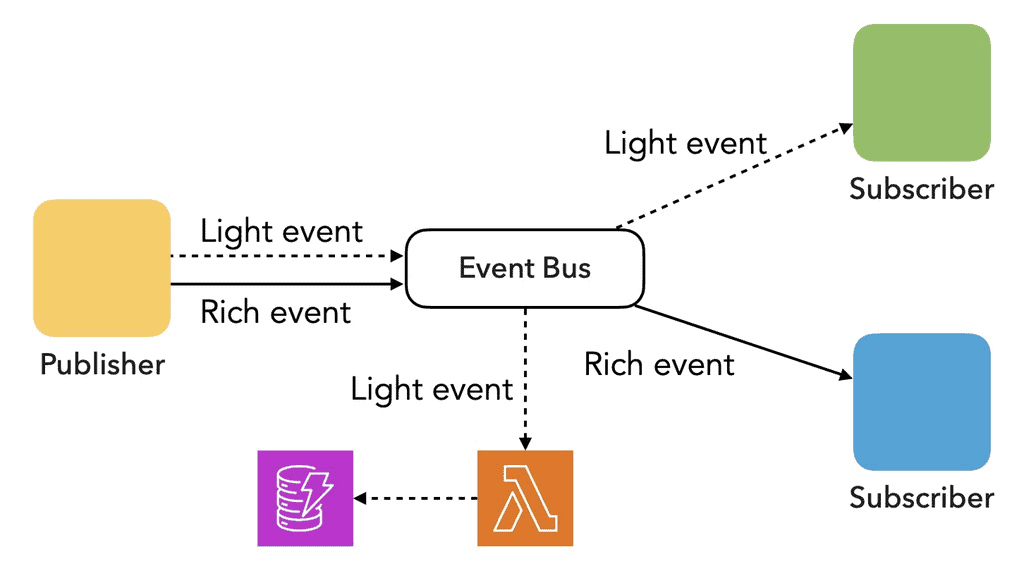
Send both, all the time
Another option is to send both.
We don’t know who’s listening and what they need, so we give them a light version of the event and a rich version.
If storage (and cost) is a concern, then we’d only store the light version of events and reconstruct the rich events on demand.
Links
[1] Domain vs. Integration events in DDD, why they matter and how they differ
Related Posts





Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.