

Yan Cui
I help clients go faster for less using serverless technologies.

re:Invent is almost upon us. A number of significant features have already been announced ahead of the main event.
Here is a list of the serverless-related announcements so far that you should know about.
API Gateway integration with ALB (without NLB)
Here’s the official announcement.
This is one of those things that everyone assumed just works, but never did. Until now, if you want to connect API Gateway to an ALB, you have to first go through an NLB.
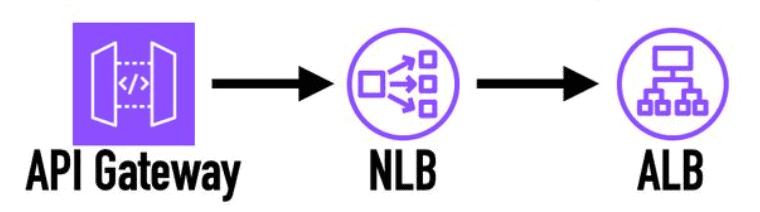
With the introduction of VPC Link v2, you can now skip the NLB and connect API Gateway directly with ALB.
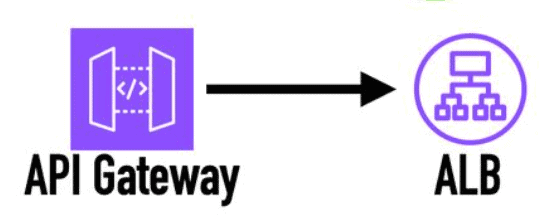
Fewer moving parts, less things that can break, less cost and a big win all around. It’s how it should work all along, and I’m glad we’re finally here!
API Gateway supports response streaming
Here’s the official announcement.
API Gateway now supports response streaming and works with Lambda’s response streaming capability.
Before this, if you wanted to do response streaming with Lambda, you had to use Function URLs and build Lambdaliths.
There are a couple of things worth noting:
1. Response streaming is only enabled for REST APIs, not HTTP APIs. It appears that the API Gateway team has abandoned the dream of HTTP APIs.
2. You can stream responses for up to 15 mins, which aligns with Lambda’s 15 mins timeout. You can exceed API Gateway’s 29s integration timeout without requesting a limit raise (which comes with reduced scalability).
2.1 But there is also an idle timeout of 5 mins for regional & private endpoints, and 30s for edge-optimised endpoints.
3. For each streamed response, the first 10mb has no bandwidth restriction. After that, the response is restricted to 2MB/s.
See the developer guide here for more details.
DynamoDB supports multi-attribute composite keys
Here’s the official announcement.
For me, this is the biggest pre:Invent announcement so far.
Multi-attribute GSI for DynamoDB is a huge win! No more building your own composite keys for GSIs and having to backfill every time you need a new composite key.
Now you just include the separate attributes in the key schema and add them to your queries, and voila!
Read the developer guide here for more details.
ALB adds built-in JWT verification
Here’s the official announcement.
Step Functions adds mocking support to its TestState API
Here’s the official announcement.
Step Function’s TestState API now supports mocking so you can test ASL in isolation.
The TestState API was useful at launch but it didn’t fit neatly into a typical development workflow where we tend to:
1. design and work on the state machine, ie. the ASL.
2. fill in the implementation of the required Lambda functions.
Without mocking, it was not possible to test the ASL in isolation. Which in practice, meant delaying discovery of problems in the state machine design until AFTER you’ve implemented everything.
Now we can test the ASL in isolation and make sure the various settings, including data transformations, are correct, before spending time on the Lambda functions (and then test them separately).
As I said previously, the TestState API is not a replacement for end-to-end tests where you exercise the state machine and execute it from beginning to end. But it’s a great way to test the individual parts in more detail, especially for execution paths that are difficult to reach on an end-to-end test (eg. error/timeout paths).
See the developer guide here on how to use the new mocking capability.
S3 supports Attribute-Based Access Control (ABAC)
Here’s the official announcement.
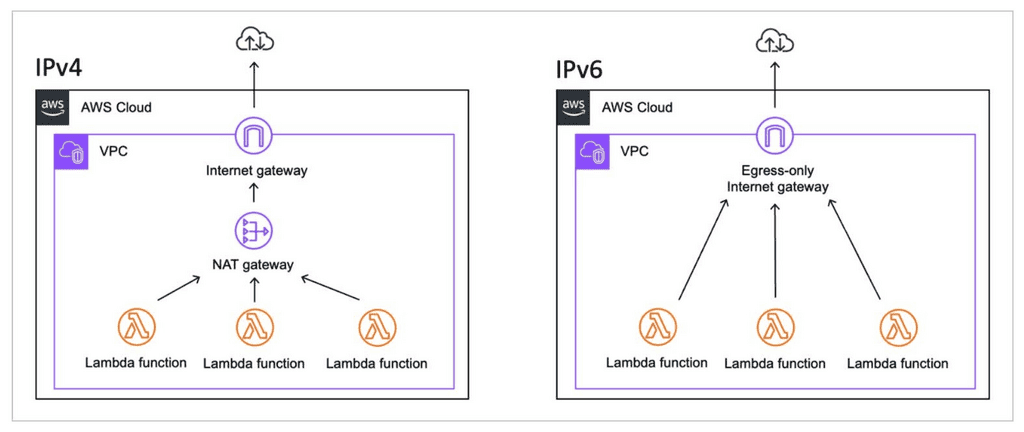
Lambda doesn’t need NAT Gateway anymore!
Here’s the official announcement.
With IPv6 support, Lambda functions inside a VPC no longer needs a NAT Gateway to access the internet (or other AWS services).
Instead, you can use the egress-only internet gateway, which only charges the standard EC2 data transfer cost and has no uptime cost.
It’s egress-only and does not allow attackers to reach your infrastructure from the internet.
This is another huge win and a great quality of life improvement.
Lambda supports native tenant isolation
Here’s the official announcement.
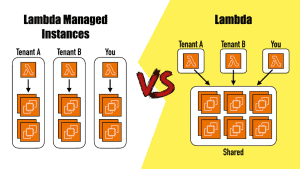
Lambda now accepts a “TenantId” attribute in the Invoke request.
By providing a tenant ID in the invocation, you ensure that each tenant’s requests are processed by a separate execution environment.
This is useful when you have strict isolation requirements. However, it’s only part of the solution. You still need to ensure data access patterns do not break tenant boundary, e.g. a tenant cannot access another tenant’s data.
I have written about multi-tenant design multiple times on this blog.
- How to secure multi-tenant applications with AppSync and Cognito
- Group-based auth with AppSync Lambda authoriser
- How to model hierarchical access with AppSync
- Fine-grained access control in API Gateway with Cognito groups & Lambda authorizer
This new capability compliments the approach I outlined in these posts.
However, it’s worth noting that it will significantly impact your concurrency needs.
You’d need higher account level concurrency limit to handle the same amount of request previously because you cannot reuse execution environments across multiple tenants.
This will also impact your ability to scale quickly during a large spike.
A Lambda function can scale from 0 to 1000 concurrent executions instantly. Thereafter, it can add a further 1000 concurrent executions every 10 seconds.
If the execution environments are tenant specific, then, during a large scaling event, you will need many more concurrent executions to serve the same amount of requests.
It’s an interesting launch, but most of you don’t need to use it.
Lastly, Anton Aleksandrov has an example in CDK on how to integrate API Gateway with Lambda to pass the tenant ID (resolved by a Lambda authorizer) in the proxy request to Lambda.
You should never accept tenant ID from the caller!
Lambda adds provisioned mode for SQS ESM
Here’s the official announcement.
If you have a very spiky load and need to process millions of SQS messages quickly, you can now have up to 20,000 ESM event pollers & auto-scale the no. of pollers at 1,000 per minute.
This new provisioned mode is useful for some specific use cases. For example, if you have a very spiky traffic and strict processing time requirement.
It comes at a price of ~$6.66 per poller per month (min 2 pollers).
For most of us, the free ESM SQS pollers is more than sufficient and there’s no need to pay extra.
But this new capability is great for addressing edge cases.
Lambda ups max payload size for async invocations to 1MB
Here’s the official announcement.
But don’t get too excited just yet!
This is only useful when you trigger an async invocation via the Lambda Invoke API (by setting InvocationType to Event). Because the max message size for both SNS and EventBridge (the most common async event sources for Lambda) is still 256kb.
SQS raised its max payload size to 1MB a while back, but SQS triggers Lambda via ESM and is not impacted by this announcement.
Also, payload size beyond 256kb are charged as 1 additional request for each 64kb chunk. If you send a 1MB payload, then it counts as 13 invocation requests:
- 256kb as 1 request
- (1024 – 256) / 64 = 12 additional requests
Lambda supports Python 3.14
Here’s the official announcement.
Lambda’s Rust support goes GA
Here’s the official announcement.
This one has more hype than substance.
There are no new capabilities, the only thing that changed here is that the lambda_runtime crate was marked as GA.
CloudFront introduces flat rate price plan
Here’s the official announcement.
You can now get CloudFront and a bunch of associated services (WAF, Route53, CloudFront functions, logging, etc.) for a flat monthly fee.
Pay-per-use pricing removes waste, but teams often dislike it because it’s difficult to budget and it can result in sudden spikes, whether it’s from a successful launch or a DOS attack.
This sounds tempting, but there are some nuances you must consider.
- Lambda@Edge functions are not supported on the flat-rate plan, only CloudFront functions are.
- When you go over the usage quota for your tier, you can be throttled.
So the trade-off looks like this:
- Below quota -> you waste money.
- Above quota -> you risk throttling.
This is fine for personal projects or non-critical apps where downtime is not costly and you care more avoiding a nasty billing surprise.
But it’s a bad deal if availability and elasticity matter more to you than certainty around budget, which describes most business critical systems.
Also, the free tier in the flat rate plan gives you only 100GB of free data transfer for CloudFront. Whereas the free tier for the pay-per-use plan gives you 1TB of free data transfer.
So if you only care about CloudFront, and not the related services, then you might be better off sticking with the pay-per-use plan.
What’s most interesting about this launch is that, it’s the closest thing AWS has offered to a direct spending cap. Here are my thoughts on the pros & cons of a spending cap.
Wrap up
There has been over 150 announcements in the last few weeks! These are just the ones I find most interesting and relevant to serverless.
I’m excited for re:Invent this year and hoping to see a couple of big announcements around Lambda and Step Functions. It’s a shame I won’t be there in person this year, but I wish everyone a good time in Vegas next week!
Related Posts



Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.