

Yan Cui
I help clients go faster for less using serverless technologies.

AWS launched Lambda MicroVMs this week, and it solves the very timely problem of “how to create sandboxed environments so we can safely run AI-generated or user-supplied code?”
It offers a unique combination of properties amongst AWS’s compute services:
- Strong isolation guarantees.
- Fast boot time.
- Stateful executions.
and is suitable for multi-tenant applications that require per-user or per-session execution environments without a shared kernel.
The Problem
Imagine you’re building a product where users or AI agents need to execute arbitrary code. A coding assistant, an AI notebook, or perhaps a platform where users can run custom scripts.
The requirements are simple enough, but none of the existing compute services is an exact fit:
- VMs provide strong isolation, but take minutes to boot.
- Containers have a fast boot time, but the shared kernel makes it difficult to create truly sandboxed environments.
- Lambda functions have great isolation (thanks to Firecracker MicroVMs), but their 15-minute max timeout is not suited for long-running environments.
So teams end up duct-taping solutions together. EC2 with a custom lifecycle manager, ECS with heavy isolation config, or running Firecracker directly on bare metal.
Meanwhile, Lambda already has the right isolation guarantee, but its invocation-based model is a showstopper.
What Lambda MicroVMs changes
Lambda MicroVMs combines important properties from each of the options above:
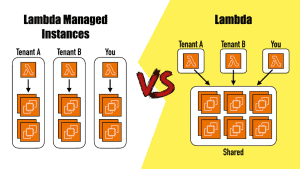
- VM-level isolation via Firecracker: no shared kernel between execution environments, same as Lambda functions.
- Fast startup (in seconds) from pre-initialized snapshots. The same technology behind Lambda SnapStart is used here.
- Stateful sessions: memory and disk persist for up to 8 hours, with automatic suspend/resume when idle.
The use cases are pretty clear – coding assistants that need to run AI-generated code safely, interactive AI notebooks, agent sandboxes, vulnerability scanners, etc.
A completely different mental model
Lambda MicroVMs isn’t request/response at all.
Instead, you spin up a persistent VM per user or session, and it gets a dedicated HTTPS endpoint.
Clients connect over HTTP/2, gRPC or WebSockets. Every inbound connection is authenticated using bearer tokens (which you can generate using the CreateMicrovmAuthToken API).
The VM automatically suspends when idle (no compute charges) and resumes when traffic arrives. The practical unit is a session, not an invocation.
Scaling is different too.
Vertical scaling within a MicroVM is automated. It can burst to 4× its configured baseline CPU and memory.
But there’s no automatic horizontal scaling. You call “run-microvm” to create new environments as needed. Your application manages the fleet – which VM belongs to which tenant, when to spin up, when to clean up, etc. That’s the real engineering work you don’t have with Lambda functions.
Things to know
Aidan Steele did some hands-on exploration on launch day and gave us some useful details not in the launch posts (source):
Shell access is first-class. “/dev/ptmx” (pseudo-terminal) is supported, and there’s a CreateMicrovmShellAuthToken API to connect directly to a shell inside the VM. No reverse-shell workarounds needed. This is what tools like Claude Code and OpenCode use to give you a real terminal experience. And it means you can build the same thing for your users.
Docker works inside MicroVMs. Full OS capabilities are available, including running containers inside your MicroVM. One gotcha: all outbound UDP is blocked by default, which breaks DNS inside containers. See Aidan’s post for the fix.
Caveats
- ARM64 only at launch.
- Only five regions: N. Virginia, Ohio, Oregon, Ireland and Tokyo.
- Pricing is per vCPU-second + per Memory GB-second + snapshot read/write charges. This is closer to Fargate than Lambda.
- You’re billed per second, not per millisecond (as with Lambda functions). Again, this is closer to Fargate than Lambda.
Compared with AgentCore Runtime
If you’re building AI agents, you might have also looked at AgentCore Runtime, a managed platform for running agent workloads.
Both run on Firecracker MicroVMs and support up to 8 hours of total runtime. Both now have PTY/shell access (AgentCore added the InvokeAgentRuntimeCommandShell API in early June).
They look similar on paper, but I think the difference lies in the level of abstraction and who’s running the code.
AgentCore is a managed agent platform. You deploy your agent code (LangGraph, CrewAI, Strands, whatever), and AWS manages the fleet. This includes routing sessions to VMs, scaling and tearing down idle sessions. It has built-in inbound/outbound auth, MCP and A2A protocol support, versioning, and endpoints. Your users talk to your agent, and you don’t even think about VMs.
Lambda MicroVMs, on the other hand, is a low-level compute primitive. You call “run-microvm” to create environments, track which VM belongs to which tenant, and decide when to clean up, etc. There is no fleet management, no built-in auth, no protocol support.
There are overlaps in capabilities. For example, AgentCore Runtime also recently added support for interactive shells. But ultimately, I think they’re designed for different use cases:
- AgentCore Runtime – run my agent so users can talk to it.
- Lambda MicroVMs – give each user their own isolated VM so they can run arbitrary code in it.
As such, AgentCore Runtime’s execution environment is more locked down, whereas Lambda MicroVMs gives you full rein of the VM.
A good analogy is that AgentCore Runtime is to Lambda MicroVMs what Fargate is to EC2. Fargate runs your container in a microVM but constrains what you can do within it. EC2 gives you the full machine.
AgentCore gives you managed container hosting in a microVM. Lambda MicroVMs gives you the VM itself. The isolation boundary is the same (Firecracker), but what you can do inside it is not.
Links
- Announcement
- Launch blog post
- Developer guide
- API reference
- Pricing
- Aidan Steele’s hands-on notes
- Bedrock AgentCore Runtime
Related Posts
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.