
Yan Cui
I help clients go faster for less using serverless technologies.

Serverless architectures are microservices by default, you need correlation IDs to help debug issues that spans across multiple functions, and possibly different event source types – asynchronous, synchronous and streams.
This is the last of a 3-part mini series on managing your AWS Lambda logs.
If you haven’t read part 1 yet, please give it a read now. We’ll be building on top of the basic infrastructure of shipping logs from CloudWatch Logs detailed in that post.
part 1 : centralise logging
part 2: tips and tricks
Why correlation IDs?
As your architecture becomes more complex, many services have to work together in order to deliver the features your users want.

When everything works, it’s like watching an orchestra, lots of small pieces all acting independently whilst at the same time collaborating to form a whole that’s greater than the sum of its parts.
However, when things don’t work, it’s a pain in the ass to debug. Finding that one clue is like finding needle in the haystack as there are so many moving parts, and they’re all constantly moving.
Imagine you’re an engineer at Twitter and trying to debug why a user’s tweet was not delivered to one of his followers’ timeline.
“Let me cross reference the logs from hundreds of services and find the logs that mention the author’s user ID, the tweet ID, or the recipient’s user ID, and put together a story of how the tweet flowed through our system and why it wasn’t delivered to the recipient’s timeline.”
“What about logs that don’t explicitly mention those fields?”
“mm… let me get back to you on that…”
Needle in the haystack.

This is the problem that correlation IDs solve in the microservice world – to tag every log message with the relevant context so that it’s easy to find them later on.
Aside from common IDs such as user ID, order ID, tweet ID, etc. you might also want to include the X-Ray trace ID in every log message. That way, if you’re using X-Ray with Lambda then you can use it to quickly load up the relevant trace in the X-Ray console.

Also, if you’re going to add a bunch of correlation IDs to every log message then you should consider switching to JSON. Then you need to update the ship-logs function we introduced in part 1 to handle log messages that are formatted as JSON.
Enable debug logging on entire call chain
Another common problem people run into, is that by the time we realise there’s a problem in production we find out that the crucial piece of information we need to debug the problem is logged as DEBUG, and we disable DEBUG logs in production because they’re too noisy.
“Darn it, now we have to enable debug logging and redeploy all these services! What a pain!”
“Don’t forget to disable debug logging and redeploy them, after you’ve found the problem ;-)”
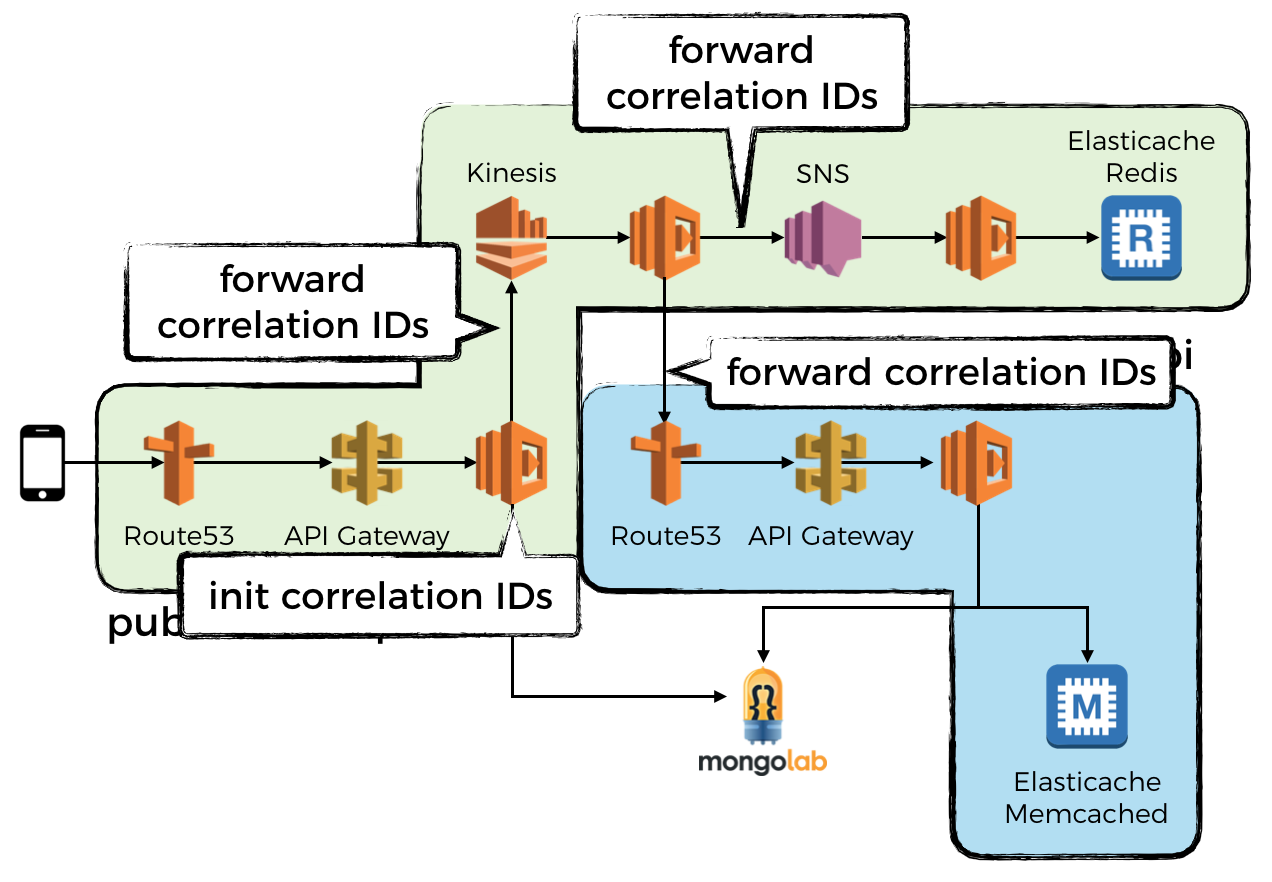
Fortunately it doesn’t have to be a catch-22 situation. You can enable DEBUG logging on the entire call chain by:
- make the decision to enable DEBUG logging (for say, 5% of all requests) at the edge service
- pass the decision on all outward requests alongside the correlation IDs
- on receiving the request from the edge service, possibly through async event sources such as SNS, the intermediate services will capture this decision and turn on DEBUG logging if asked to do so
- the intermediate services will also pass that decision on all outward requests alongside the correlation IDs
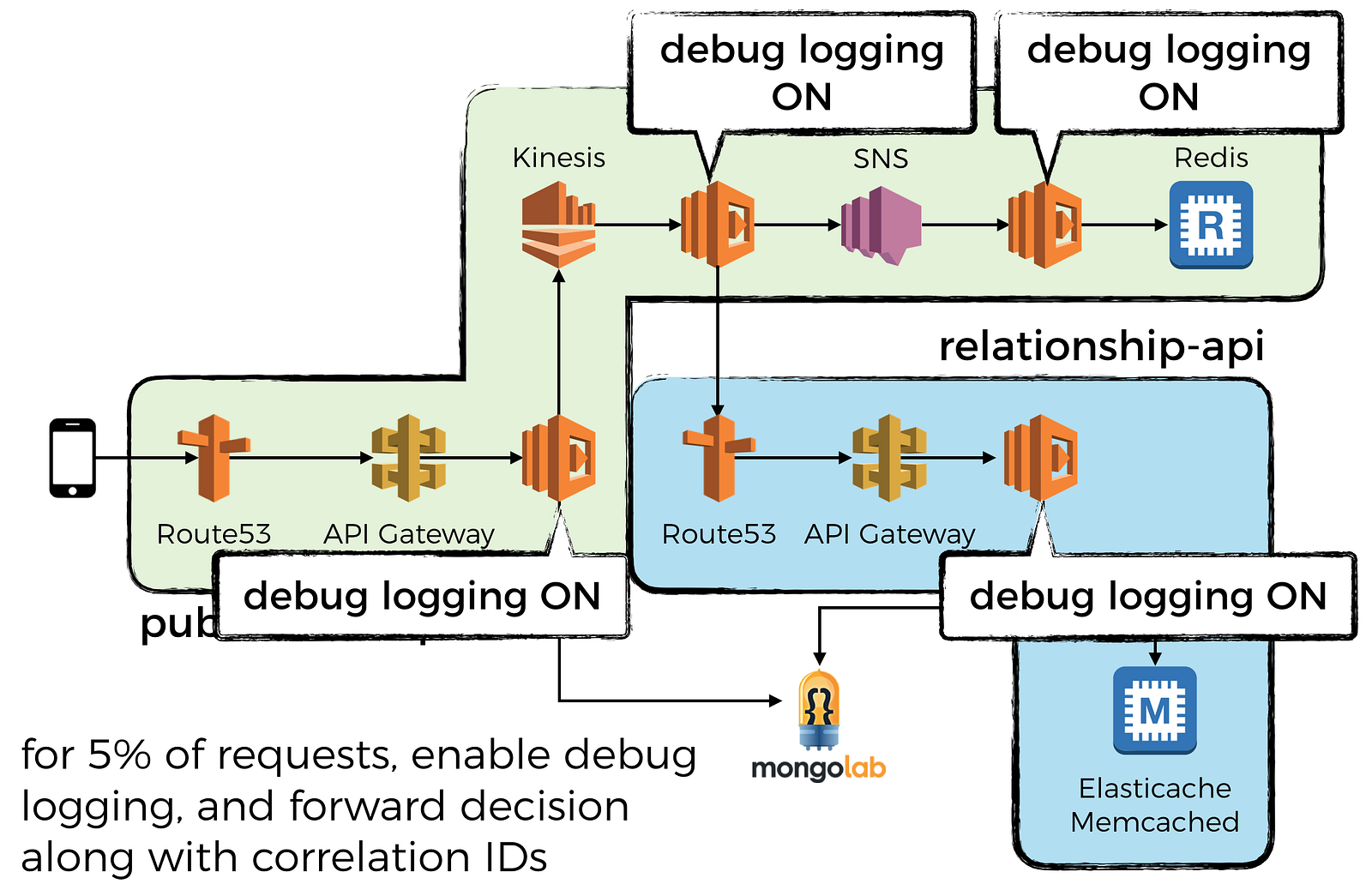
Capture and forward correlation IDs
With that out of the way, let’s dive into some code to see how you can actually make it work. If you want to follow along, then the code is available in this repo, and the architecture of the demo project looks like this:
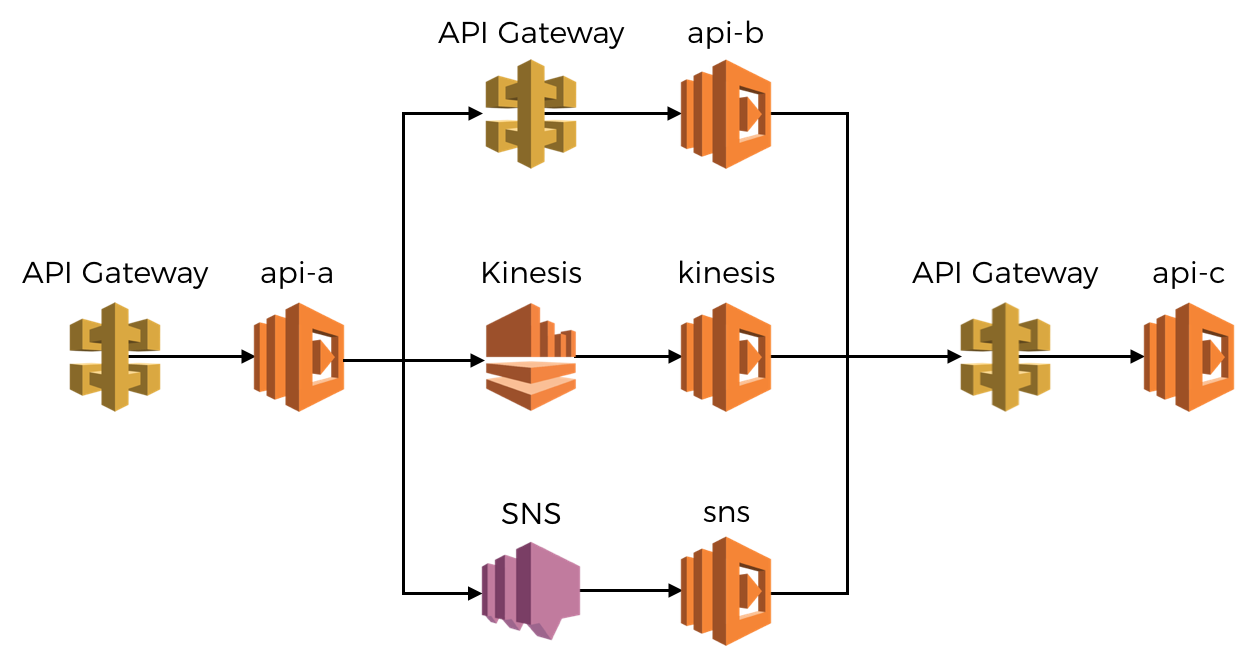
We can take advantage of the fact that concurrency is now managed by the platform, which means we can safely use global variables to store contextual information relevant for the current invocation.
In the handler function we can capture incoming correlation IDs in global variables, and then include them in log messages, as well as any outgoing messages/HTTP requests/events, etc.
To abstract away the implementation details, let’s create a requestContextmodule that makes it easy to fetch and update these context data:
'use strict';
let clearAll = () => global.CONTEXT = undefined;
let replaceAllWith = ctx => global.CONTEXT = ctx;
let set = (key, value) => {
if (!key.startsWith("x-correlation-")) {
key = "x-correlation-" + key;
}
if (!global.CONTEXT) {
global.CONTEXT = {};
}
global.CONTEXT[key] = value;
};
let get = () => global.CONTEXT || {};
module.exports = {
clearAll,
replaceAllWith,
set: set,
get: get
};
And then add a log module which:
- disables DEBUG logging by default
- enables DEBUG logging if explicitly overriden via environment variables or a
Debug-Log-Enabledfield was captured in the incoming request alongside other correlation IDs - logs messages as JSON
'use strict';
const reqContext = require('./requestContext');
function getContext () {
// note: this is a shallow copy
return Object.assign({}, reqContext.get());
}
function isDebugEnabled () {
// disable debug logging by default, but allow override via env variables
// or if enabled via forwarded request context
return process.env.DEBUG_LOG === 'true' || reqContext.get()["Debug-Log-Enabled"] === 'true';
}
function log (level, msg, params) {
if (level === 'DEBUG' && !isDebugEnabled()) {
return;
}
let logMsg = getContext();
logMsg.level = level;
logMsg.message = msg;
logMsg.params = params;
console.log(JSON.stringify(logMsg));
}
module.exports.debug = (msg, params) => log('DEBUG', msg, params);
module.exports.info = (msg, params) => log('INFO', msg, params);
module.exports.warn = (msg, params) => log('WARN', msg, params);
module.exports.error = (msg, params) => log('ERROR', msg, params);
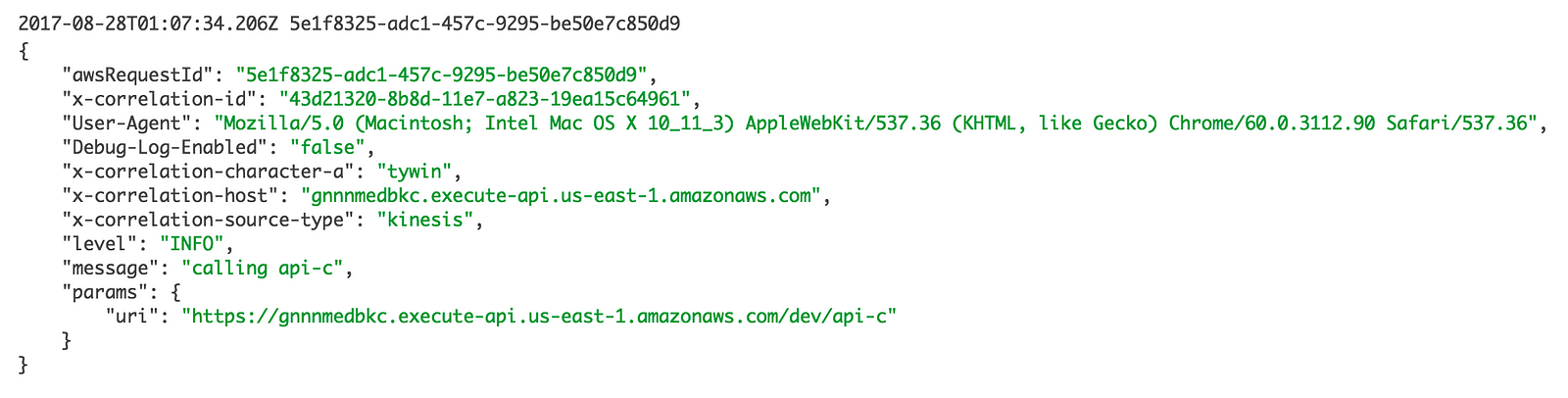
Once we start capturing correlation IDs, our log messages would look something like this:

Notice that I have also captured the User-Agent from the incoming request, as well as the decision to not enable DEBUG logging.
Now let’s see how we can capture and forward correlation IDs through API Gateway and outgoing HTTP requests.
API Gateway
You can capture and pass along correlation IDs via HTTP headers. The trick is making sure that everyone in the team follows the same conventions.
To standardise these conventions (what to name headers that are correlation IDs, etc.) you can provide a factory function that your developers can use to create API handlers. Something like this perhaps:
'use strict';
const co = require('co');
const log = require('./log');
const reqContext = require('./requestContext');
function setRequestContext (event, context) {
// extracts correlation IDs, User-Agent, etc. from HTTP headers
// and stores them in the requestContext
};
function OK (result) {
// return 200 response
};
function createApiHandler (f) {
return co.wrap(function* (event, context, cb) {
console.log(JSON.stringify(event));
reqContext.clearAll();
try {
setRequestContext(event, context);
} catch (err) {
log.warn(`couldn't set current request context: ${err}`, err.stack);
}
try {
let result = yield Promise.resolve(f(event, context));
result = result || {};
log.info('SUCCESS', JSON.stringify(result));
cb(null, OK(result));
} catch (err) {
log.error("Failed to process request", err);
cb(err);
}
});
}
module.exports = createApiHandler;
When you need to implement another HTTP endpoint, pass your handler code to this factory function. Now, with minimal change, all your logs will have the captured correlation IDs (as well as User-Agent, whether to enable debug logging, etc.).
The api-a function in our earlier architecture looks something like this:
'use strict';
const co = require('co');
const log = require('../lib/log');
const http = require('../lib/http');
const apiHandler = require('../lib/apiHandler');
const reqContext = require('../lib/requestContext');
module.exports.handler = apiHandler(
co.wrap(function* (event, context) {
reqContext.set("character-a", "tywin");
log.debug("this is a DEBUG log");
log.info("this is an INFO log");
log.warn("this is a WARNING log");
log.error("this is an ERROR log");
// do a bunch of stuff, like calling another HTTP endpoint
let host = event.headers.Host;
reqContext.set("host", host);
let uri = `https://${host}/dev/api-b`;
log.info("calling api-b", { uri });
let reply = yield http({
uri : uri,
method : 'GET'
});
...
return {
message: 'A Lannister always pays his debts'
};
})
);
Since this is the API on the edge, so it initialises the x-correlation-id using the AWS Request ID for its invocation. This, along with several other pieces of contextual information is recorded with every log message.
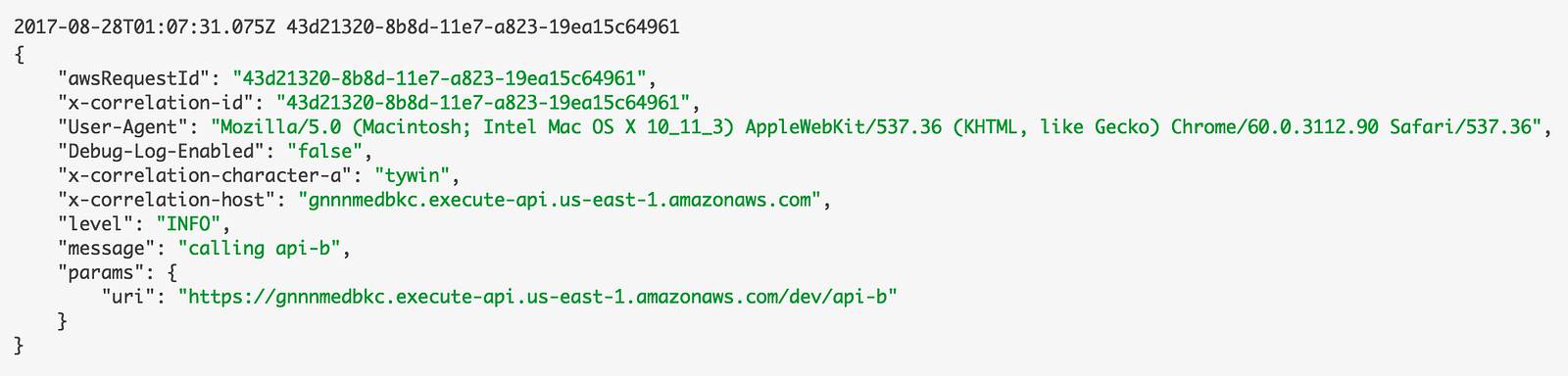
By adding a custom HTTP module like this one, you can also make it easy to include these contextual information in outgoing HTTP requests. Encapsulating these conventions in an easy-to-use library also helps you standardise the approach across your team.
In the api-a function above, we made a HTTP request to the api-bendpoint. Looking in the logs, you can see the aforementioned contextual information has been passed along.

In this case, we also have the User-Agent from the original user-initiated request to api-a. This is useful because when I look at the logs for intermediate services, I often miss the context of what platform the user is using which makes it harder to correlate the information I gather from the logs to the symptoms the user describes in their bug reports.
When the api-b function (see here) makes its own outbound HTTP request to api-c it’ll pass along all of these contextual information plus anything we add in the api-b function itself.
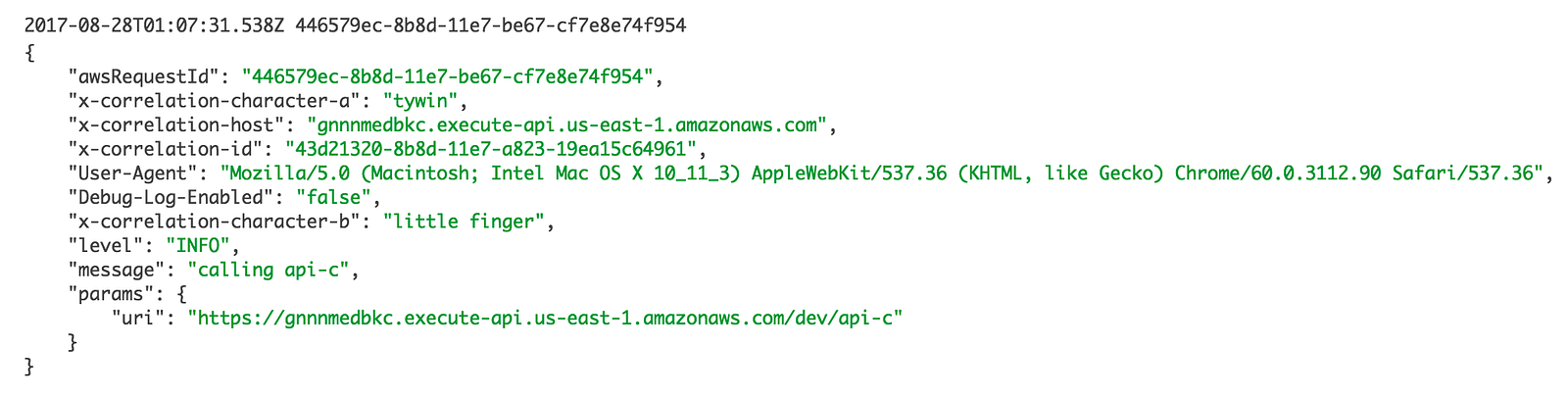
When you see the corresponding log message in api-c’s logs, you’ll see all the context from both api-a and api-b.
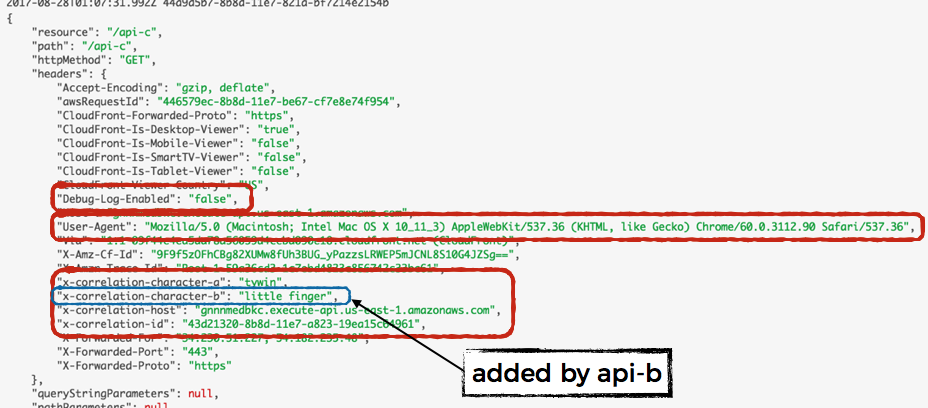
SNS
To capture and forward correlation IDs through SNS messages, you can use message attributes.
In the api-a function above, we also published a message to SNS (omitted from the code snippet above) with a custom sns module which includes the captured correlation IDs as message attributes, see below.
'use strict';
const co = require('co');
const Promise = require('bluebird');
const AWS = require('aws-sdk');
const SNS = Promise.promisifyAll(new AWS.SNS());
const log = require('./log');
const requestContext = require('./requestContext');
function getMessageAttributes() {
let attributes = {};
let ctx = requestContext.get();
for (let key in ctx) {
attributes[key] = {
DataType: 'String',
StringValue: ctx[key]
};
}
return attributes;
}
let publish = co.wrap(function* (topicArn, msg) {
let req = {
Message: msg,
MessageAttributes: getMessageAttributes(),
TopicArn: topicArn
};
yield SNS.publishAsync(req);
});
module.exports = {
publish
};
When this SNS message is delivered to a Lambda function, you can see the correlation IDs in the MessageAttributes field of the SNS event.
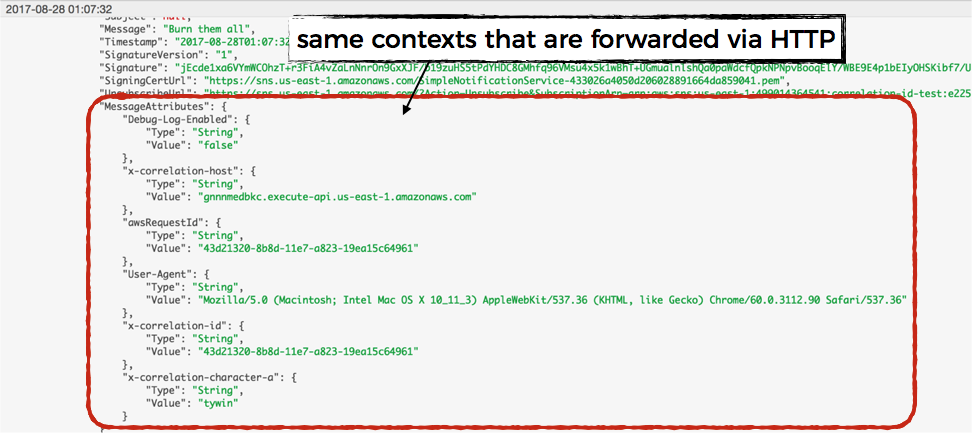
Let’s create a snsHandler factory function to standardise the process of capturing incoming correlation IDs via SNS message attributes.
'use strict';
const co = require('co');
const log = require('./log');
const reqContext = require('./requestContext');
function setRequestContext (event, context) {
// extra correlation-ids, User-Agent, etc. from the message attribute and
// populate the requestContext with them
};
function createSnsHandler (f) {
return co.wrap(function* (event, context, cb) {
console.log(JSON.stringify(event));
reqContext.clearAll();
try {
setRequestContext(event, context);
} catch (err) {
log.warn(`couldn't set current request context: ${err}`, err.stack);
}
try {
let result = yield Promise.resolve(f(event, context));
result = result || {};
log.info('SUCCESS', JSON.stringify(result));
cb(null, JSON.stringify(result));
} catch (err) {
log.error("Failed to process request", err);
cb(err);
}
});
}
module.exports = createSnsHandler;
We can use this factory function to quickly create SNS handler functions. The log messages from these handler functions will have access to the captured correlation IDs. If you use the aforementioned custom httpmodule to make outgoing HTTP requests then they’ll be included as HTTP headers automatically.
For instance, the following SNS handler function would capture incoming correlation IDs, include them in log messages, and pass them on when making a HTTP request to api-c (see architecture diagram).
'use strict';
const co = require('co');
const log = require('../lib/log');
const snsHandler = require('../lib/snsHandler');
const http = require('../lib/http');
const reqContext = require('../lib/requestContext');
module.exports.handler = snsHandler(
co.wrap(function* (event, context) {
reqContext.set("source-type", "sns");
log.debug("this is a DEBUG log");
log.info("this is an INFO log");
log.warn("this is a WARNING log");
log.error("this is an ERROR log");
let host = reqContext.get()["x-correlation-host"];
if (host) {
let uri = `https://${host}/dev/api-c`;
log.info("calling api-c", { uri });
let reply = yield http({
uri : uri,
method : 'GET'
});
log.info(reply);
}
})
);
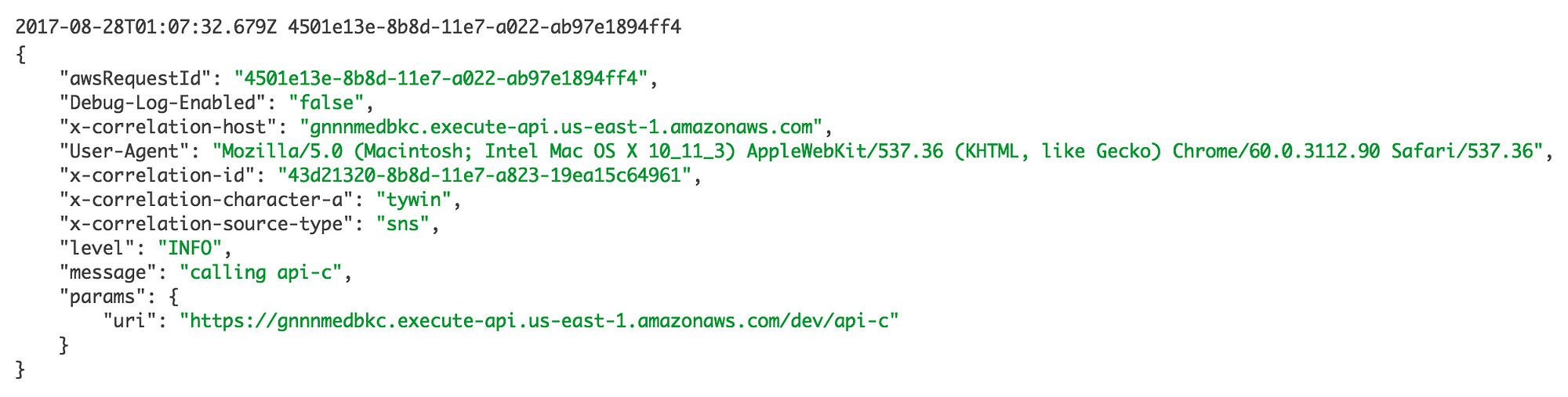

Kinesis Streams
Unfortunately, with Kinesis and DynamoDB Streams, there’s no way to tag additional information with the payload. Instead, in order to pass correlation IDs along, we’d have to modify the actual payload itself.
Let’s create a kinesis module for sending events to a Kinesis stream, so that we can insert a __context field to the payload to carry the correlation IDs.
'use strict';
const co = require('co');
const Promise = require('bluebird');
const AWS = require('aws-sdk');
const Kinesis = Promise.promisifyAll(new AWS.Kinesis());
const log = require('./log');
const requestContext = require('./requestContext');
let putRecord = co.wrap(function* (streamName, partitionKey, record) {
// save the request context as part of the payload
let ctx = requestContext.get();
record.__context = ctx;
let data = JSON.stringify(record);
let req = {
Data: data,
PartitionKey: partitionKey,
StreamName: streamName
};
yield Kinesis.putRecordAsync(req);
});
module.exports = {
putRecord
};
On the receiving end, we can take it out, use it to set the current requestContext, and delete this __context field before passing it on to the Kinesis handler function for processing. The sender and receiver functions won’t even notice we modified the payload.
Wait, there’s one more problem – our Lambda function will receive a batch of Kinesis records, each with its own context. How will we consolidate that?
The simplest way is to force the handler function to process records one at a time. That’s what we’ve done in the kinesisHandler factory function here.
'use strict';
const co = require('co');
const log = require('./log');
const reqContext = require('./requestContext');
function getEvents (records) {
// parse the Kinesis records (base64) as JSON
}
function setRequestContext (record, context) {
let ctx = record.__context;
delete record.__context;
ctx.awsRequestId = context.awsRequestId;
reqContext.replaceAllWith(ctx);
};
function createKinesisHandler (f) {
return co.wrap(function* (event, context, cb) {
console.log(JSON.stringify(event));
try {
let records = getEvents(event.Records);
// the problem Kinesis events present is that we have to include the
// correlation IDs as part of the payload of a record, but we receive
// multiple records on an invocation - so to apply the correct set of
// correlation IDs in the logs we have to force the handling code to
// process them one at time so that we can swap out the correlation IDs
for (let record of records) {
reqContext.clearAll();
try {
setRequestContext(record, context);
} catch (err) {
log.warn(`couldn't set current request context: ${err}`, err.stack);
}
yield Promise.resolve(f(record, context));
}
log.info('SUCCESS');
cb(null, 'SUCCESS');
} catch (err) {
log.error("Failed to process request", err);
cb(err);
}
});
}
module.exports = createKinesisHandler;
The handler function (created with the kinesisHandler factory function) would process one record at at time, and won’t have to worry about managing the request context. All of its log messages would have the right correlation IDs, and outgoing HTTP requests, SNS messages and Kinesis events would also pass those correlation IDs along.
// the KinesisHandler abstraction takes in a function that processes one
// record at a time so to allow us to inject the correlation IDs that
// corresponds to each record
module.exports.handler = kinesisHandler(
co.wrap(function* (record, context) {
reqContext.set("source-type", "kinesis");
let host = reqContext.get()["x-correlation-host"];
if (host) {
let uri = `https://${host}/dev/api-c`;
log.info("calling api-c", { uri });
let reply = yield http({
uri : uri,
method : 'GET'
});
log.info(reply);
}
})
);
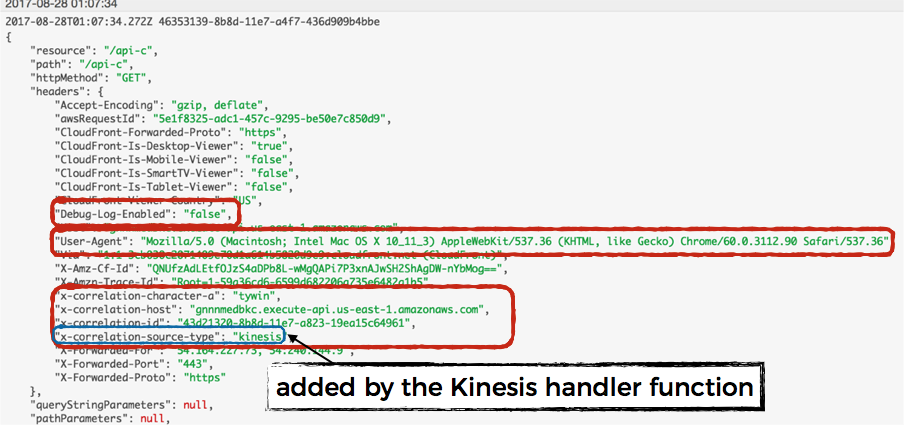
This approach is simple, developers working on Kinesis handler functions won’t have to worry about the implementation details of how correlation IDs are captured and passed along, and things “just work”.
However, it also removes the opportunity to optimize by processing all the records in a batch. Perhaps your handler function has to persist the events to a persistence store that’s better suited for storing large payloads rather than lots of small ones.
This simple approach is not the right fit for every situation, an alternative would be to leave the __context field on the Kinesis records and let the handler function deal with them as it sees fit. In which case you would also need to update the shared libraries – the log, http, sns and kinesismodules we have talked about so far – to give the caller to option to pass in a requestContext as override.
This way, the handler function can process the Kinesis records in a batch. Where it needs to log or make a network call in the context of a specific record, it can extract and pass the request context along as need be.
The End
That’s it, folks. A blueprint for how to capture and forward correlation IDs through 3 of the most commonly used event sources for Lambda.
Here’s an annotated version of the architecture diagram earlier, showing the flow of data as they’re captured and forwarded from one invocation to another, through HTTP headers, message attributes, Kinesis record data.
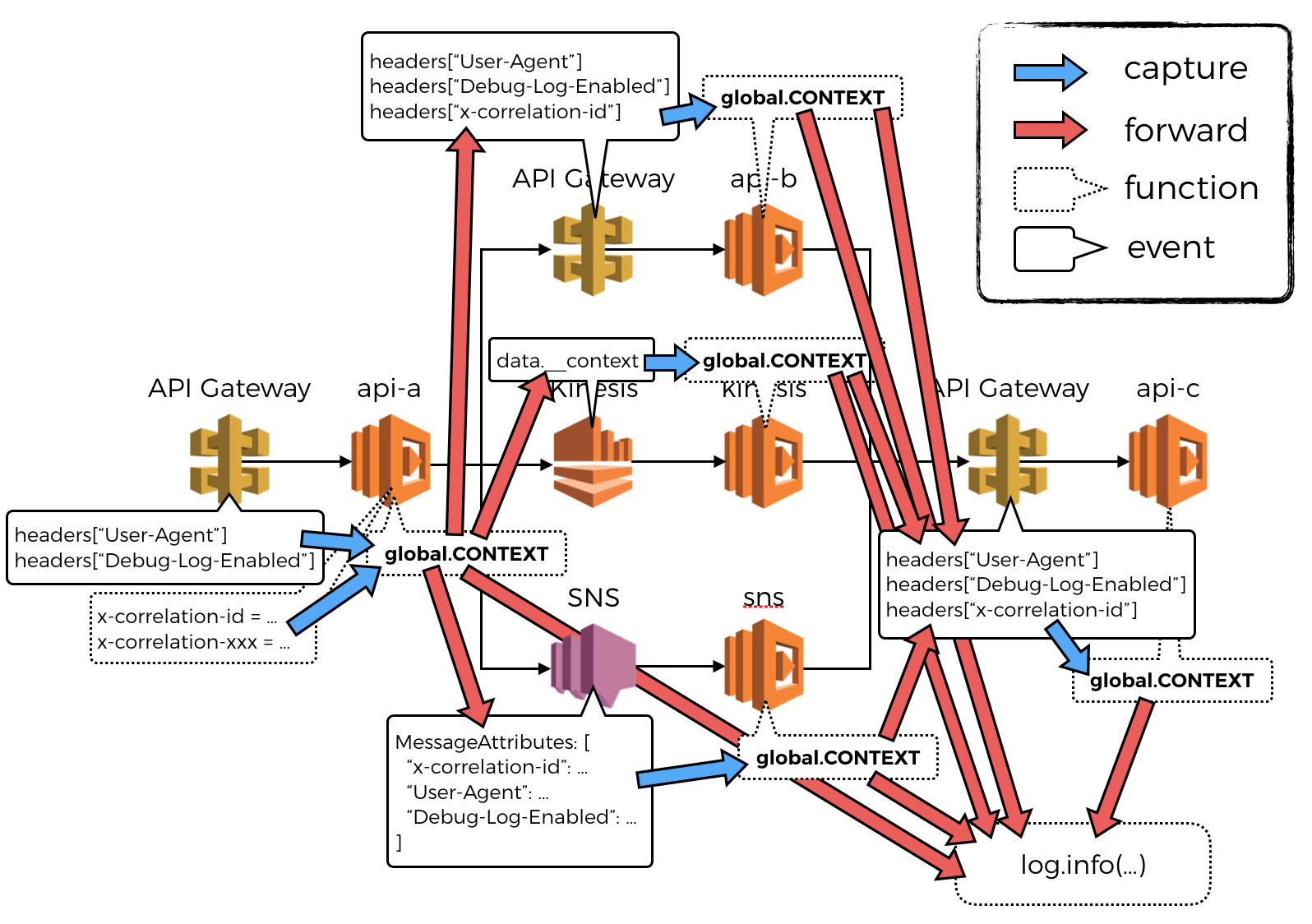
You can find a deployable version of the code you have seen in this post in this repo. It’s intended for demo sessions in my O’Reilly course detailed below, so documentation is seriously lacking at the moment, but hopefully this post gives you a decent idea of how the project is held together.
Other event sources
There are plenty of event sources that we didn’t cover in this post.
It’s not possible to pass correlation IDs through every event source, as some do not originate from your system – eg. CloudWatch Events that are triggered by API calls made by AWS service.
And it might be hard to pass correlation IDs through, say, DynamoDB Streams – the only way (that I can think of) for it to work is to include the correlation IDs as fields in the row (which, might not be such a bad idea but it does have cost implications).
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Hi, Thanks for the 3 articles, great stuff !
One thing I don’t really get. You are using global.CONTEXT but this global variable would be erased by a concurrent call from another client calling the lambda (and changing the user-agent for example) ? As the lambda instance can be shared between several calls ? How does it work ?
Concurrency has moved up to the platform, which means one Lambda invocation = one client request = one container, hence global.CONTEXT is safe to use. The container running your Lambda function is used between several calls for optimization, but not concurrently. I suspect API Gateway uses a backlog to manage concurrent requests, and decides to spawn new invocations if requests stay in backlog for longer than some threshold.