

Yan Cui
I help clients go faster for less using serverless technologies.

“Guys, we’re doing pagination wrong…”
These are the words that I had to mutter quite a few times in my career, at the dissatisfaction of how pagination had been implemented on several projects.
Still, that dissatisfaction is nothing compared to how I feel when I occasionally had to ask “why is this API not paginated..?”
So, taking a break from my usual Serverless ramblings, let’s talk about pagination :-)
Unidirectional and Bidirectional Pagination
Generally speaking, I see two common types of paginations:
- simple, unidirectional, paging through a static set of results that are too long or inefficient to return in one go – e.g. list of twitter followers, or list of Google search results
- bidirectional paging through a feed or stream of some sorts where new results can be added after you received the first page of results – e.g. your twitter timeline, or notifications
Avoid leaky abstraction
A common mistake I see is that the paginated API requires the caller to provide the “key” it uses to sort through the results, which creates a leaky abstraction. The caller must then understand the underlying mechanism the service uses to page its results – e.g. by timestamp, or alphabetical order.
DynamoDB’s Query API is a good example of this. To page through the query results, the caller must specify the ExclusiveStartKey in subsequent requests. However, the service does return the LastEvaluatedKey in the response too.
So, in practice, you can almost treat the LastEvaluatedKey as a token, or cursor, which you simply pass on in the next request. Except, it’s not just a token, it’s an actual sort key in the DynamoDB table, and the attribute names already gave the implementation details away anyway.
On its own, this is not a big deal. However, it often has the unfortunately knock-on effect of encouraging application developers to build their application level paginations on top of this implementation detail. Except this time around, they’re not returning the LastEvaluatedKey in the response and the client is now responsible for tracking that piece of information.
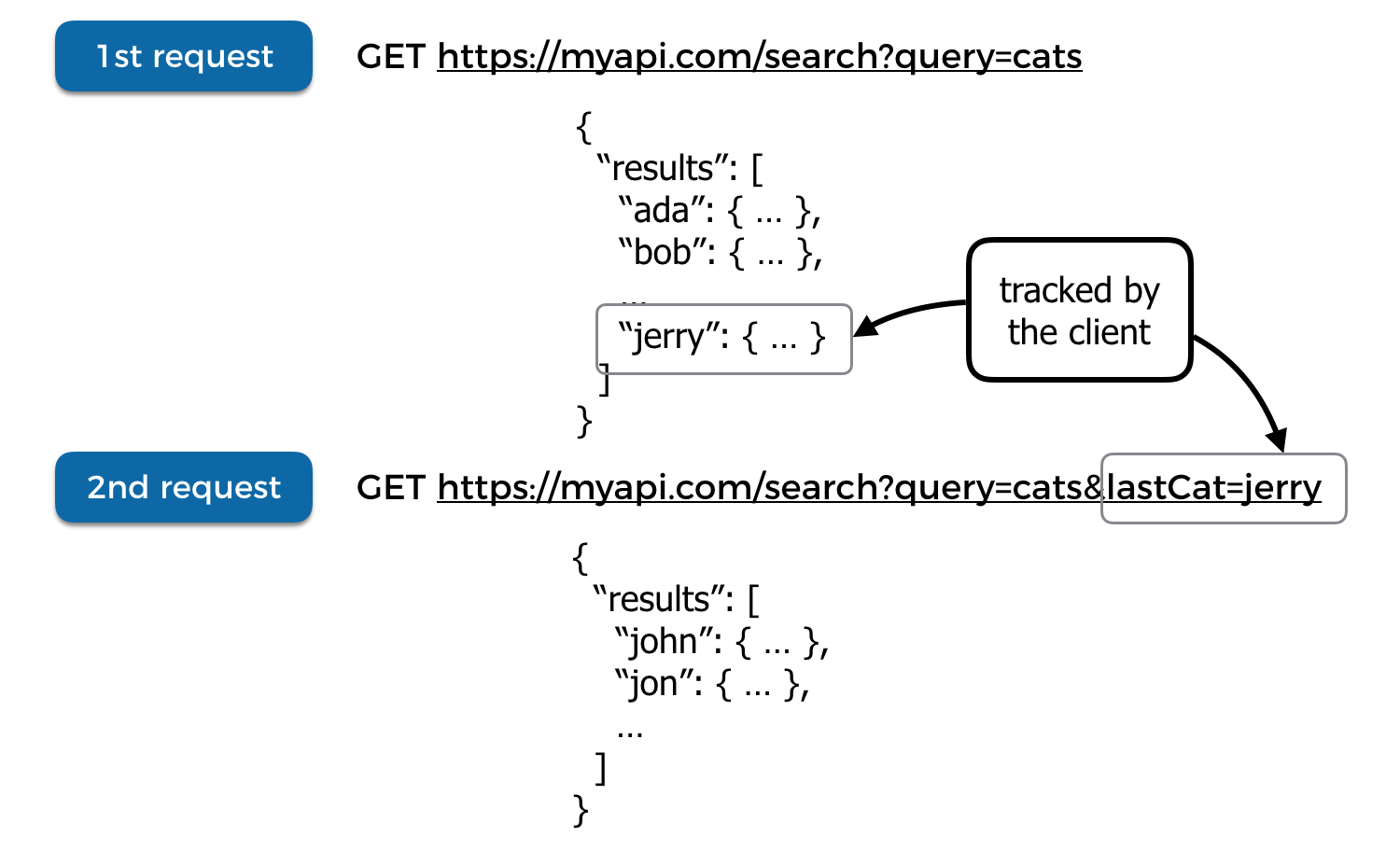
Congratulations, the underlying mechanic your database uses to support pagination has now leaked all the way to your front end!
Make paging intent explicit and consistent
Another common trend I see is that you have to send the same request parameters to the paginated API over and over, for example:
- max no. of results per page
- the direction of pagination (if bidirectional)
- the original query (in DynamoDB’s case, this includes a no. of attributes such as FilterExpression, KeyConditionExpression, ProjectionExpression and IndexName)
I won’t call this one a mistake as it is sometimes by design, but more often than not it strikes me as a consequence of lack of design instead.
In all the paginated APIs I have encountered, the intended behaviour is always to fetch the next set of results for a query, not to start a different query midway through. That just wouldn’t make sense, and you probably can’t even call that pagination, more like navigation! I mean, when was the last time you start a DynamoDB query, and then have to change any of the request parameters midway through paginating through the results?
That said, there are legitimate reasons for changing the direction of pagination from a previously received page. More on this when we discuss bidirectional paging further down the article.
Unidirectional paging with cursor
For unidirectional pagination, my preferred approach is to use a simple cursor. The important detail here is to make the cursor meaningless.
As far as the client is concerned, it’s just a blob the server returns in the response when there are more results to fetch. The client shouldn’t be able to derive any implementation details from it, and the only thing it can afford to do with this cursor is to send it along in the next request.
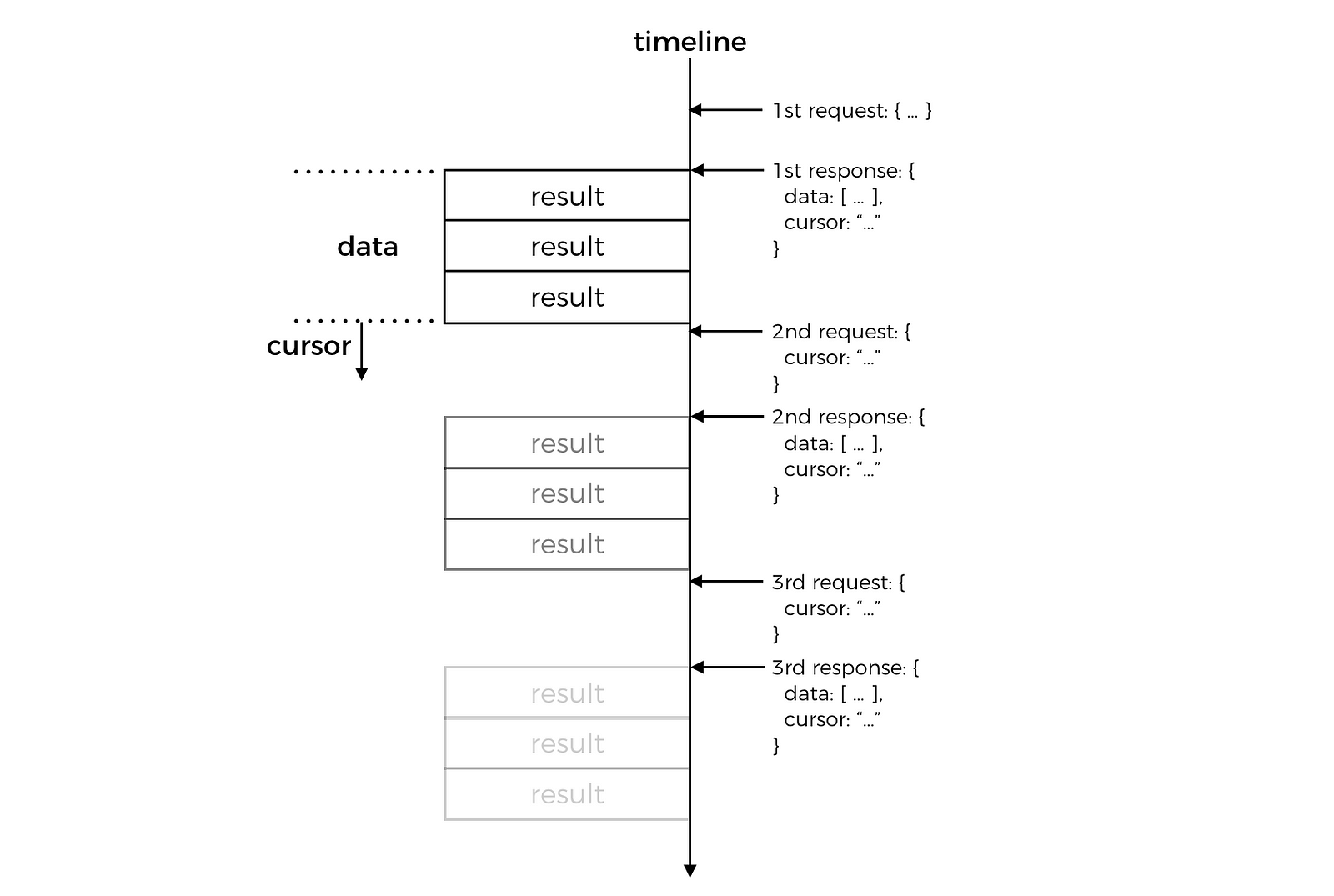
But how does the API know where to start fetching the next page from?
A simple way to do this is:
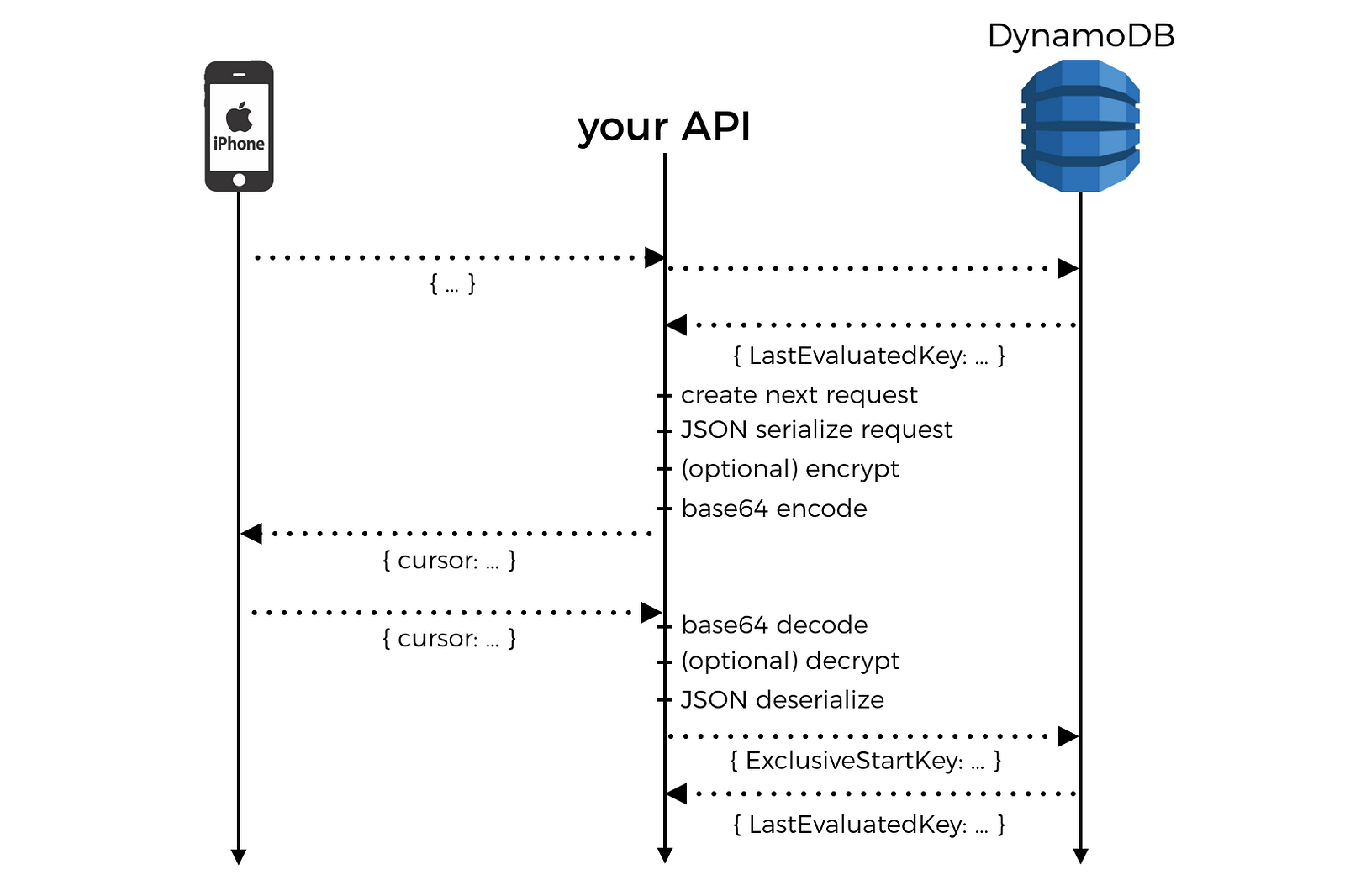
- create a JSON object to capture the data needed to fetch next page – e.g. if you’re using DynamoDB, then this can be the request object for the next page (including the
ExclusiveStartKey) - base64 encode the JSON string
- return the base64 blob as
cursor
When we receive the request to fetch the next page, we can apply the reverse process to get back the request object we created earlier.
Isn’t that gonna leak even more information – e.g. that you’re using DynamoDB, the table name, the schema, etc. – if someone just base64 decode your blob?
Absolutely, which is why you might also choose to encrypt the JSON first. You also don’t have to use the DynamoDB query request as base.
Notice in both fig. 1 and fig. 2 the client only sends the cursor in the subsequent requests?
This is by design.
As I mentioned earlier, the client has already told us the query in the first request, the pagination mechanism should only provide a way for fetching subsequent pages of the results.
Which, to me, means it should not afford any other behaviour (there is that word again, read here to see how the idea of affordance applies to API design) and therefore do not require any other information besides the cursor from the previous response.
This in turn, means we need to capture the original query, or intent, in the cursor so we can construct the corresponding DynamoDB request. Or, we could just capture the actual DynamoDB request in the cursor which seems like a simple, practical solution here.
Bidirectional paging with cursor(s)
With bidirectional paging, you need to be able to page forward in time (when new tweets are added to your timeline) as well as backward (to fetch older tweets). So a simple string cursor would no longer suffice, instead we need 2 cursors, one for each direction, for example…
{
"before": "ThlNjc5MjUwNDMzMA...",
"after": "ADfaU5ODFmMWRiYQ..."
}
Additionally, when paging forward, even when there are no more results right now we still have to return a cursor as new results can be added to the feed later. So we should also include a pair of boolean flags in the response.
{
"before": "ThlNjc5MjUwNDMzMA...",
"hasBefore": true,
"after": "ADfaU5ODFmMWRiYQ...",
"hasAfter": true
}
When the client pages forward in time and receives hasAfter as false then it knows there are no more results available right now. It can therefore stop actively fetch the next page of results, and be more passive and only poll for new results periodically.
Let’s run through a simple example, imagine if you’re fetching the tweets in your timeline where the API would return the latest tweets first.
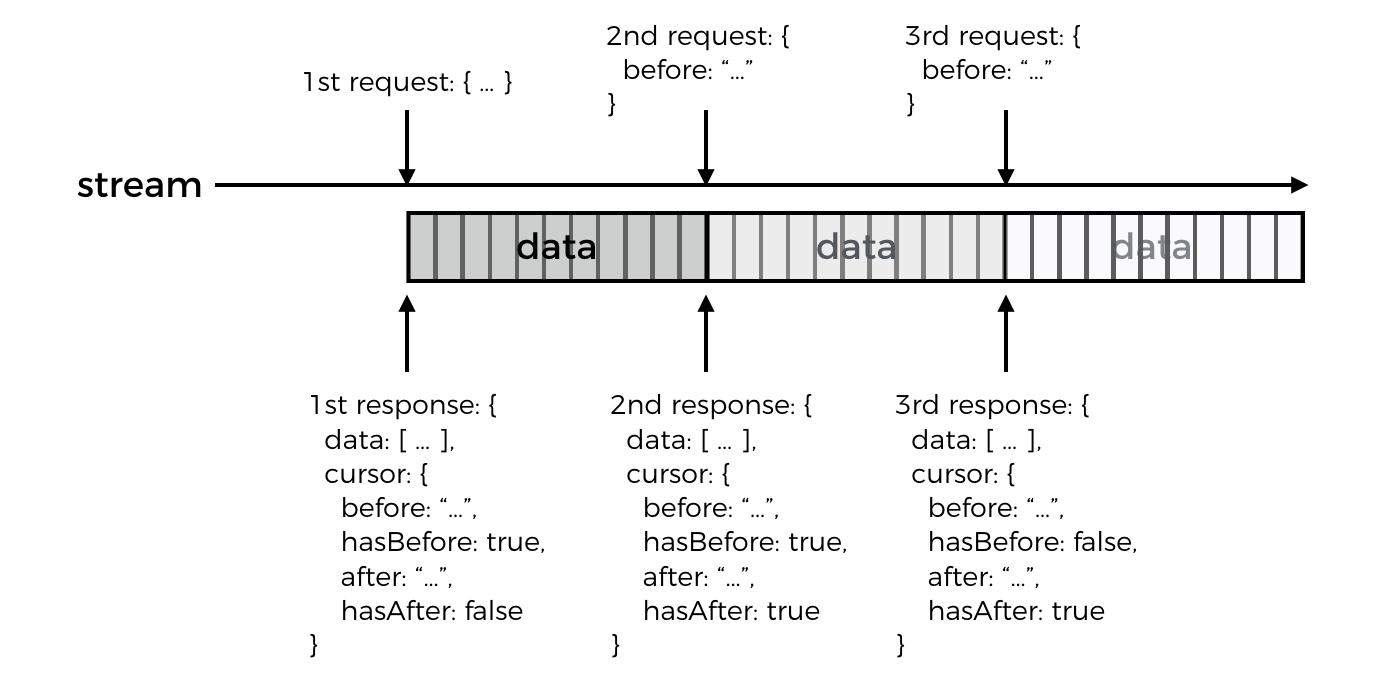
- the client makes a first request
- API responds with a
cursorobject,hasAfterisfalsebecause the API has responded with the latest results, buthasBeforeistrueas there are older results available - the client makes a second request and passes only the
beforecursor in the request, making its intention clear and unambiguous - API responds with another
cursorobject where this time bothhasBeforeandhasAfteraretruegiven that we’re right in the middle of this stream of results - the client makes a third and last request, again passing only the
beforecursor received from the previous response - API responds with a
cursorobject wherehasBeforeisfalsebecause we have now received the oldest result available
Ok, now let’s run through another example, this time we’ll page forward in time instead.
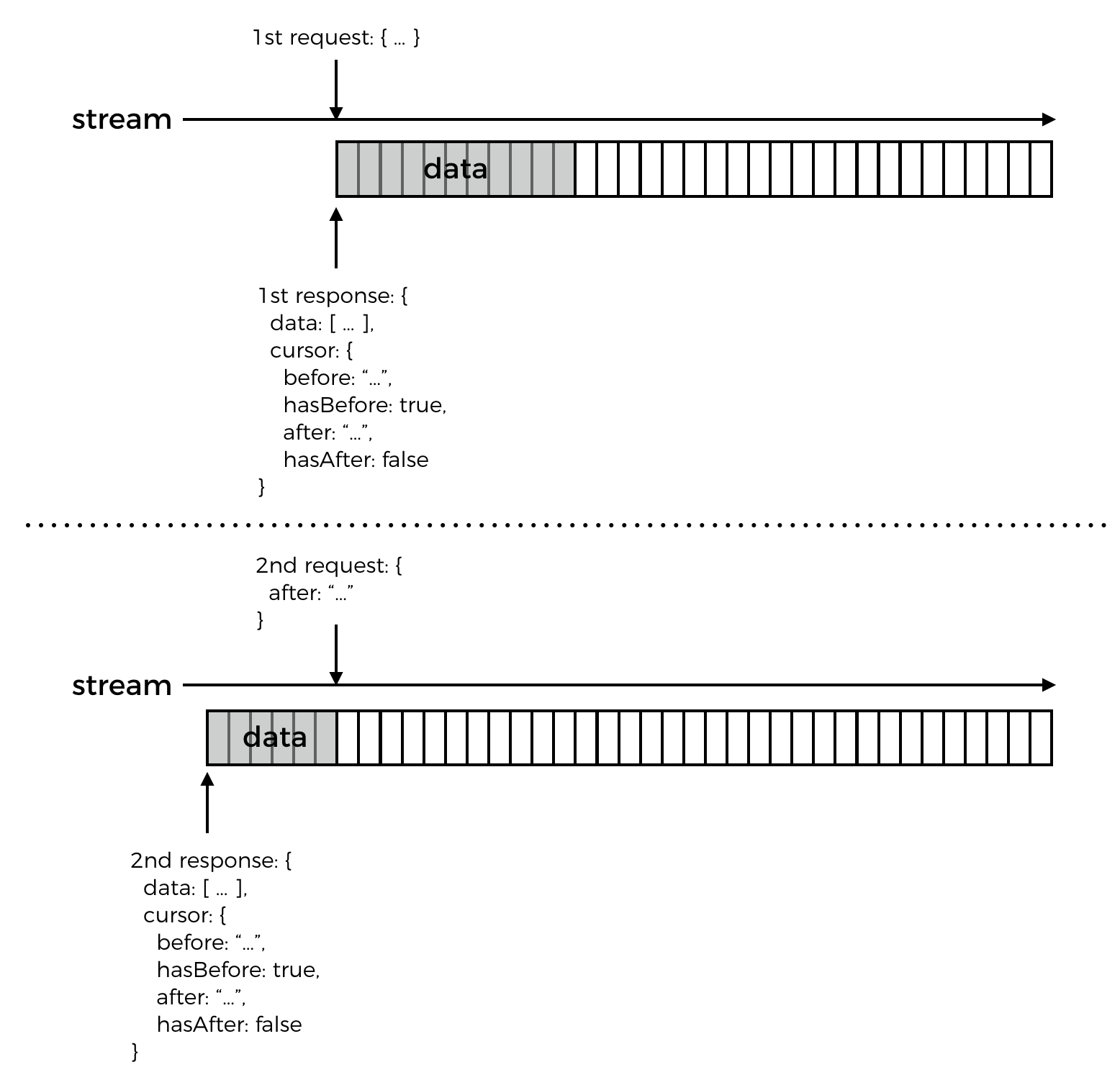
- the client makes a first request
- API responds with a
cursorobject,hasAfterisfalsebecause the API has responded with the latest results, buthasBeforeistrueas there are older results available - some time has passed, and more results have become available
- the client makes a second request, and passes only the
aftercursor in the request, making its intention clear and unambiguous - API responds with only the newer results that the client has not received already, and
cursor.hasAfterisfalseas these are the latest results available at this moment in time; should the client page backward (in time) from this response then it’ll receive the same results as the first response from the API
Now, let’s circle back to what I mentioned earlier regarding the occasional need to change direction midway through pagination.
The reason we need pagination is because it’s often impractical, inefficient and in some cases impossible to return all available results for a query – e.g. at the time of writing Katy Perry has 108M Twitter followers, trying to retrieve all her followers in one request-response cycle would have crashed both the server and the client app.
Besides limiting how much data can be returned in one request-response cycle, we also need to place a upper bound on how much data the client app would cache in order to protect the user experience and prevent the client app from crashing.
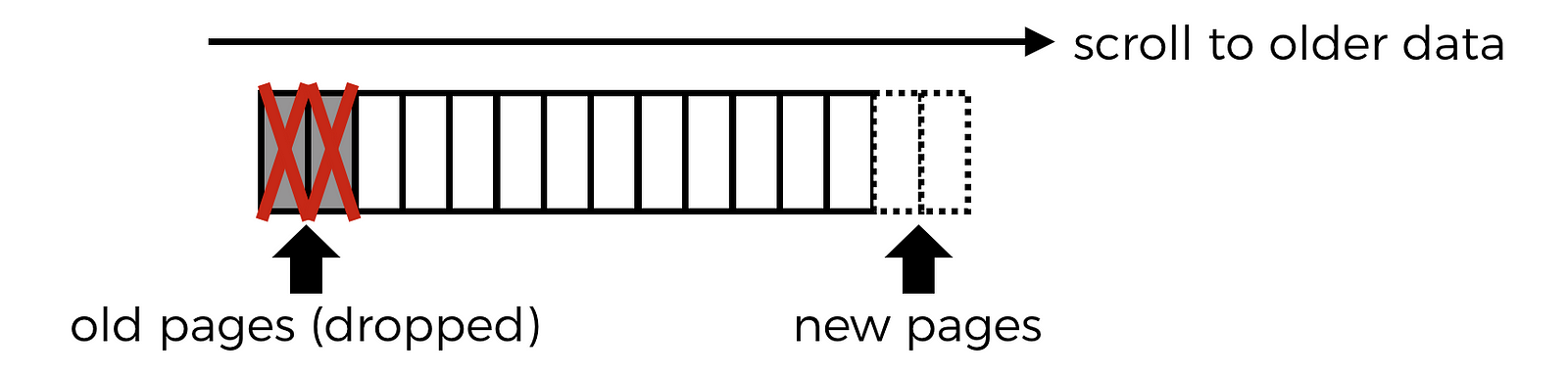
That means, at some point, as the user keeps scrolling through older tweets, the client would need to start dropping data it has already fetched or risk running out of memory. Which means, when the user scrolls back up to see the latest tweets, the client would need to re-fetch pages that had been dropped and hence reversing the original direction of the pagination.
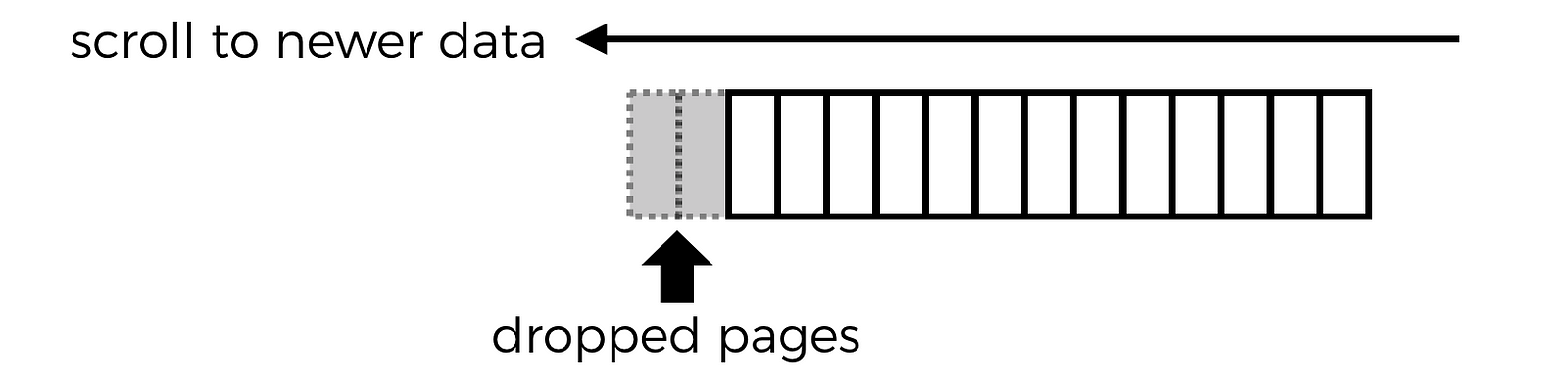
Fortunately, the scheme outlined above is flexible enough and allows you to do just that. Every page of results has an associated cursor that allows you to fetch the next page in either direction. So, in the case where you need to re-fetch a dropped page, it’s as simple as making a paginated request with the after cursor of the latest page you have cached.
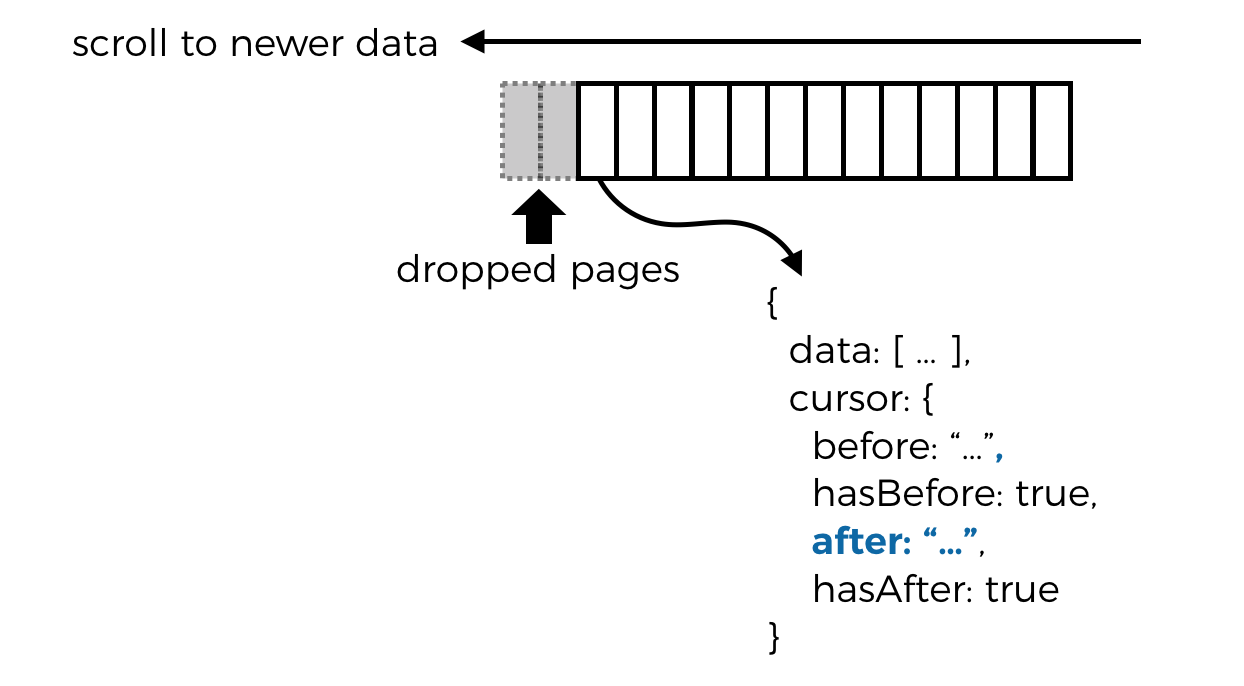
Dealing with “gaps”
Staying with the Twitter example. If you open up the Twitter mobile app after some time, you’ll see the tweets that has already been cached but the app also recognizes that a lot of time has passed that it’s not feasible to paginate from the cached data all the way to the latest.
Instead, the client would fetch the latest tweets with a non-paginated request. As you scroll down, the client can automatically fetch older pages as per fig. 3 and gradually fill in the gap until it joins up with the cached data.
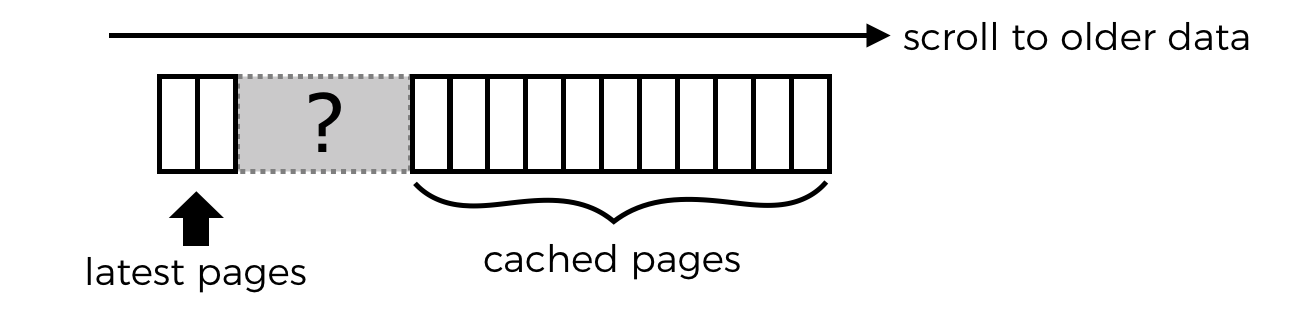
The behaviour of the Twitter mobile app has changed over time, and another tactic I have seen is to place a visual (clickable) marker for the missing tweets in the timeline. This makes it an explicit action by the user to start paging through older tweets to fill in the gap.
So there you have it, a simple and effective way to implement both unidirectional and bidirectional paginated APIs, hope you have found it useful!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.