
Yan Cui
I help clients go faster for less using serverless technologies.

After my post on monolithic functions vs single-purposed functions, a few people asked me about the effect monolithic functions have on cold starts, so I thought I’d share my thoughts here.
The question goes something like this:
Monolithic functions are invoked more frequently so they are less likely to be in cold state, while single-purposed functions that are not being used frequently may always be cold state, don’t you think?
That seems like a fair assumption, but the actual behaviour of cold starts is a more nuanced discussion and can have drastically different results depending on traffic pattern. Check out my other post that goes into this behaviour in more detail.
The effect of consolidation into monolithic functions (on the no. of cold starts experienced) quickly diminishes with load
To simplify things, let’s consider “the number of cold starts you’ll have experienced as you ramp up to X req/s”. Assuming that:
- the ramp up was gradual so there was no massive spikes (which could trigger a lot more cold starts)
- each request’s duration is short, say, 100ms
At a small scale, say, 1 req/s per endpoint, and a total of 10 endpoints (which is 1 monolithic function vs 10 single purposed functions) we’ll have a total of 10 req/s. Given the 100ms execution time, it’s just within what one concurrent function is able to handle.
To reach 1 req/s per endpoint, you will have experienced:
- monolithic: 1 cold start
- single-purposed: 10 cold starts
As the load goes up, to 100 req/s per endpoint, which equates to a total of 1000 req/s. To handle this load you’ll need at least 100 concurrent executions of the monolithic function (100ms per req, so the throughput per concurrent execution is 10 req/s, hence concurrent executions = 1000 / 10 = 100). To reach this level of concurrency, you will have experienced:
- monolithic: 100 cold starts
At this point, 100 req/s per endpoint = 10 concurrent executions for each of the single-purposed functions. To reach that level of concurrency, you will also have experienced:
- single-purposed: 10 concurrent execs * 10 functions = 100 cold starts
So, monolithic functions don’t help you with the no. of cold starts you’ll experience even at a moderate amount of load.
Also, when the load is low, there are simple things you can do to mitigate cold starts by pre-warming your functions (as discussed in the other post). You can even use the serverless-plugin-warmup to do that for you, and it even comes with the option to do a pre-warmup run after a deployment.
However, this practice stops being effective when you have even a moderate amount of concurrency. At which point, monolithic functions would incur just as many cold starts as single-purposed functions.
Consolidating into monolithic functions can increase initialization time, which increases the duration of cold start
By packing more “actions” into one function, we also increase the no. of modules that need to be initialized during the cold start of that function, and are therefore highly to experience longer cold starts as a result (basically, anything outside of the exported handler function is initialized during the Bootstrap runtime phase (see below) of the cold start.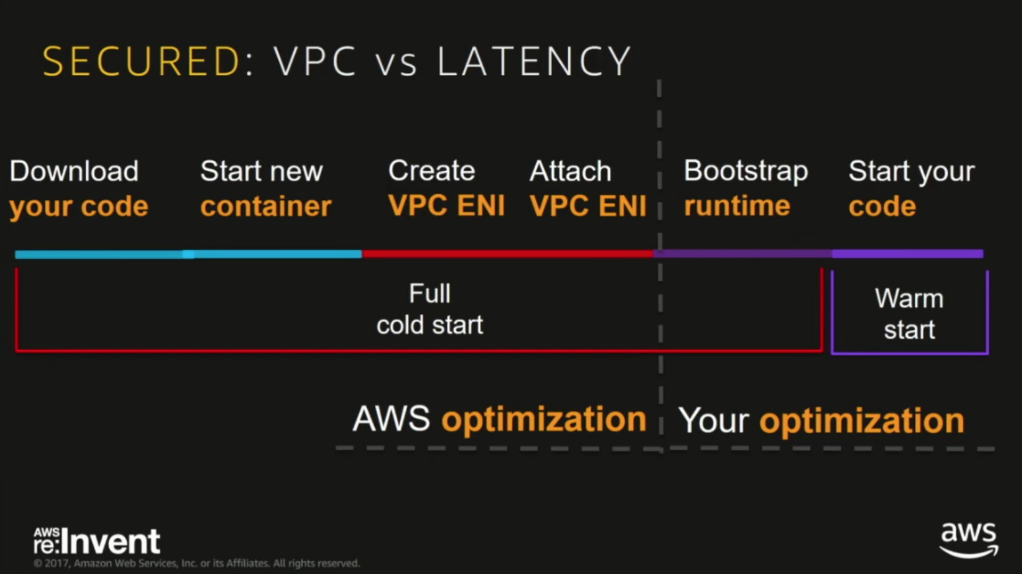
Imagine in the monolithic version of the fictional user-api I used in the previous post to illustrate the point, our handler module would need to require all the dependencies used by all the endpoints.
const depA = require('lodash');
const depB = require('facebook-node-sdk');
const depC = require('aws-sdk');
...
Whereas in the single-purposed version of the user-api, only the get-user-by-facebook-id endpoint’s handler function would need to incur the extra overhead of initializing the facebook-node-sdk dependency during cold start.
You also have to factor in any other modules in the same project, and their dependencies, and any code that will be run during those modules’ initialization, and so on.
Wrong place to optimize cold start
So, contrary to one’s intuition, monolithic functions don’t offer any benefit towards cold starts outside what basic prewarming can achieve already, and can quite likely extend the duration of cold starts.
Since cold start affects you wildly differently depending on language, memory and how much initialization you’re doing in your code. I’ll argue that, if cold starts is a concern for you, then you’re far better off switching to another language (i.e. Go, Node.js or Python) and to invest effort into optimizing your code so it suffers shorter cold starts.
Also, keep in mind that this is something that AWS and other providers are actively working on and I suspect the situation will be vastly improved in the future by the platform.
All and all, I think changing the deployment units (one big function vs many small functions) is not the right way to address cold starts.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.