
Yan Cui
I help clients go faster for less using serverless technologies.

A funny moment (at 38:50) happened during Tim Bray’s session (SRV306) at re:invent 2017, when he asked the audience if we should have many simple, single-purposed functions, or fewer monolithic functions, and the room was pretty much split in half.
Having been brought up on the SOLID principles, and especially the single responsibility principle (SRP), this was a moment that challenged my belief that following the SRP in the serverless world is a no-brainer.
That prompted this closer examination of the arguments from both sides.
Full disclosure, I am biased in this debate. If you find flaws in my thinking, or simply disagree with my views, please point them out in the comments.
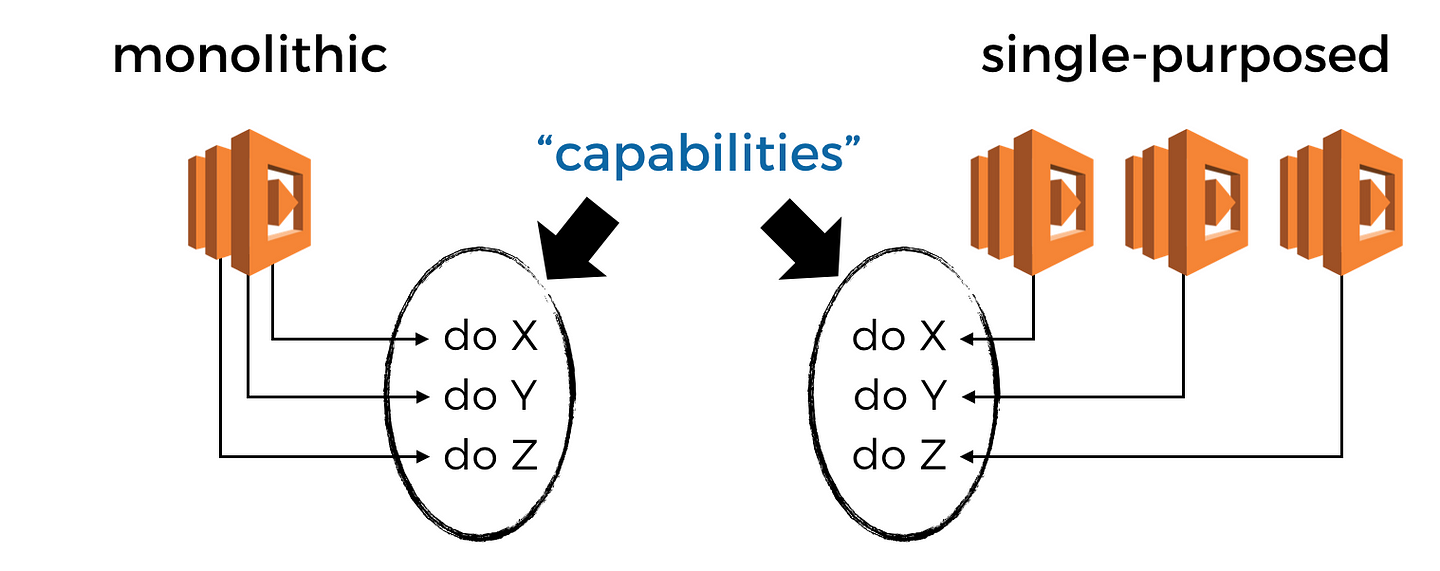
What is a monolithic function?
By “monolithic functions”, I meant functions that have internal branching logic based on the invocation event and can do one of several things.
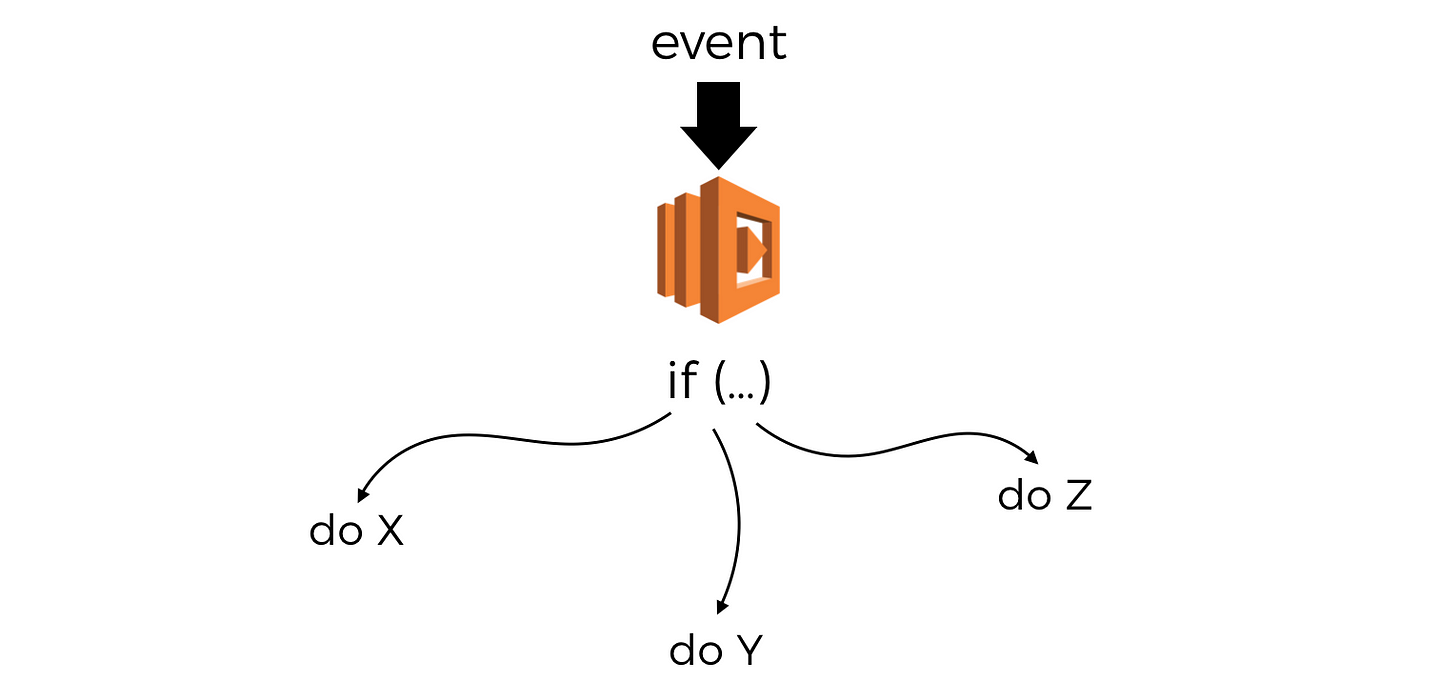
For example, you can have one function handle several HTTP endpoints and methods and perform a different actions based on path and method.
module.exports.handler = (event, context, cb) => {
const path = event.path;
const method = event.httpMethod;
if (path === '/user' && method === 'GET') {
.. // get user
} else if (path === '/user' && method === 'DELETE') {
.. // delete user
} else if (path === '/user' && method === 'POST') {
.. // create user
} else if ... // other endpoints & methods
}
What is the real problem?
One can’t rationally reason about and compare solutions without first understanding the problem and what qualities are most desired in a solution.
And when I hear complaints such as:
having so many functions is hard to manage
I immediately wonder what does manage entail? Is it to find specific functions you’re looking for? Is it to discover what functions you have? Does this become a problem when you have 10 functions or 100 functions? Or does it become a problem only when you have more developers working on them than you’re able to keep track of?
Drawing from my own experiences, the problem we’re dealing with has less to do with what functions we have, but rather, what features and capabilities do we possess through these functions.
After all, a Lambda function, like a Docker container, or an EC2 server, is just a conduit to deliver some business feature or capability you require.
You wouldn’t ask “Do we have a get-user-by-facebook-id function?” since you will need to know what the function is called without even knowing if the capability exists and if it’s captured by a Lambda function. Instead, you would probably ask instead “Do we have a Lambda function that can find a user based on his/her facebook ID?”.
So the real problem is that, given that we have a complex system that consists of many features and capabilities, that is maintained by many teams of developers, how do we organize these features and capabilities into Lambda functions so that it’s optimised towards..
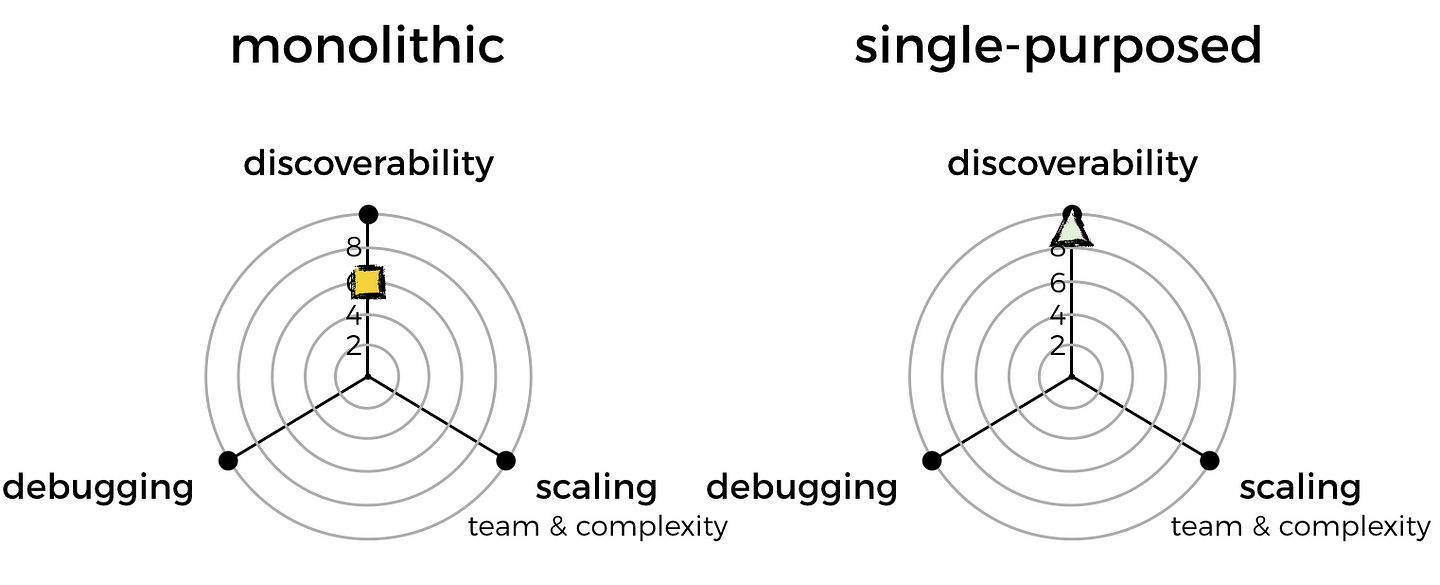
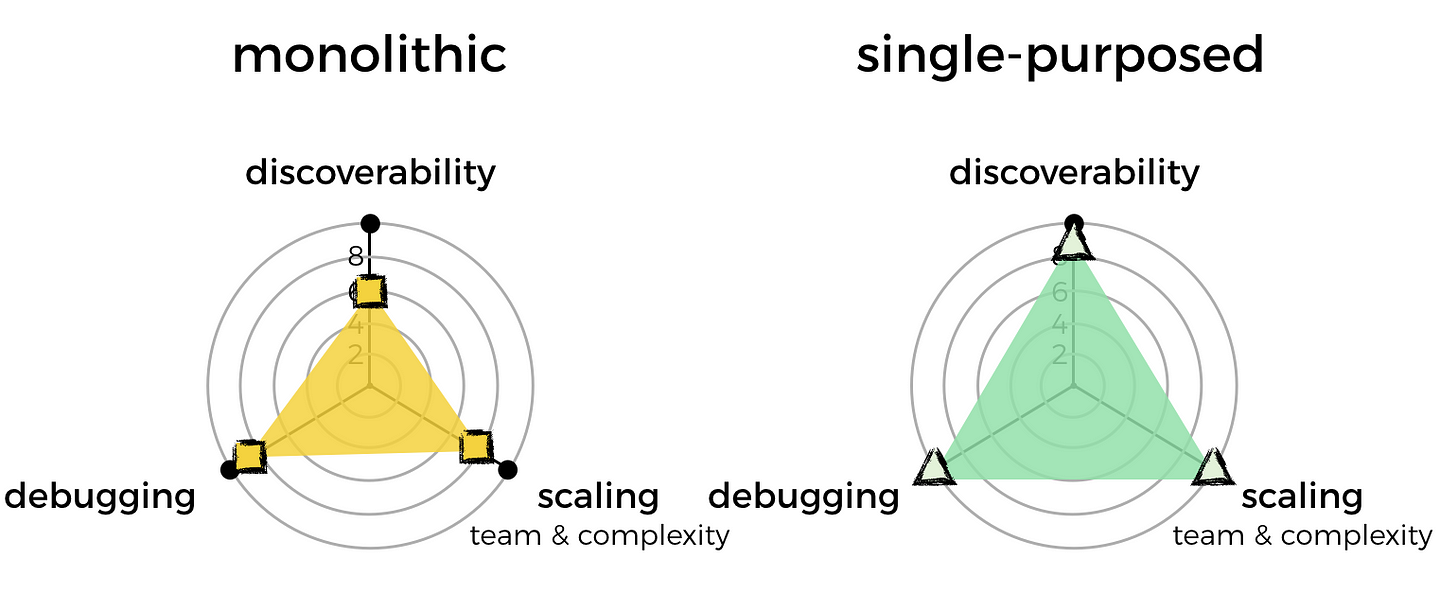
- discoverability: how do I find out what features and capabilities exist in our system already, and through which functions?
- debugging: how do I quickly identify and locate the code I need to look at to debug a problem? e.g. there are errors in system X’s logs, where do I find the relevant code to start debugging the system?
- scaling the team: how do I minimise friction and allow me to grow the engineering team?
These are the qualities that are most important to me. With this knowledge, I can compare the 2 approaches and see which is best suited for me.
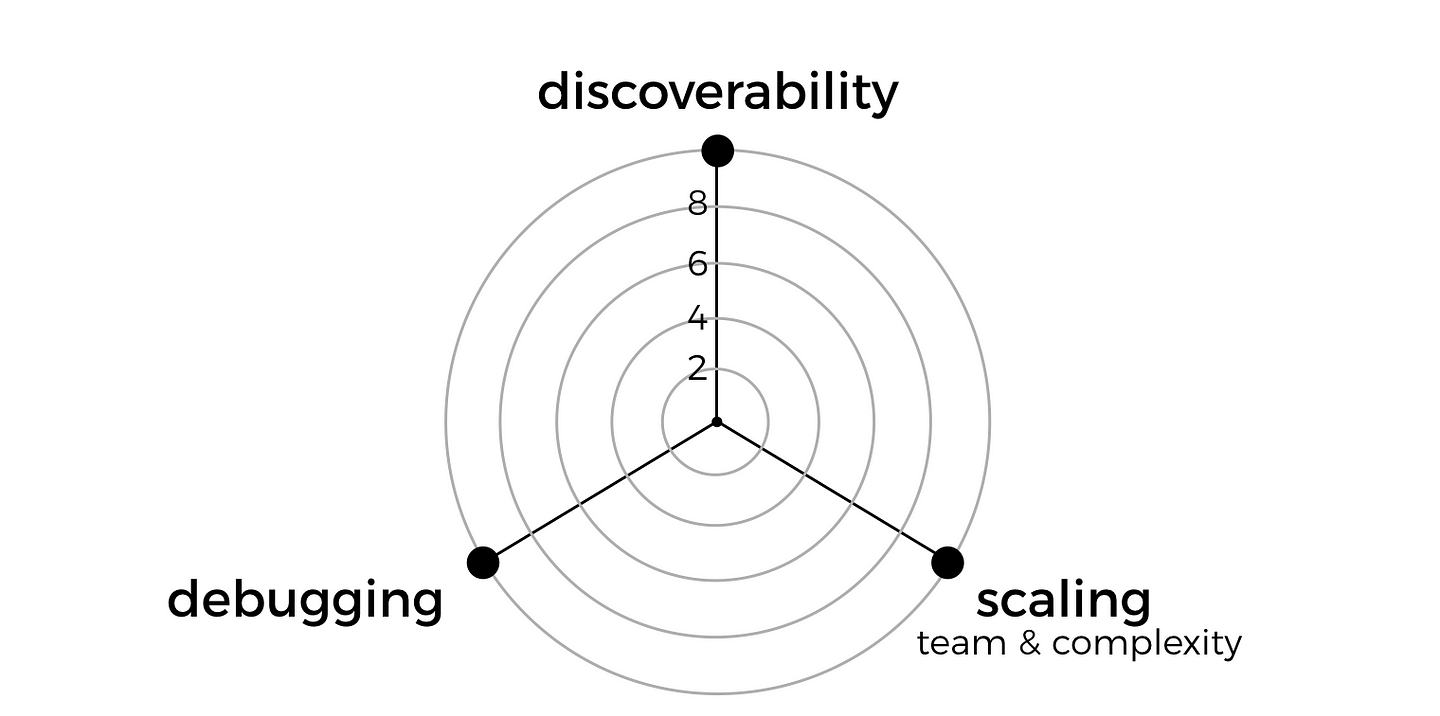
You might care about different qualities, for example, you might not care about scaling the team, but you really worry about the cost for running your serverless architecture. Whatever it might be, I think it’s always helpful to make those design goals explicit, and make sure they’re shared with and understood (maybe even agreed upon!) by your team.
Discoverability
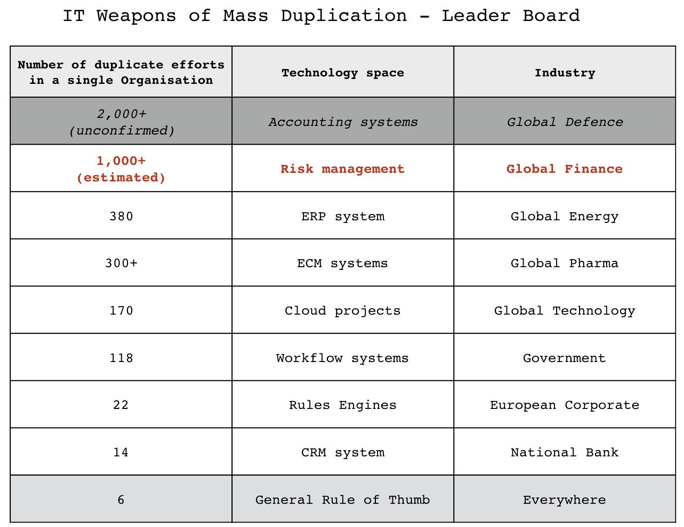
Discoverability is by no means a new problem, according to Simon Wardley, it’s rather rampant in both government as well as the private sector, with most organisations lacking a systematic way for teams to share and discover each other’s work.
The worst example of duplication I've found in a Gov system is 118 workflow systems doing the same thing. In the private sector, I have a finance company with over 1,000 risk mgmt systems doing the same thing. Not convinced that State is the epitome of clueless. https://t.co/lYPO8ySp6R
— Simon Wardley (@swardley) November 24, 2017
As mentioned earlier, what’s important here is the ability to find out what capabilities are available through your functions, rather than what functions are there.
An argument I often hear for monolithic functions, is that it reduces the no. of functions, which makes them easier to manage.
On the surface, this seems to make sense. But the more I think about it the more it strikes me that the no. of function would only be an impediment to our ability to manage our Lambda functions IF we try to manage them by hand rather than using the tools available to us already.
After all, if we are able to locate books by their content (“find me books on the subject of X”) in a huge physical space with 10s of thousands of books, how can we struggle to find Lambda functions when there are so many tools available to us?

With a simple naming convention, like the one that the Serverless framework enforces, we can quickly find related functions by prefix.
For example, if I want to find all the functions that are part of our user API, I can do that by searching for user-api.
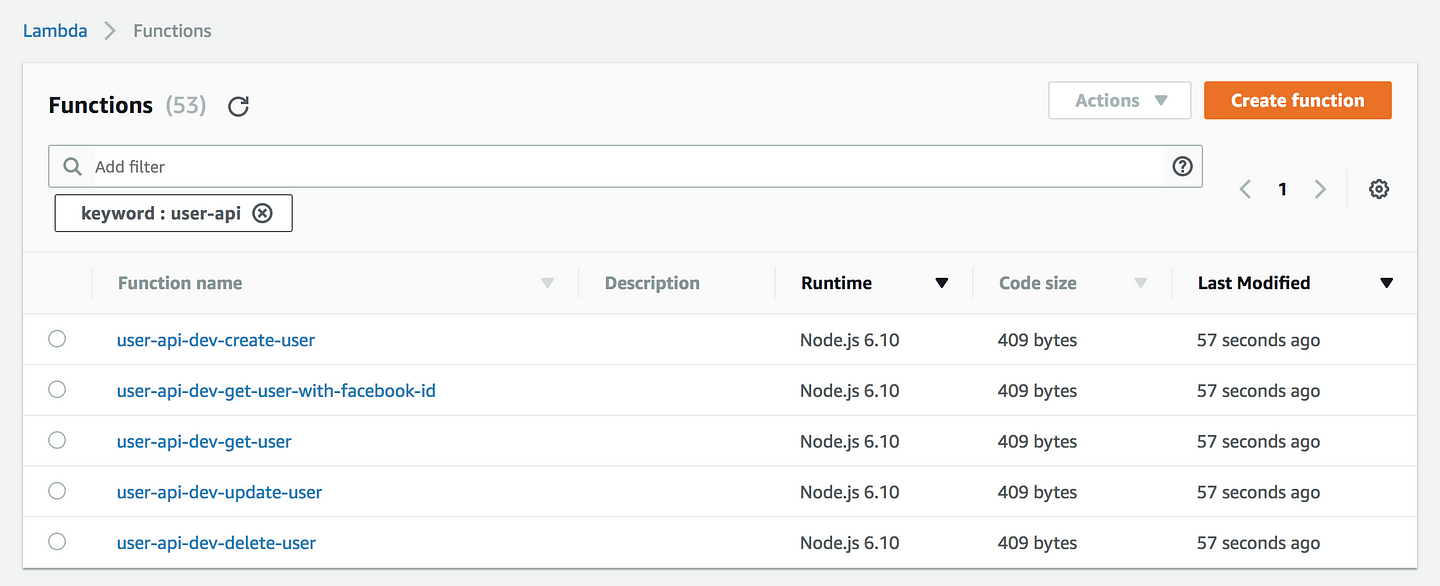
With tagging, we can also catalogue functions across multiple dimensions, such as environment, feature name, what type of event source, the name of the author, and so on.
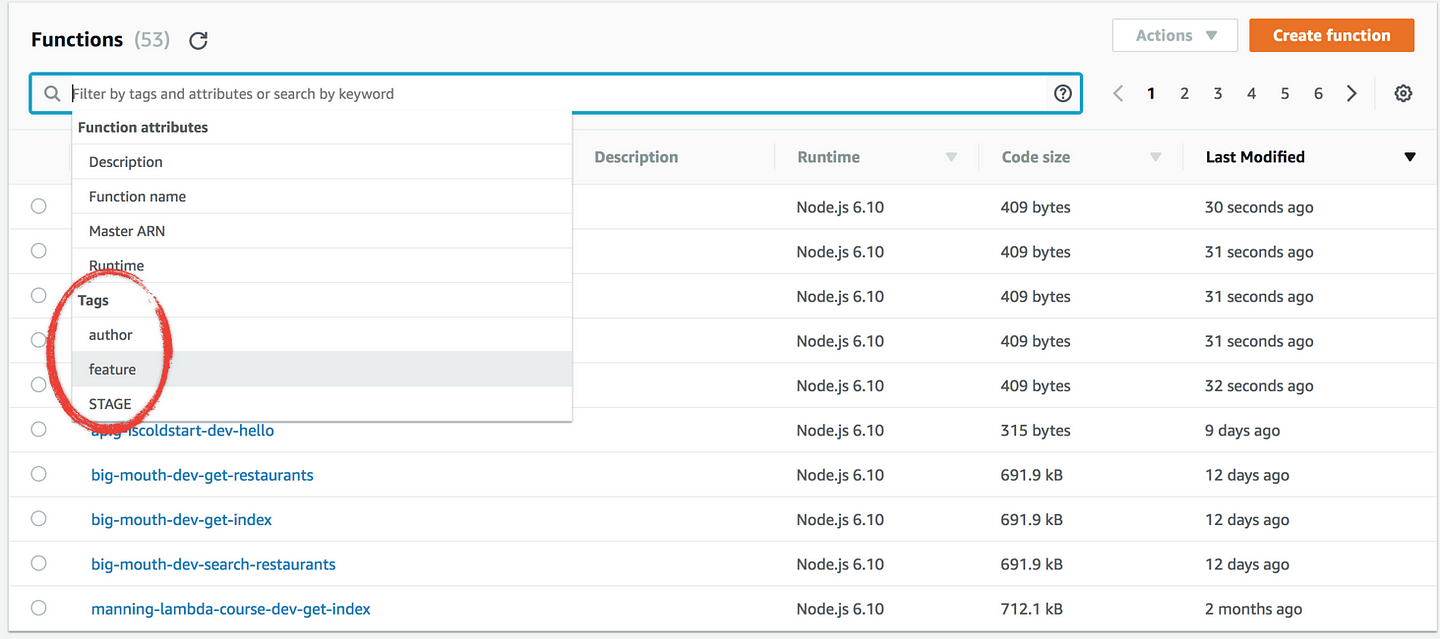
By default, the Serverless framework adds the STAGE tag to all of your functions. You can also add your own tags as well, see documentation on how to add tags. The Lambda management console also gives you a handy dropdown list of the available values when you try to search by a tag.

If you have a rough idea of what you’re looking for, then the no. of functions is not going to be an impediment to your ability to discover what’s there.
On the other hand, the capabilities of the user-api is immediately obvious with single-purposed functions, where I can see from the relevant functions that I have the basic CRUD capabilities because there are corresponding functions for each.
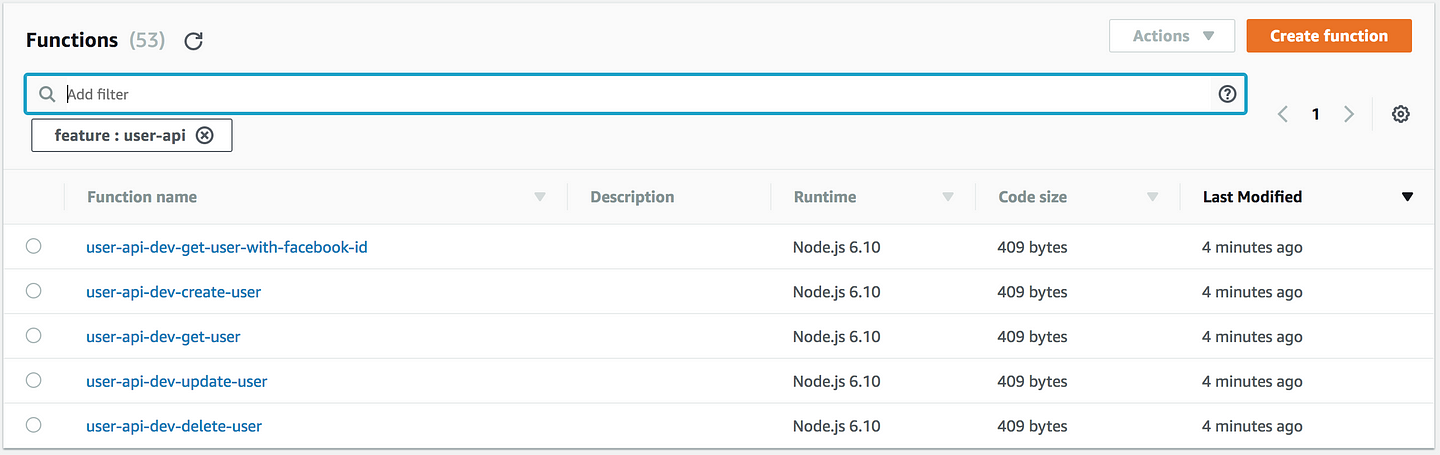
With a monolithic function, however, it’s not immediately obvious, and I’ll have to either look at the code myself, or have to consult with the author of the function, which for me, makes for pretty poor discoverability.

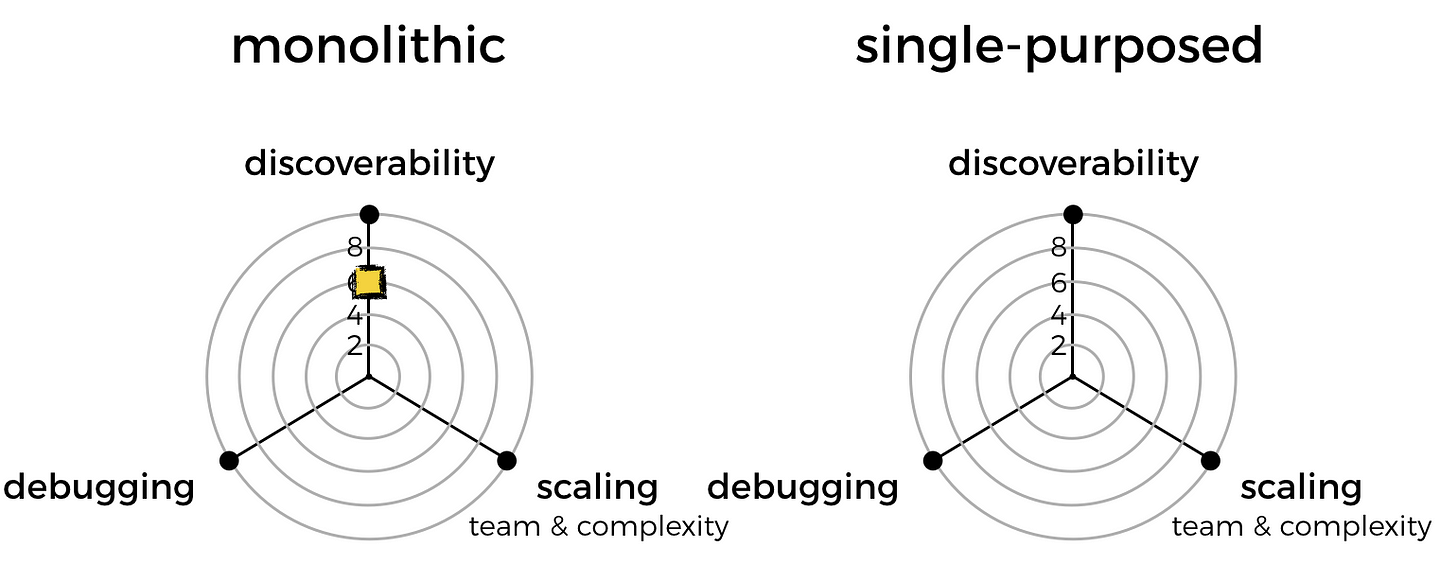
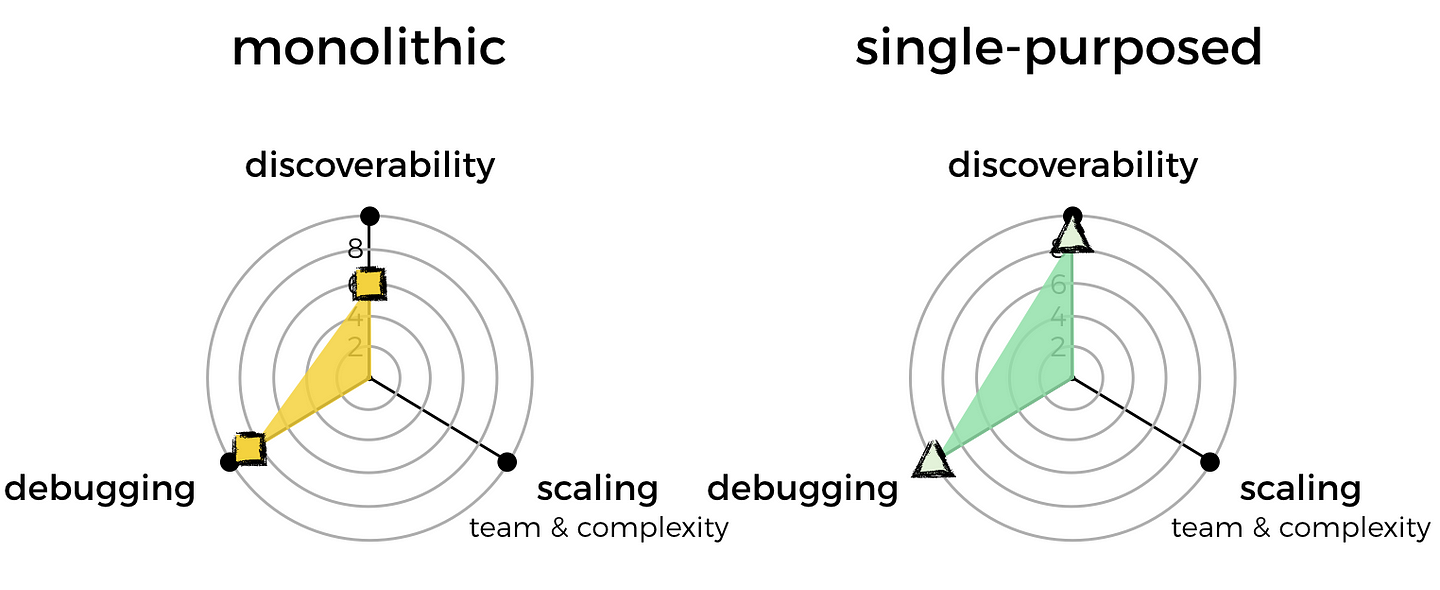
Because of this, I will mark the monolithic approach down on discoverability.
Having more functions though, means there are more pages for you to scroll through if you just want to explore what functions are there rather than looking for anything specific.
Although, in my experience, with all the functions nicely clustered together by name prefix thanks to the naming convention the Serverless framework enforces, it’s actually quite nice to see what each group of functions can do rather than having to guess what goes on inside a monolithic function.
But, I guess it can be a pain to scroll through everything when you have thousands of functions. So, I’m going to mark single-purposed functions down only slightly for that. I think at that level of complexity, even if you reduce the no. of functions by packing more capabilities into each function, you will still suffer more from not being able to know the true capabilities of those monolithic functions at a glance.
Debugging
In terms of debugging, the relevant question here is whether or not having fewer functions makes it easier to quickly identify and locate the code you need to look at to debug a problem.
Based on my experience, the trail of breadcrumbs that leads you from, say, an HTTP error or an error stack trace in the logs, to the relevant function and then the repo is the same regardless whether the function does one thing or many different things.
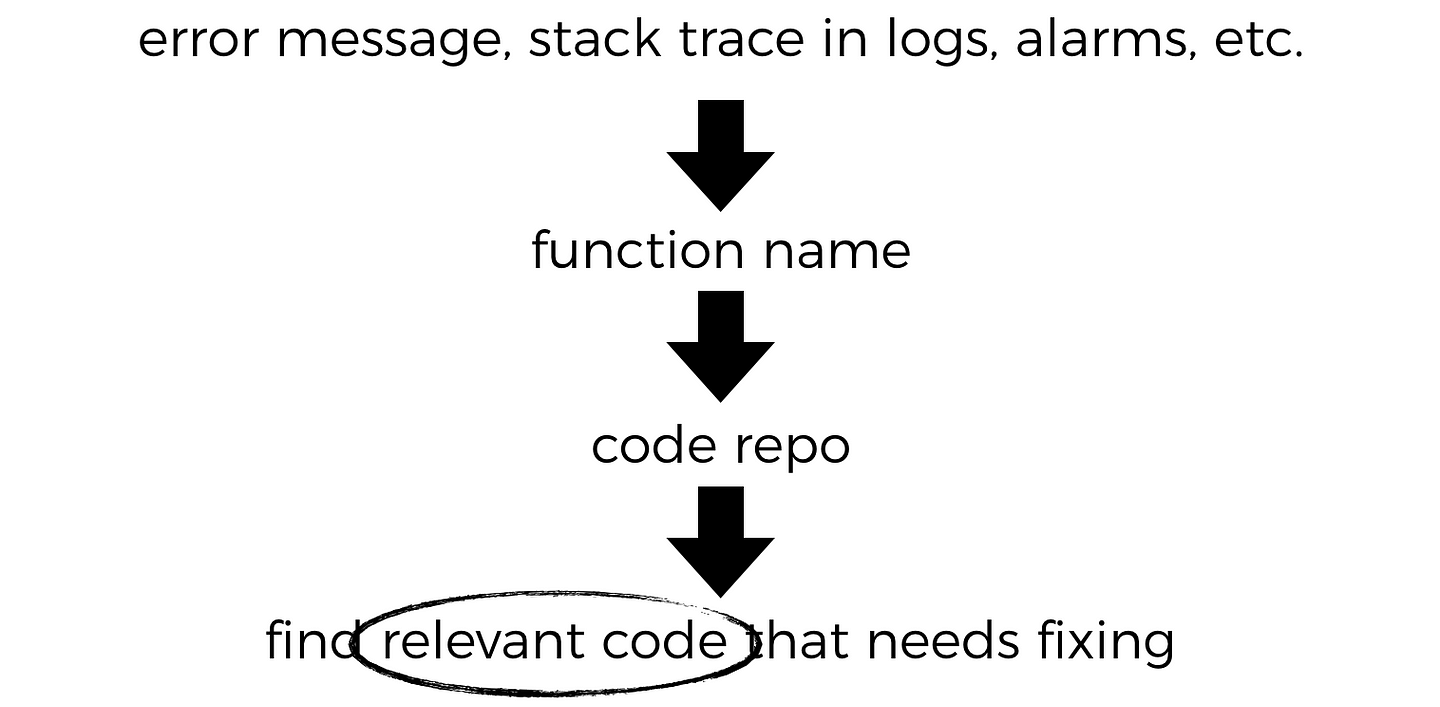
What will be different, is how you’d find the relevant code inside the repo for the problems you’re investigating.
A monolithic function that has more branching and in general does more things, would understandably take more cognitive effort to comprehend and follow through to the code that is relevant to the problem at hand.
For that, I’ll mark monolithic functions down slightly as well.
Scaling
One of early arguments that got thrown around for microservices is that it makes scaling easier, but that’s just not the case – if you know how to scale a system, then you can scale a monolith just as easily as you can scale a microservice.
I say that as someone who has built monolithic backend systems for games that had a million daily active users. Supercell, the parent company for my current employer, and creator of top grossing games like Clash of Clans and Clash Royale, have well over 100 million daily active users on their games and their backend systems for these games are all monoliths as well.
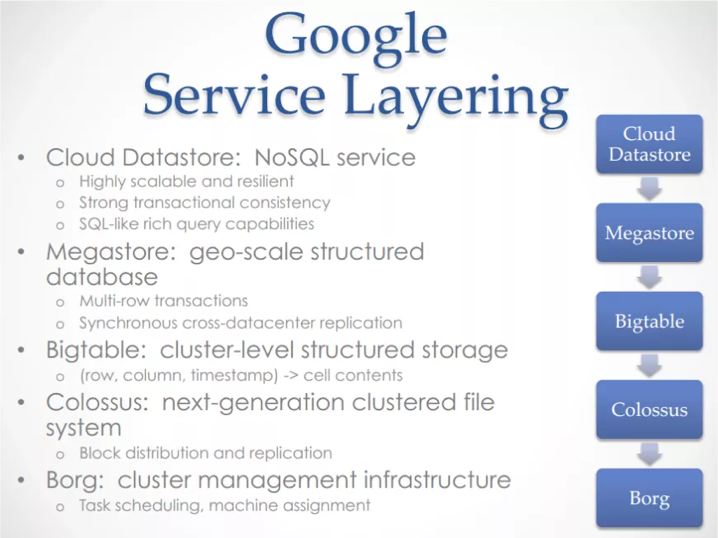
Instead, what we have learnt from tech giants like the Amazon, and Netflix, and Google of this world, is that a service oriented style of architecture makes it easier to scale in a different dimension – our engineering team.
This style of architecture allows us to create boundaries within our system, around features and capabilities. In doing so it also allows our engineering teams to scale the complexity of what they build as they can more easily build on top of the work that others have created before them.
Take Google’s Cloud Datastore for example, the engineers working on that service were able to produce a highly sophisticated service by building on top of many layers of services, each provide a power layer of abstractions.
These service boundaries are what gives us that greater division of labour, which allows more engineers to work on the system by giving them areas where they can work in relative isolation. This way, they don’t constantly trip over each other with merge conflicts, and integration problems, and so on.
Michael Nygard also wrote a nice article recently that explains this benefit of boundaries and isolation in terms of how it helps to reduce the overhead of sharing mental models.
“if you have a high coherence penalty and too many people, then the team as a whole moves slower… It’s about reducing the overhead of sharing mental models.”
– Michael Nygard
Having lots of single-purposed functions is perhaps the pinnacle of that division of task, and something you lose a little when you move to monolithic functions. Although in practice, you probably won’t end up having so many developers working on the same project that you feel the pain, unless you really pack them in with those monolithic functions!
Also, restricting a function to doing just one thing also helps limit how complex a function can become. To make something more complex you would instead compose these simple functions together via other means, such as with AWS Step Functions.
Once again, I’m going to mark monolithic functions down for losing some of that division of labour, and raising the complexity ceiling of a function.
Conclusion
As you can see, based on the criteria that are important to me, having many single-purposed functions is clearly the better way to go.
Like everyone else, I come preloaded with a set of predispositions and biases formed from my experiences, which quite likely do not reflect yours. I’m not asking you to agree with me, but to simply appreciate the process of working out the things that are important to you and your organization, and how to go about finding the right approach for you.
However, if you disagree with my line of thinking and the arguments I put forward for my selection criteria – discoverability, debugging, and scaling the team & complexity of the system – then please let me know via comments.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Hi Yan,
Nice summary of the trade-offs between monoliths and services.
I would definitely agree with your point about scaling engineering. Very large projects with more than 1000 developers merging regularly to master on a single repo are difficult to work with. Issues like build time become major. We can mitigate this with clever build systems and dependency management, but the write-compile-test loop is much slower than for a properly segregated system. The end result is much less playful experimentation, which is so important for perfecting code.
At least for JAVA AWS it would be nice to group several functions into a single jar file. Every lambda function should have its own handler thus calling its own method of the shared jar. If AWS would be aware that some handlers share the same jar file it would have advantages for coldstart-times and for costs.
Seldom-used systems or seldom-used functions would cold-start only one instance of a jar (as long as they are not called concurrently) and execute their own methods in the same instance. It would not be necessary anymore to start the same jar for each lambda execution and hence saving resources and costs.
Hi Mike,
The convention with JVM functions, at least with both Serverless and the SAM framework, IS to deploy a shared jar, but remember, that shared JAR is just part of the deployment artifact (which also includes cloudformation template and so on). In fact, one of the ways to cut down on the cold start time itself, is to avoid the shared JAR altogether, so that you ship a leaner, smaller JAR for each function, which would help cut down on the cold start time (but not the no. of times you see a cold start).
At runtime though, each “instance” of a Lambda function would load this JAR into its own instance of the JVM when it cold starts, and each “instance” of this Lambda function is walled off so they can’t just reach into each other’s memory, and there’s no work-stealing etc.
AWS and other providers are looking at cold starts, and there are some things they can do, e.g. predictive warming (just-ahead-of-time rather than JIT as it does now) or pre-warming a replacement instance when garbage collecting an old instance (after it’s been active for some time, or during a deployment).